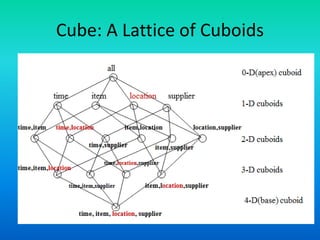
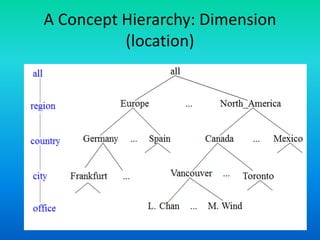
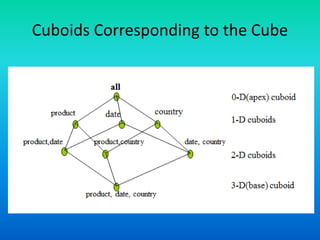
The document discusses data warehouses utilizing a multidimensional data model comprising data cubes that represent facts and dimensions, such as sales data analyzed from various perspectives. It explains the concept of data cubes, the different types of aggregate functions (distributive, algebraic, holistic), and introduces concept hierarchies that define relationships between low-level and high-level concepts for multidimensional analysis. The example provided illustrates how sales can be analyzed based on product, time, and location across different views.

















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)











![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)


