

![1. Install the development files for iODBC. Usually you just need to install the
libiodbc-devel or libiodbc2-dev package provided by your distribution.
2. In the pyodbc source directory, edit the setup.py file and around line 157,
replace the following line: settings['libraries'].append('odbc') with
settings['libraries'].append('iodbc')
3. Execute the following command as the root user: CFLAGS=`iodbc-config --
cflags` LDFLAGS=`iodbc-config --libs` python setup.py install.
(ii) ODBC Drivers :
For each RDBMS, you need its corresponding ODBC driver, which must also be
installed on the same machine that MySQL Workbench is running on. This driver is
usually provided by the RDBMS manufacturer, but in some cases they can also be
provided by third party vendors or open source projects.
Operating systems usually provide a graphical interface to help set up ODBC
drivers and data sources. Use that to install the driver (i.e., make the ODBC
Manager "see" a newly installed ODBC driver). You can also use it to create a data
source for a specific database instance, to be connected using a previously
configured driver. Typically you need to provide a name for the data source (the
DSN), in addition to the database server IP, port, username, and sometimes the
database the user has access to.
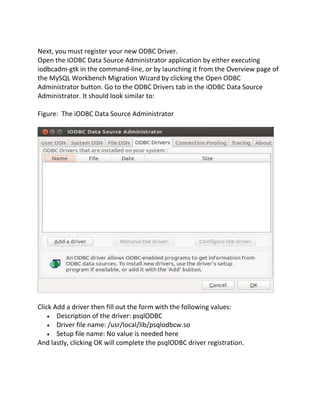
If MySQL Workbench is able to locate an ODBC manager GUI for your system, a
“Plugins”,”Start ODBC – Administrator” menu item be present under the Plugins
menu as a convenience shortcut to start it.
Linux: There are a few GUI utilities, some of which are included with
unixODBC. Refer to the documentation for your distribution. iODBC
provides iodbcadm-gtk. Official binaries of MySQL Workbench include it
and it can be accessed through the “Plugins”, “Start ODBC Administrator”
menu item.
Mac OS X: You can use the ODBC Administrator tool, which is provided as a
separate download from Apple. If the tool is installed in the
/Applications/Utilities folder, you can start it through the “Plugins”, “Start
ODBC Administrator” menu item.](https://image.slidesharecdn.com/databasemigration-130613034640-phpapp01/85/Database-migration-3-320.jpg)













The document provides information about using the MySQL Workbench Migration Wizard to migrate databases between different database types including MySQL, Microsoft SQL Server, and PostgreSQL. It discusses setting up the necessary ODBC libraries and drivers for the source database, an overview of the migration process, type mappings, and specific instructions for migrating from Microsoft SQL Server and PostgreSQL. Setup of ODBC components for Linux, Mac OS X, and Windows is described for each database type.









































































