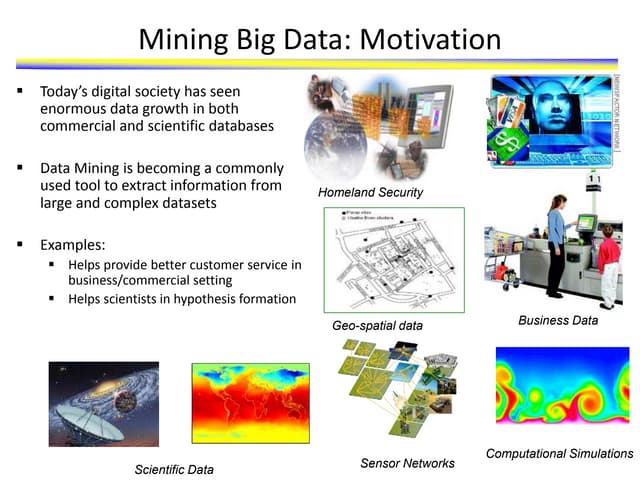
The document discusses various data mining techniques and tools used to analyze genetic data, particularly focusing on human gene families and functional domains. It highlights three main data browsers for genomics, various analysis approaches, and classification methods such as supervised and unsupervised learning. Additionally, it outlines specific algorithms and models that can help in predicting treatment responses and understanding gene relationships.