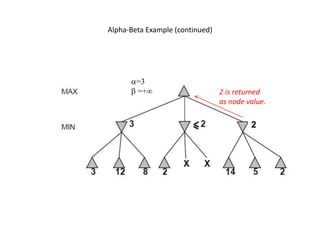
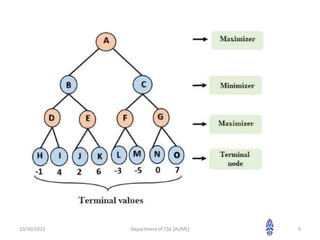
The document discusses different types of adversarial search algorithms. It describes min-max algorithm and alpha-beta pruning. Min-max algorithm searches through the game tree recursively to find the optimal move assuming the opponent plays optimally. Alpha-beta pruning improves on min-max by pruning parts of the tree that cannot contain better moves based on the alpha and beta values being passed down the tree.



















![Alpha-Beta Example (continued)
(−∞,3]
(−∞,+∞)](https://image.slidesharecdn.com/minmaxandalphabetapruning-231030190259-9176badb/85/Minmax-and-alpha-beta-pruning-pptx-21-320.jpg)
![Alpha-Beta Example (continued)
(−∞,3]
(−∞,+∞)](https://image.slidesharecdn.com/minmaxandalphabetapruning-231030190259-9176badb/85/Minmax-and-alpha-beta-pruning-pptx-22-320.jpg)
![Alpha-Beta Example (continued)
[3,+∞)
[3,3]](https://image.slidesharecdn.com/minmaxandalphabetapruning-231030190259-9176badb/85/Minmax-and-alpha-beta-pruning-pptx-23-320.jpg)
![Alpha-Beta Example (continued)
(−∞,2]
[3,+∞)
[3,3]
This node is
worse for MAX](https://image.slidesharecdn.com/minmaxandalphabetapruning-231030190259-9176badb/85/Minmax-and-alpha-beta-pruning-pptx-24-320.jpg)
![Alpha-Beta Example (continued)
(−∞,2]
[3,14]
[3,3] (−∞,14]
,](https://image.slidesharecdn.com/minmaxandalphabetapruning-231030190259-9176badb/85/Minmax-and-alpha-beta-pruning-pptx-25-320.jpg)
![Alpha-Beta Example (continued)
(−∞,2]
[3,5]
[3,3] (−∞,5]
,](https://image.slidesharecdn.com/minmaxandalphabetapruning-231030190259-9176badb/85/Minmax-and-alpha-beta-pruning-pptx-26-320.jpg)
![Alpha-Beta Example (continued)
[2,2]
(−∞,2]
[3,3]
[3,3]](https://image.slidesharecdn.com/minmaxandalphabetapruning-231030190259-9176badb/85/Minmax-and-alpha-beta-pruning-pptx-27-320.jpg)
![Alpha-Beta Example (continued)
[2,2]
(−∞,2]
[3,3]
[3,3]](https://image.slidesharecdn.com/minmaxandalphabetapruning-231030190259-9176badb/85/Minmax-and-alpha-beta-pruning-pptx-28-320.jpg)