Download as PDF, PPTX


















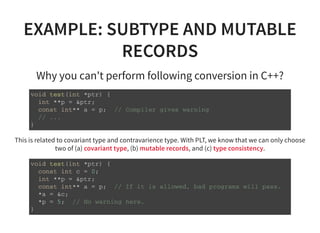





![ALIAS ANALYSIS
Determine whether two pointers can refers to the same
object or not.
v o i d m o v e ( c h a r * d s t , c o n s t c h a r * s r c , i n t n ) {
f o r ( i n t i = 0 ; i < n ; + + i ) {
d s t [ i ] = s r c [ i ] ;
}
}
i n t s u m ( i n t * p t r , c o n s t i n t * v a l , i n t n ) {
i n t r e s = 0 ;
f o r ( i n t i = 0 ; i < n ; + + i ) {
r e s + = * v a l ;
* p t r + + = 1 0 ;
}
r e t u r n r e s ;
}](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-24-320.jpg)







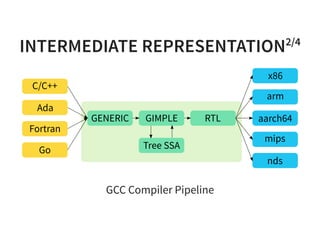
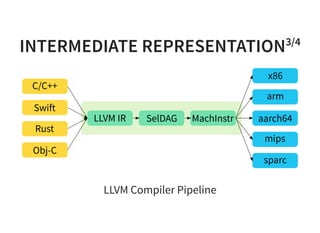


![CONTROL FLOW GRAPH2/3
/ / y = a * x + b ;
v o i d m a t m u l ( d o u b l e * r e s t r i c t y ,
u n s i g n e d l o n g m , u n s i g n e d l o n g n ,
c o n s t d o u b l e * r e s t r i c t a ,
c o n s t d o u b l e * r e s t r i c t x ,
c o n s t d o u b l e * r e s t r i c t b ) {
f o r ( u n s i g n e d l o n g r = 0 ; r < m ; + + r ) {
d o u b l e t = b [ r ] ;
f o r ( u n s i g n e d l o n g i = 0 ; i < n ; + + i ) {
t + = a [ r * n + i ] * x [ i ] ;
}
y [ r ] = t ;
}
}
Input source program](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-36-320.jpg)
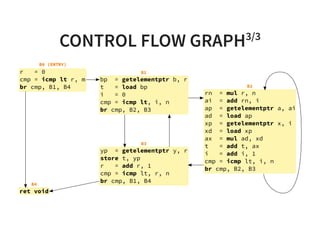
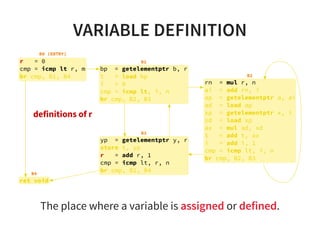
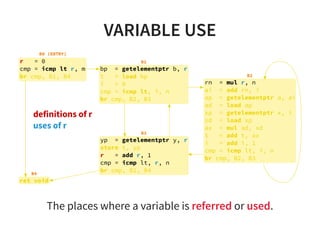
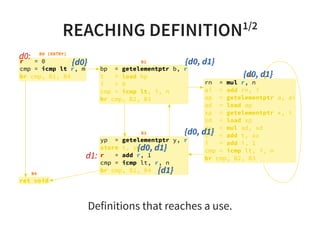
![REACHING DEFINITION2/2
Constant propagation is a good example to show the
usefulness of reaching definition.
v o i d t e s t ( i n t c o n d ) {
i n t a = 1 ; / / d 0
i n t b = 2 ; / / d 1
i f ( c o n d ) {
c = 3 ; / / d 2
} e l s e {
/ / R e a c h D e f [ a ] = { d 0 }
/ / R e a c h D e f [ b ] = { d 1 }
c = a + b ; / / d 3
}
/ / R e a c h D e f [ c ] = { d 2 , d 3 }
u s e ( c ) ;
}](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-41-320.jpg)

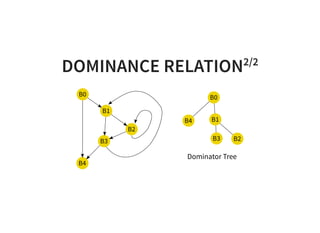
![DOMINANCE FRONTIER
A basic block t is a dominance frontier of a basic block s, if
one of predecessor of t is dominated by s but t is not strictly
dominated by s.
B0
B1 B2
B3
B6
B4
B5
DF[B2] = {B3, B5}
DF[B4] = {B4}
DF[B1] = {B3, B5}](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-44-320.jpg)








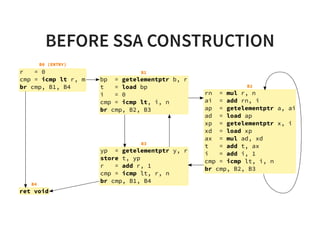
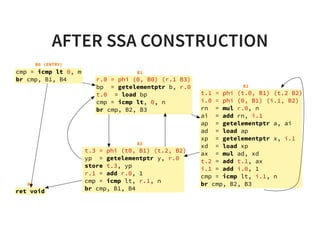


![CONSTANT PROPAGATION2/3
Why do we need constant propagation?
s t r u c t q u e u e * c r e a t e _ q u e u e ( ) {
r e t u r n ( s t r u c t q u e u e * ) m a l l o c ( s i z e o f ( s t r u c t q u e u e * ) * 1 6 ) ;
}
i n t p r o c e s s _ d a t a ( i n t a , i n t b , i n t c ) {
i n t k [ ] = { 0 x 1 3 , 0 x 1 7 , 0 x 1 9 } ;
i f ( D E B U G ) {
v e r i f y _ d a t a ( k , d a t a ) ;
}
r e t u r n ( a * k [ 1 ] * k [ 2 ] + b * k [ 0 ] * k [ 2 ] + c * k [ 0 ] * k [ 1 ] ) ;
}](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-57-320.jpg)

![GLOBAL VALUE NUMBERING1/2
Global value numbering tries to give numbers to the
computed expression and maps the newly visited expression
to the visited ones.
a = c * d ; / / [ ( * , c , d ) - > a ]
e = c ; / / [ ( * , c , d ) - > a ]
f = e * d ; / / q u e r y : i s ( * , c , d ) a v a i l a b l e ?
u s e ( a , e , f ) ;
a = c * d ;
u s e ( a , c , a ) ;](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-59-320.jpg)
![GLOBAL VALUE NUMBERING2/2
Traverse the basic blocks in depth-first order on dominator
tree.
Maintain a stack of hash table. Once we have returned from
a child node on the dominator tree, then we have to pop the
stack top.
Visit the instructions in the basic block with tᅠ=ᅠopᅠa,ᅠb
form and compute the hash for (op, a, b).
If (op, a, b) is already in the hash table, then change
tᅠ=ᅠopᅠa,ᅠb with tᅠ=ᅠhash_tab[(op,ᅠa,ᅠb)]
Otherwise, insert (op, a, b) -> t to the hash table.](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-60-320.jpg)




![DEAD CODE ELIMINATION5/6
Dead code a er code specialization
v o i d m a t m u l ( d o u b l e * r e s t r i c t y , u n s i g n e d l o n g m , u n s i g n e d l o n g n ,
c o n s t d o u b l e * r e s t r i c t a ,
c o n s t d o u b l e * r e s t r i c t x ,
c o n s t d o u b l e * r e s t r i c t b ) {
i f ( n = = 0 ) {
f o r ( u n s i g n e d l o n g r = 0 ; r < m ; + + r ) {
d o u b l e t = b [ r ] ;
f o r ( u n s i g n e d l o n g i = 0 ; i < n ; + + i ) { / / D e a d c o d e
t + = a [ r * n + i ] * x [ i ] ; / / D e a d c o d e
} / / D e a d c o d e
y [ r ] = t ;
}
} e l s e {
/ / . . . s k i p p e d . . .
}
}](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-65-320.jpg)



![LOOP INVARIANT CODE MOTION2/3
f o r ( u n s i g n e d l o n g r = 0 ; r < m ; + + r ) {
d o u b l e t = b [ r ] ;
f o r ( u n s i g n e d l o n g i = 0 ; i < n ; + + i ) {
t + = a [ ( r * n ) + i ] * x [ i ] ; / / " r * n " i s a i n n e r l o o p i n v a r i a n t
}
y [ r ] = t ;
}
f o r ( u n s i g n e d l o n g r = 0 ; r < m ; + + r ) {
d o u b l e t = b [ r ] ;
u n s i g n e d l o n g k = r * n ; / / " r * n " m o v e d o u t o f t h e i n n e r l o o p
f o r ( u n s i g n e d l o n g i = 0 ; i < n ; + + i ) {
t + = a [ k + i ] * x [ i ] ;
}
y [ r ] = t ;
}](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-69-320.jpg)

![INDUCTION VARIABLE
If x represents the trip count (iteration count), then we call
a*x+b induction variables.
f o r ( u n s i g n e d l o n g r = 0 ; r < m ; + + r ) {
d o u b l e t = b [ r ] ;
u n s i g n e d l o n g k = r * n ; / / o u t e r l o o p I V
f o r ( u n s i g n e d l o n g i = 0 ; i < n ; + + i ) {
u n s i g n e d l o n g m = k + i ; / / i n n e r l o o p I V
t + = a [ m ] * x [ i ] ;
}
y [ r ] = t ;
}
k and r are induction variables of outer loop.
i and m are induction variables of inner loop.](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-71-320.jpg)
![LOOP STRENGTH REDUCTION1/2
Strength reduction is an optimization to replace the
multiplication in induction variables with an addition.
f o r ( u n s i g n e d l o n g r = 0 ; r < m ; + + r ) {
d o u b l e t = b [ r ] ;
u n s i g n e d l o n g k = r * n ; / / o u t e r l o o p I V
f o r ( u n s i g n e d l o n g i = 0 ; i < n ; + + i ) {
u n s i g n e d l o n g m = k + i ; / / i n n e r l o o p I V
t + = a [ m ] * x [ i ] ;
}
y [ r ] = t ;
}
f o r ( u n s i g n e d l o n g r = 0 , k = 0 ; r < m ; + + r , k + = n ) { / / k
d o u b l e t = b [ r ] ;
f o r ( u n s i g n e d l o n g i = 0 , m = k ; i < n ; + + i , + + m ) { / / m
t + = a [ m ] * x [ i ] ;
}
y [ r ] = t ;
}](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-72-320.jpg)
![LOOP STRENGTH REDUCTION2/2
We can even rewrite the range to eliminate the index
computation.
i n t s u m ( c o n s t i n t * a , i n t n ) {
i n t r e s = 0 ;
f o r ( i n t i = 0 ; i < n ; + + i ) {
r e s + = a [ i ] ; / / i m p l i c i t * ( a + s i z e o f ( i n t ) * i )
}
r e t u r n r e s ;
}
i n t s u m ( c o n s t i n t * a , i n t n ) {
i n t r e s = 0 ;
c o n s t i n t * e n d = a + n ; / / i m p l i c i t a + s i z e o f ( i n t ) * n
f o r ( c o n s t i n t * p = a ; p ! = e n d ; + + p ) { / / r a n g e u p d a t e d
r e s + = * p ;
}
r e t u r n r e s ;
}](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-73-320.jpg)

![LOOP UNROLLING2/2
f o r ( u n s i g n e d l o n g r = 0 , k = 0 ; r < m ; + + r , k + = n ) {
d o u b l e t = b [ r ] ;
s w i t c h ( n & 0 x 3 ) { / / D u f f ' s d e v i c e
c a s e 3 : t + = a [ k + 2 ] * x [ 2 ] ;
c a s e 2 : t + = a [ k + 1 ] * x [ 1 ] ;
c a s e 1 : t + = a [ k ] * x [ 0 ] ;
}
f o r ( u n s i g n e d l o n g i = n & 0 x 3 ; i < n ; i + = 4 ) {
t + = a [ k + i ] * x [ i ] ;
t + = a [ k + i + 1 ] * x [ i + 1 ] ;
t + = a [ k + i + 2 ] * x [ i + 2 ] ;
t + = a [ k + i + 3 ] * x [ i + 3 ] ;
}
y [ r ] = t ;
}](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-75-320.jpg)



![INSTRUCTION SELECTION4/5
d e f i n e i 6 4 @ l o a d _ s h i f t ( i 6 4 * % a , i 6 4 % i ) {
e n t :
% 0 = g e t e l e m e n t p t r i 6 4 , i 6 4 * % a , i 6 4 % i
% 1 = l o a d i 6 4 , i 6 4 * % 0
r e t i 6 4 % 1
}
l o a d _ s h i f t :
l d r x 0 , [ x 0 , x 1 , l s l # 3 ]
r e t](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-79-320.jpg)
![INSTRUCTION SELECTION5/5
% s t r u c t . A = t y p e { i 6 4 * , [ 1 6 x i 6 4 ] }
d e f i n e i 6 4 @ g e t _ v a l ( % s t r u c t . A * % p , i 6 4 % i , i 6 4 % j ) {
e n t :
% 0 = g e t e l e m e n t p t r % s t r u c t . A , % s t r u c t . A * % p , i 6 4 % i , i 3 2 1 , i 6 4 % j
% 1 = l o a d i 6 4 , i 6 4 * % 0
r e t i 6 4 % 1
}
g e t _ v a l :
m o v z w 8 , # 0 x 8 8
m a d d x 8 , x 1 , x 8 , x 0
a d d x 8 , x 8 , x 2 , l s l # 3
l d r x 0 , [ x 8 , # 8 ]
r e t](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-80-320.jpg)

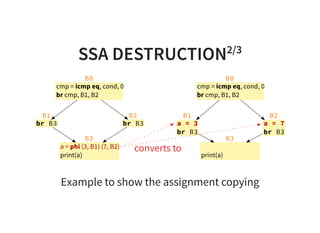
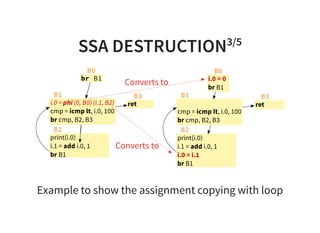



![INSTRUCTION SCHEDULING2/2
0 : a d d r 0 , r 0 , r 1
1 : a d d r 1 , r 2 , r 2
2 : l d r r 4 , [ r 3 ]
3 : s u b r 4 , r 4 , r 0
4 : s t r r 4 , [ r 1 ]
2 : l d r r 4 , [ r 3 ] # l o a d i n s t r u c t i o n n e e d s m o r e c y c l e s
0 : a d d r 0 , r 0 , r 1
1 : a d d r 1 , r 2 , r 2
3 : s u b r 4 , r 4 , r 0
4 : s t r r 4 , [ r 1 ]](https://image.slidesharecdn.com/compiler-intro-160630161929/85/Introduction-to-Compiler-Development-89-320.jpg)











The document provides an introduction to compiler development by Logan Chien, covering compiler technologies, their significance in programming, and insights into industrial-strength compiler design. It outlines key components of compilers, such as lexers, parsers, and code generators, and discusses advanced topics like optimization, analysis, and different architectures. The presentation aims to bridge academia and industry by highlighting the essential skills and knowledge required for effective compiler development.




























![Oh Crap, I Forgot (Or Never Learned) C! [CodeMash 2010]](https://cdn.slidesharecdn.com/ss_thumbnails/oh-crap-i-never-learned-c-codemash-2010-100115163750-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






































