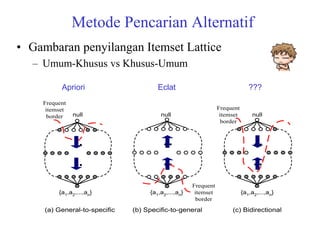
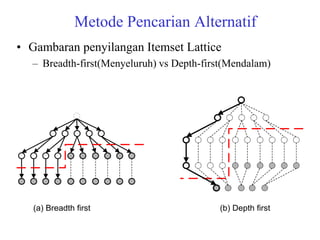
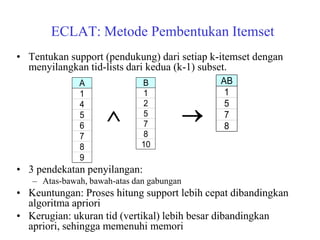
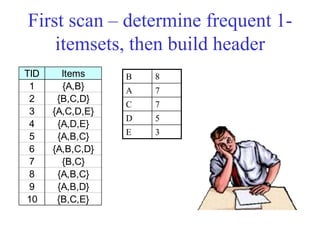
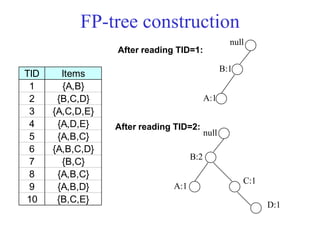
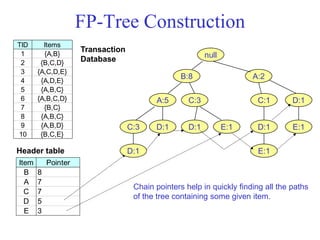
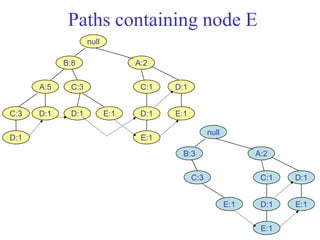
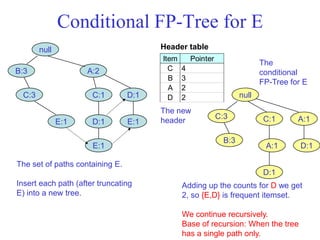
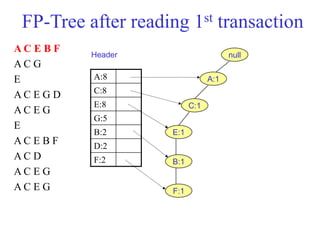
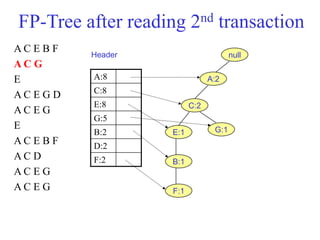
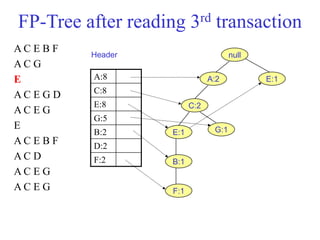
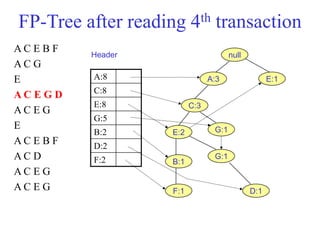
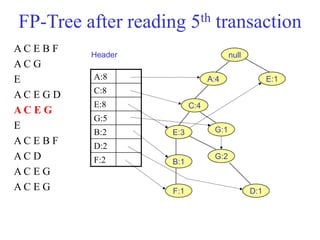
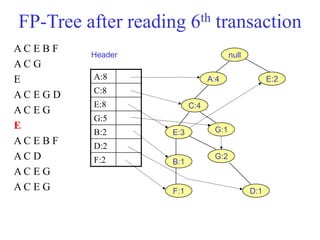
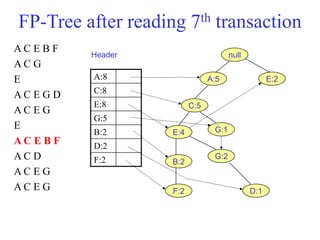
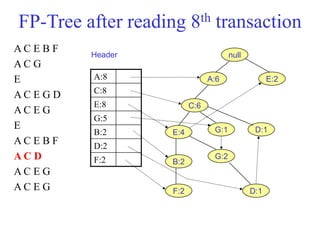
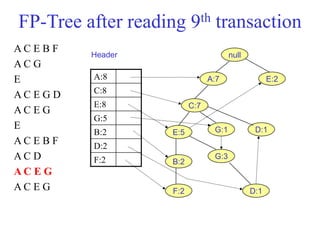
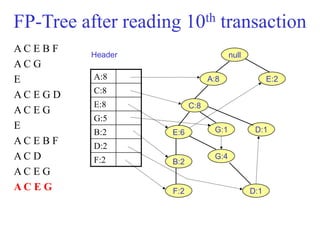
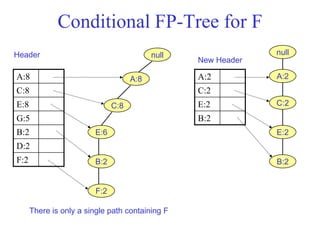
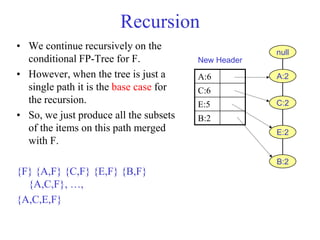
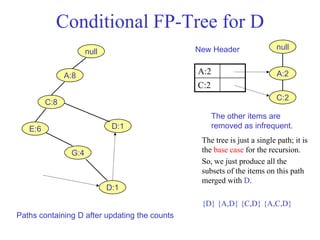
The document discusses the Eclat algorithm for mining frequent itemsets, highlighting its methodology and advantages, including faster support counting compared to the Apriori algorithm. It details the construction of transaction ID tables and the use of vertical data layouts for efficient itemset generation. The document also covers the construction and traversal of FP-trees in the FP-Growth algorithm for deriving frequent itemsets recursively.










![[C++ korea] effective modern c++ study item 4 - 6 신촌](https://cdn.slidesharecdn.com/ss_thumbnails/ckoreaeffectivemoderncstudy-item4-6-150207061235-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
















































