Download to read offline




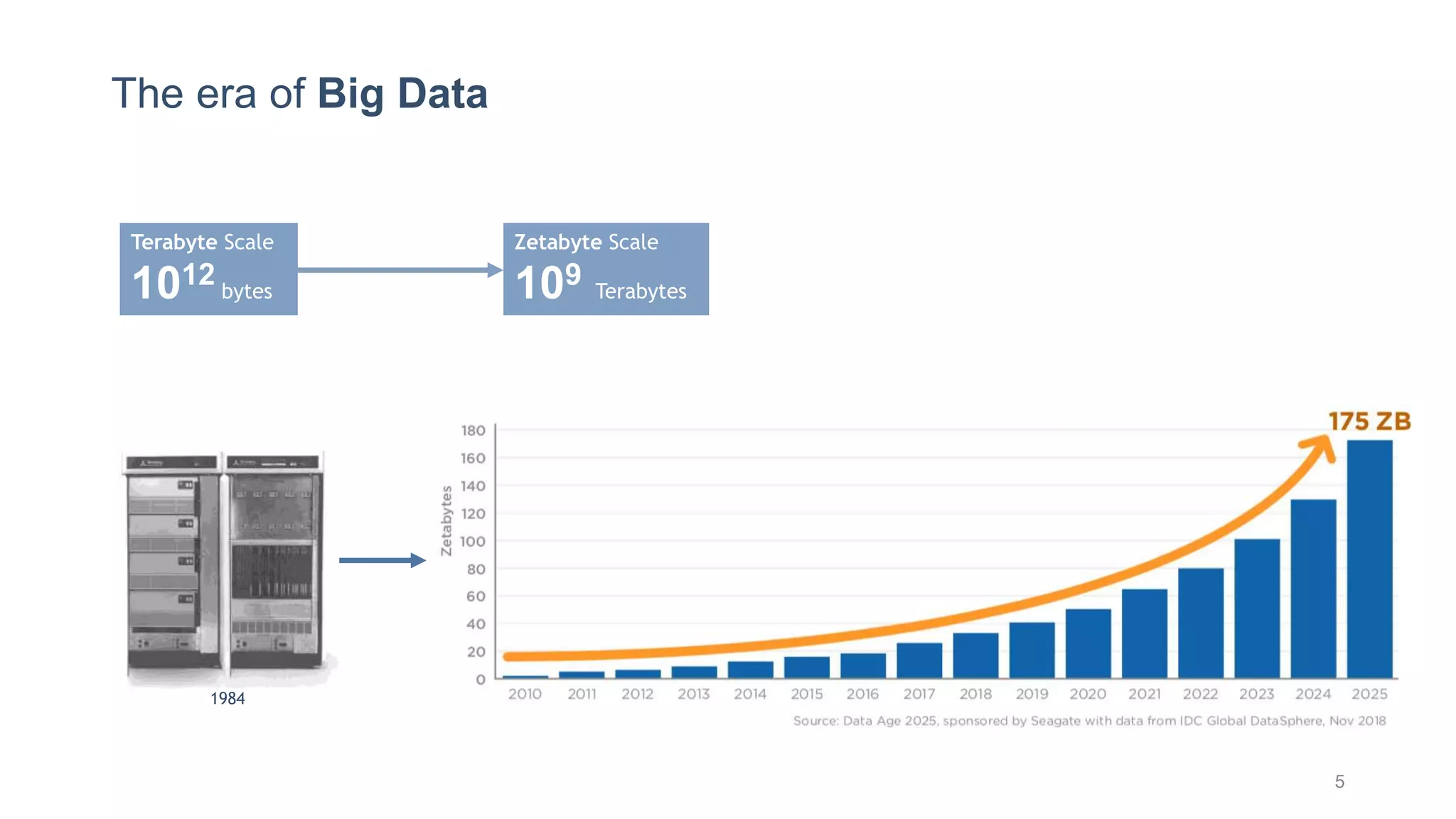

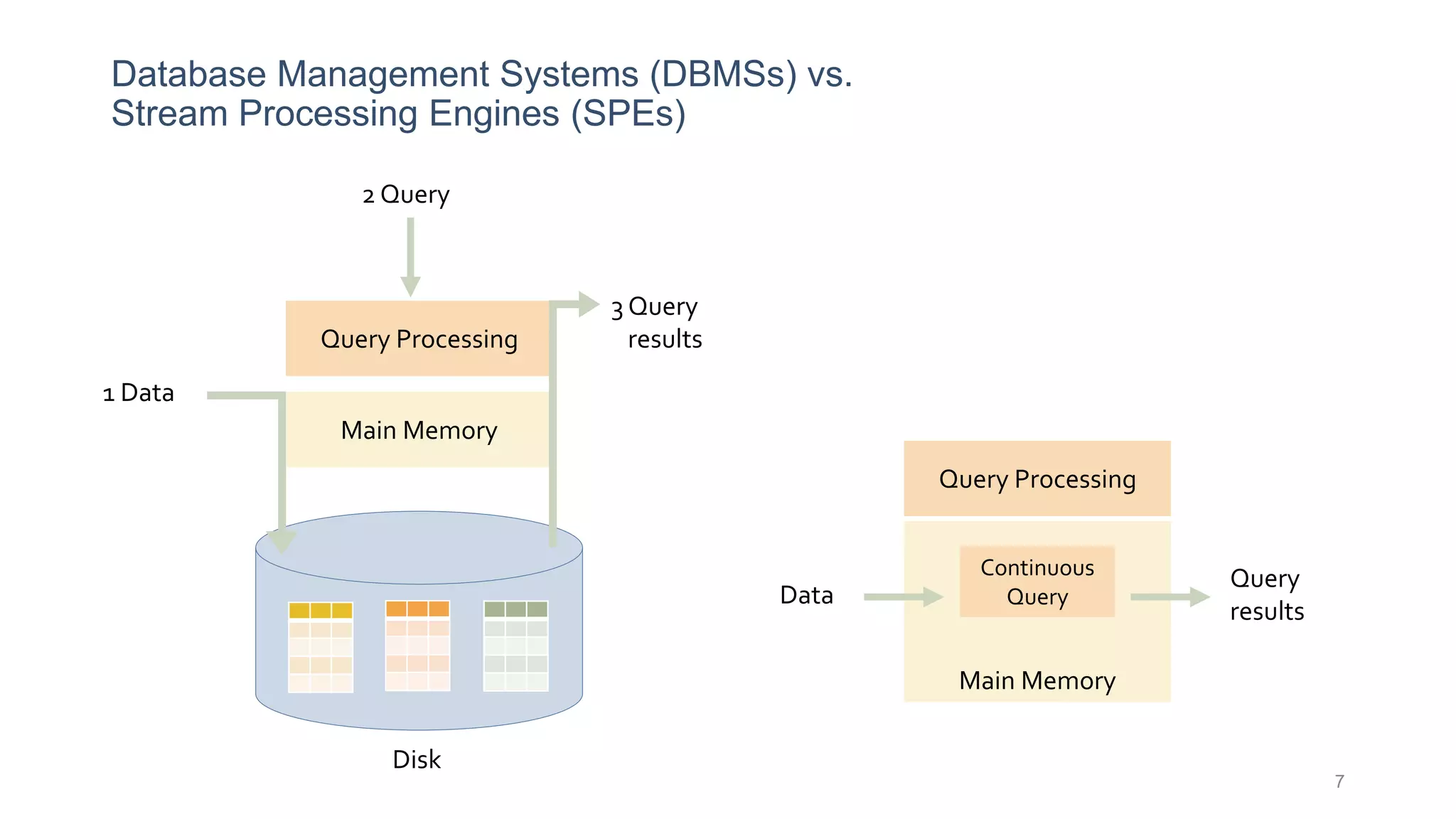


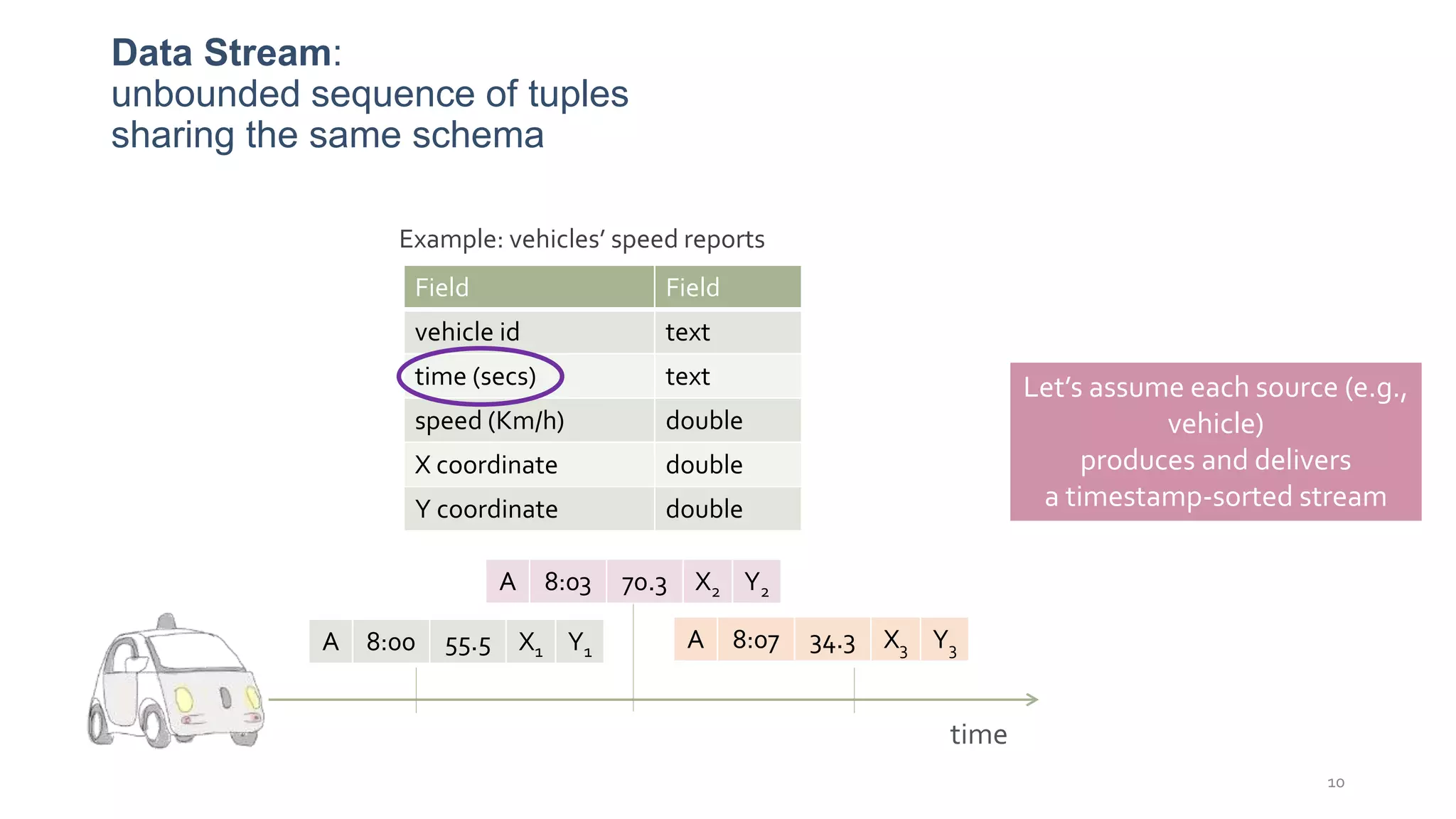
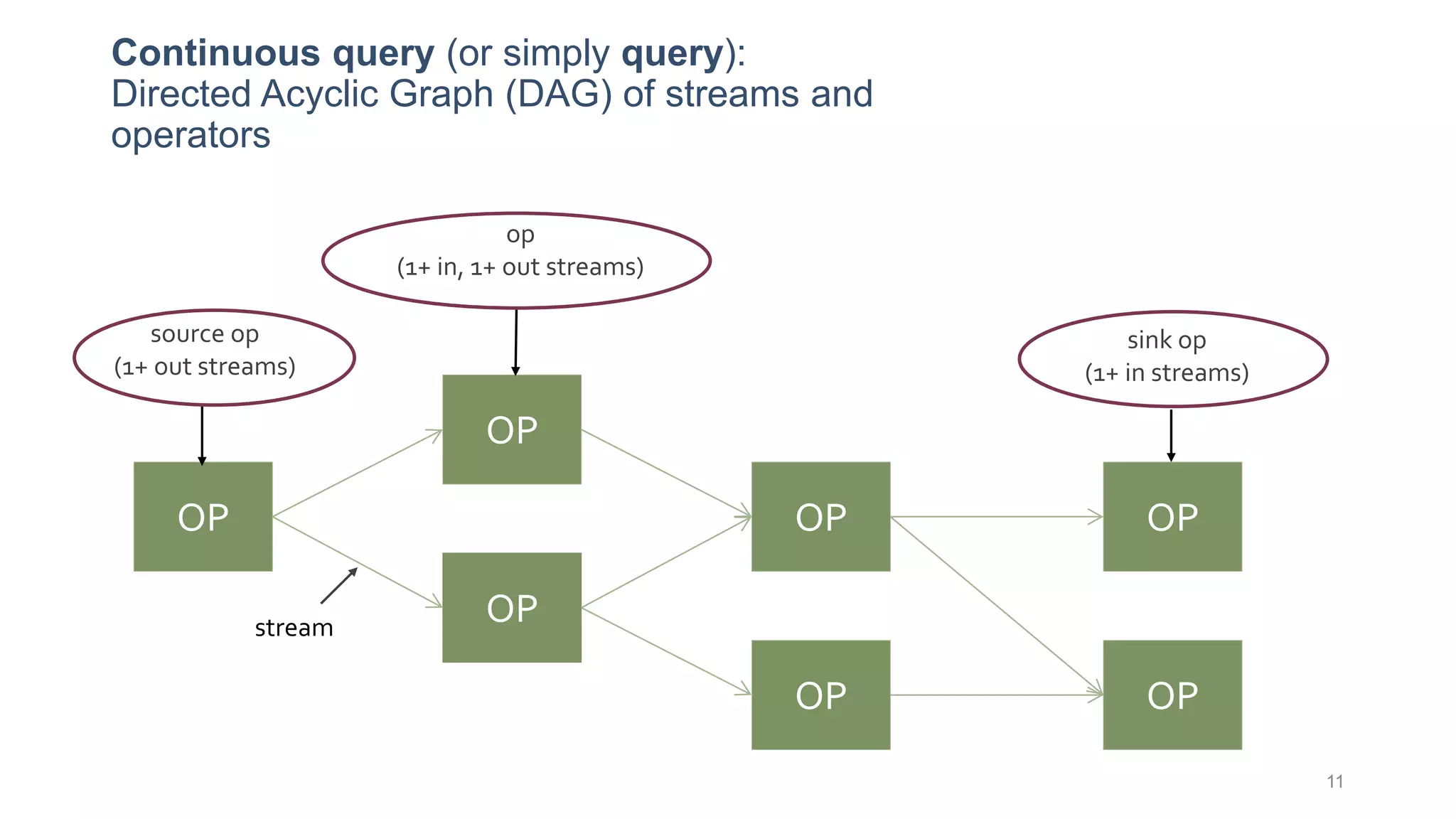


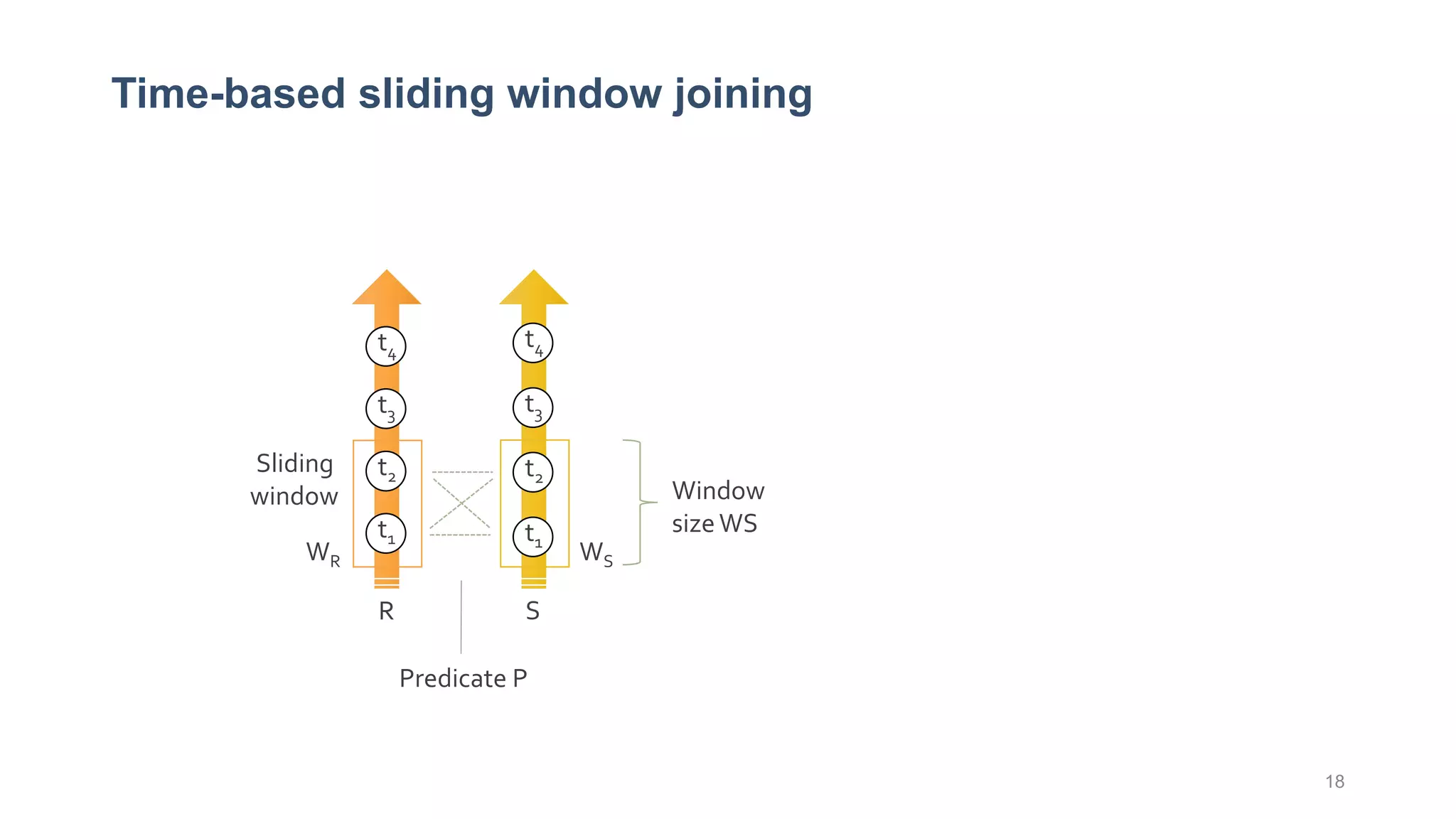


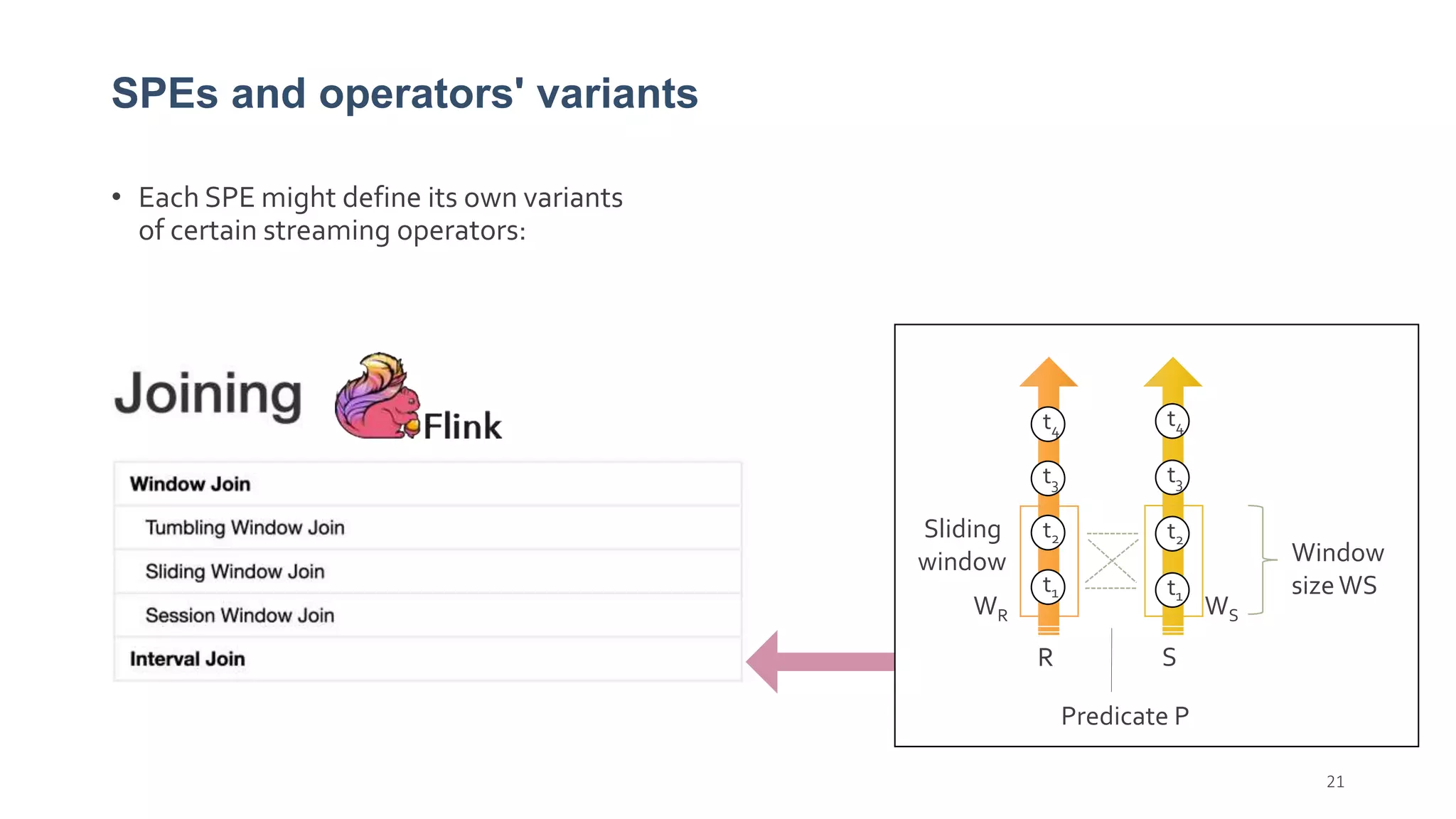
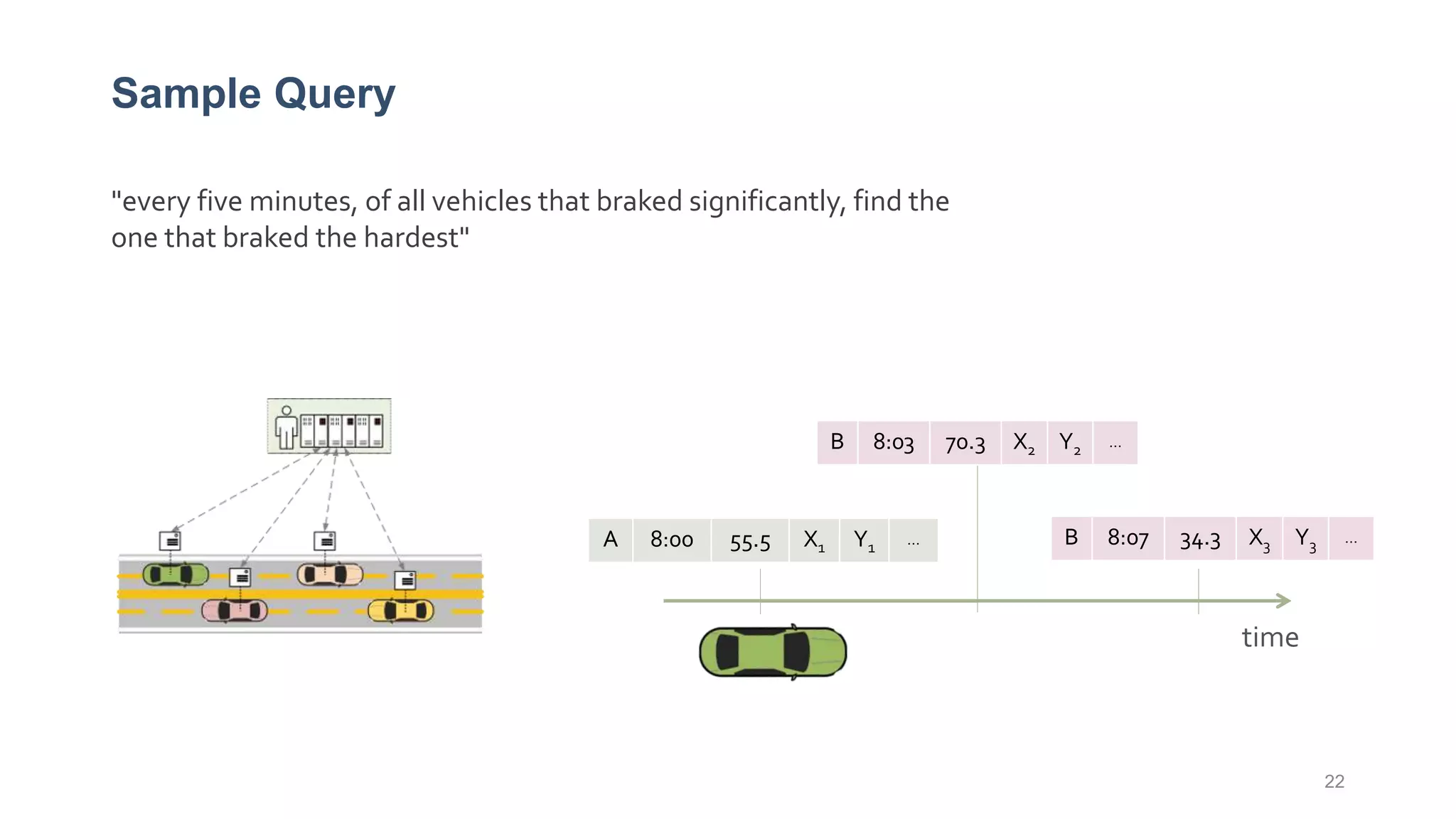
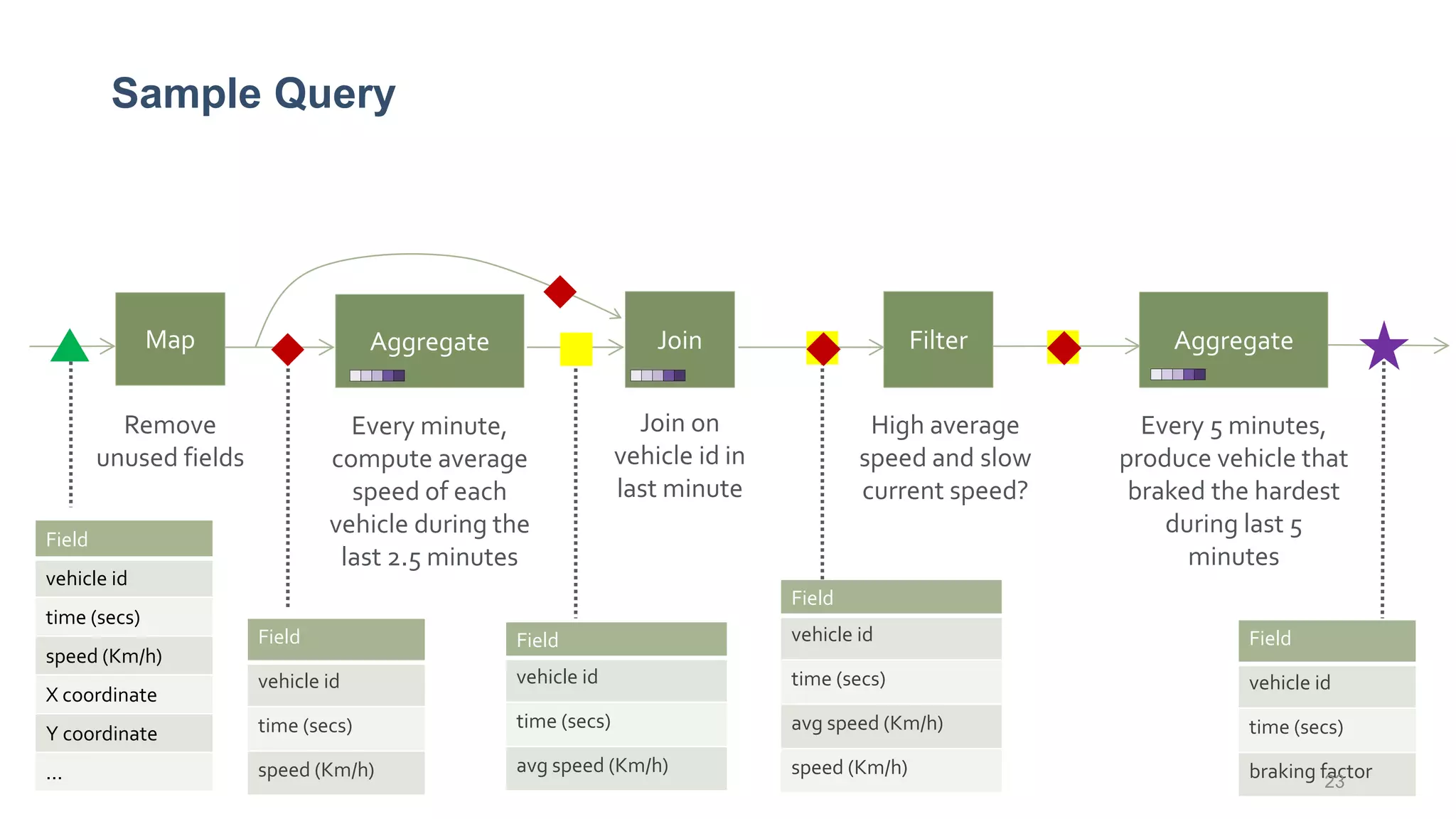

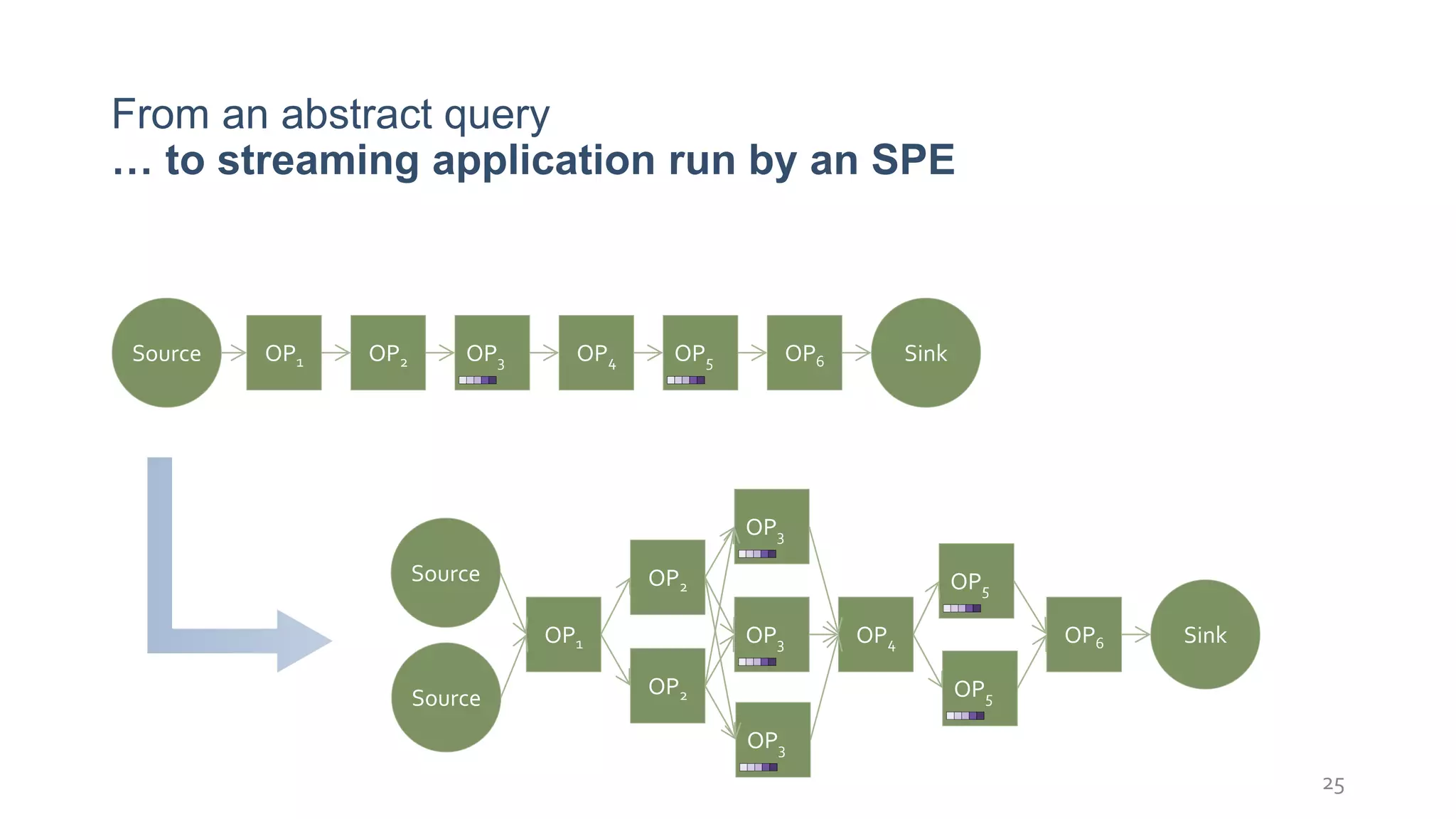
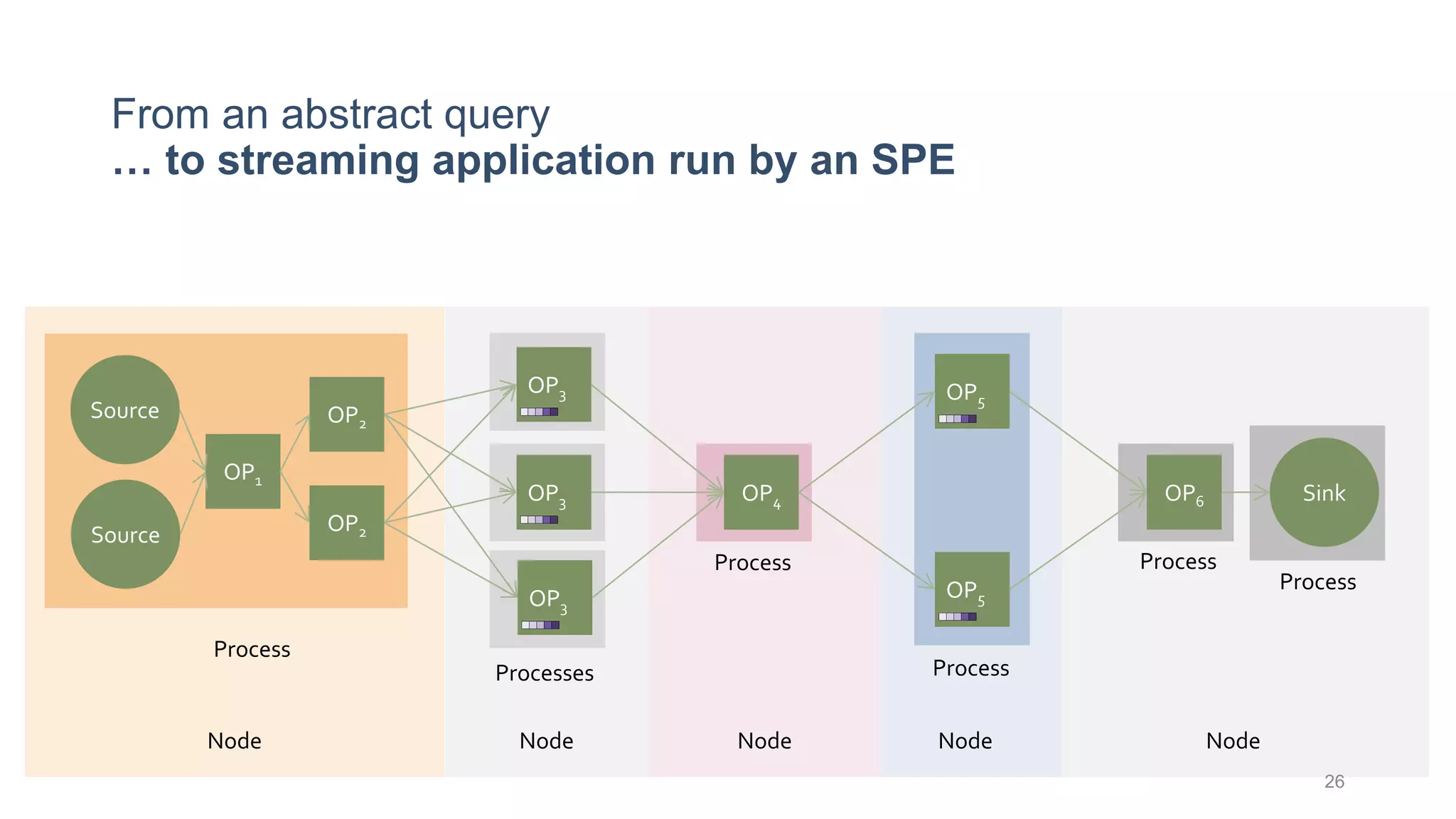
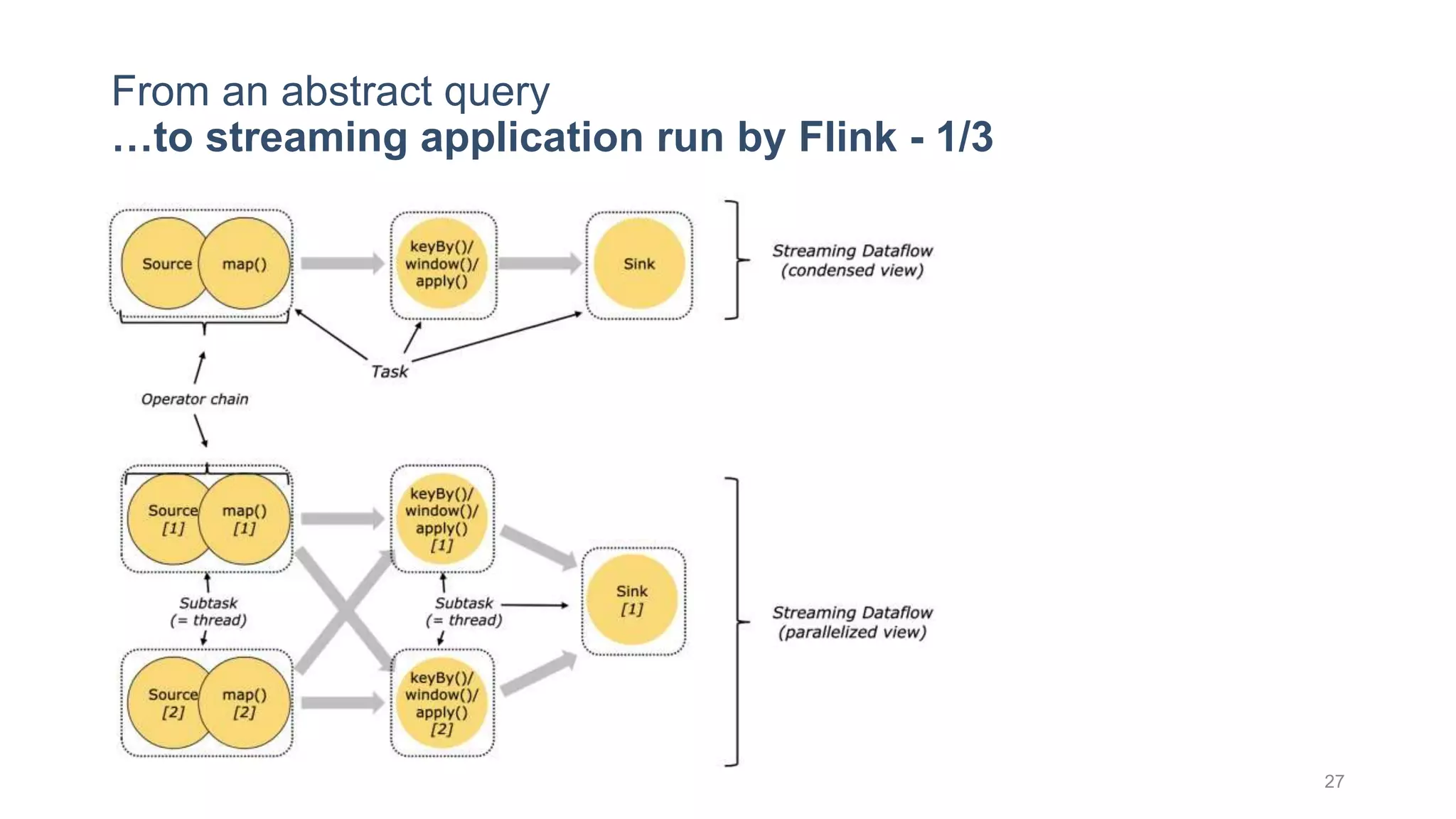
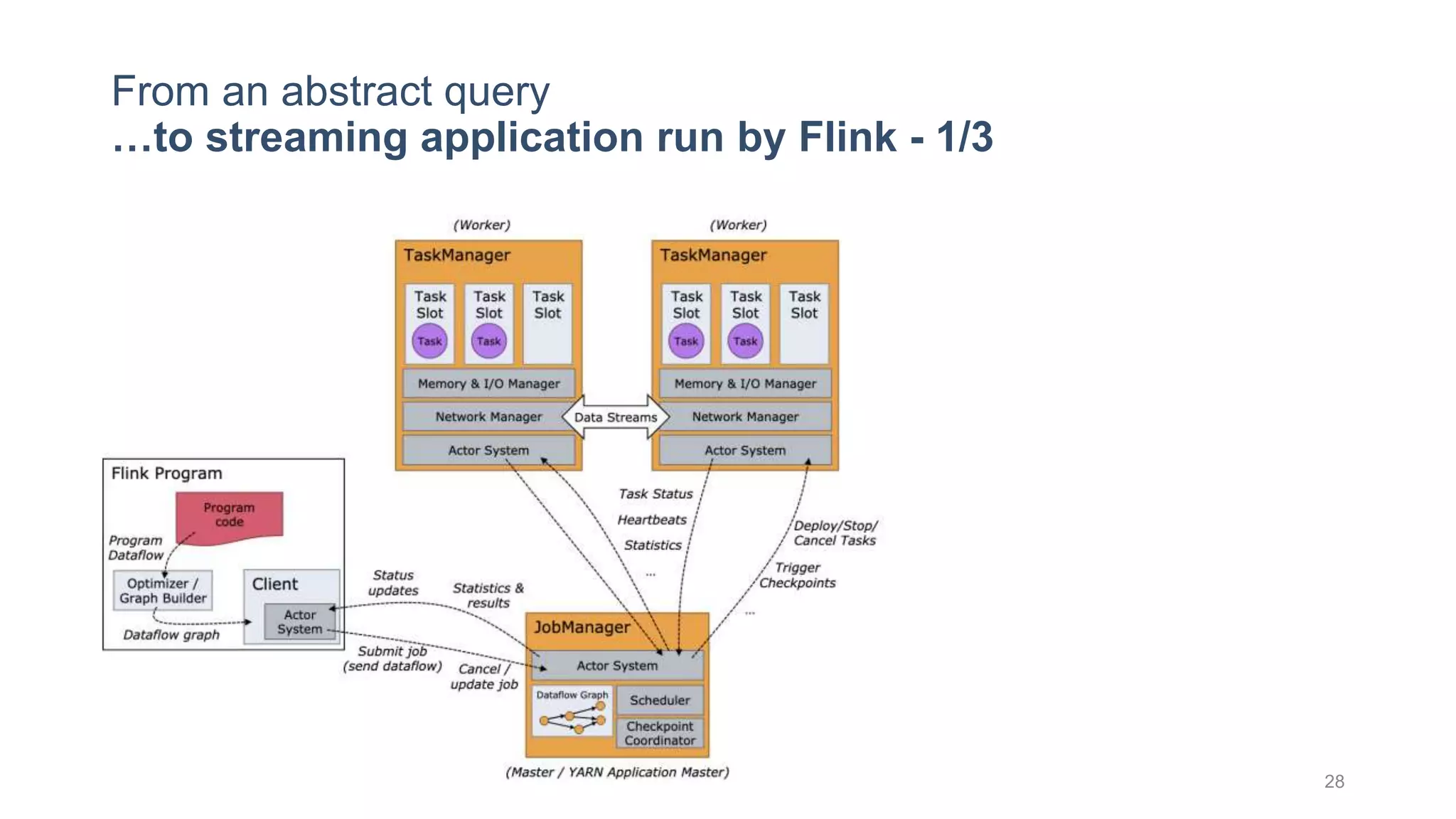
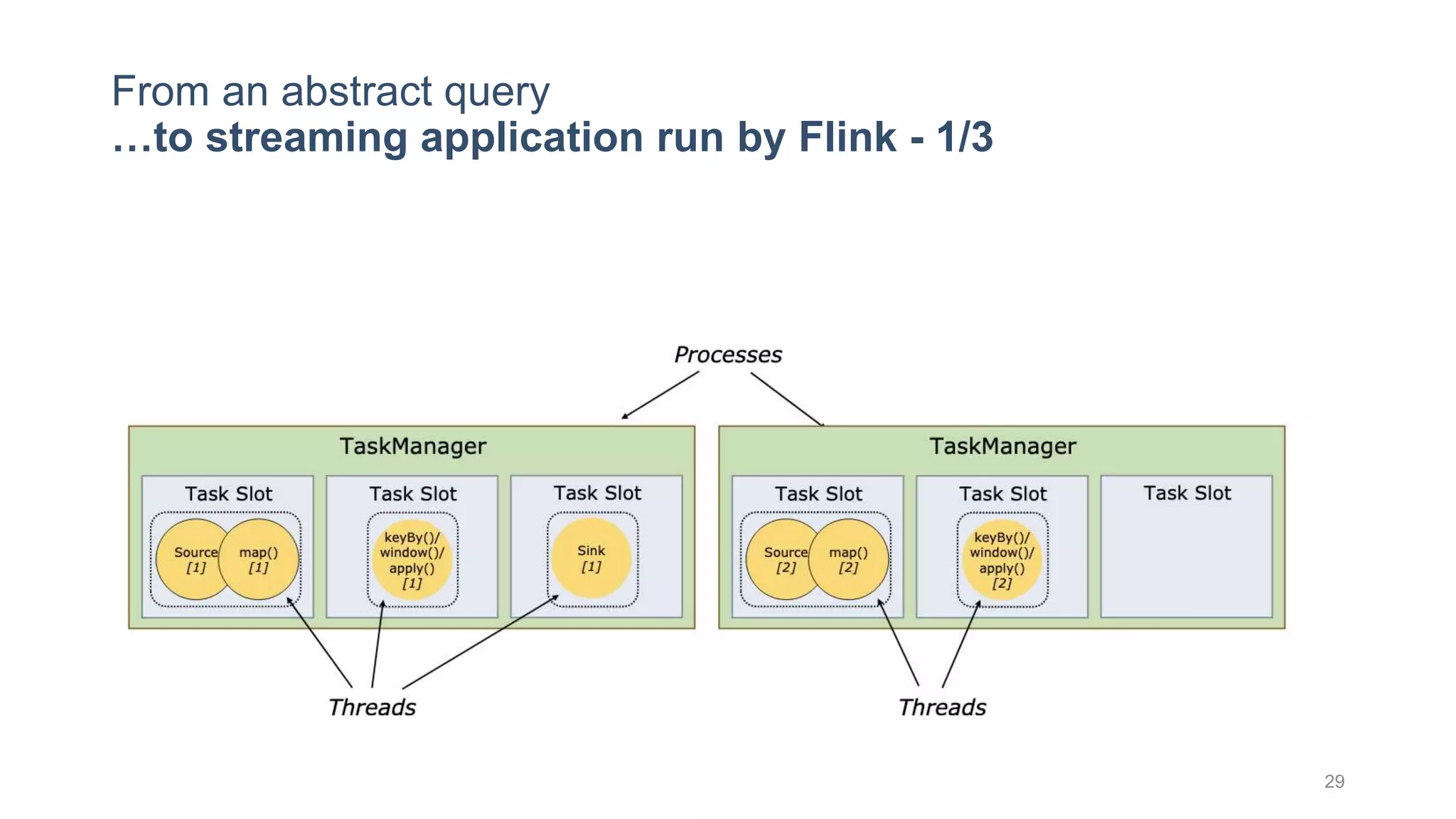
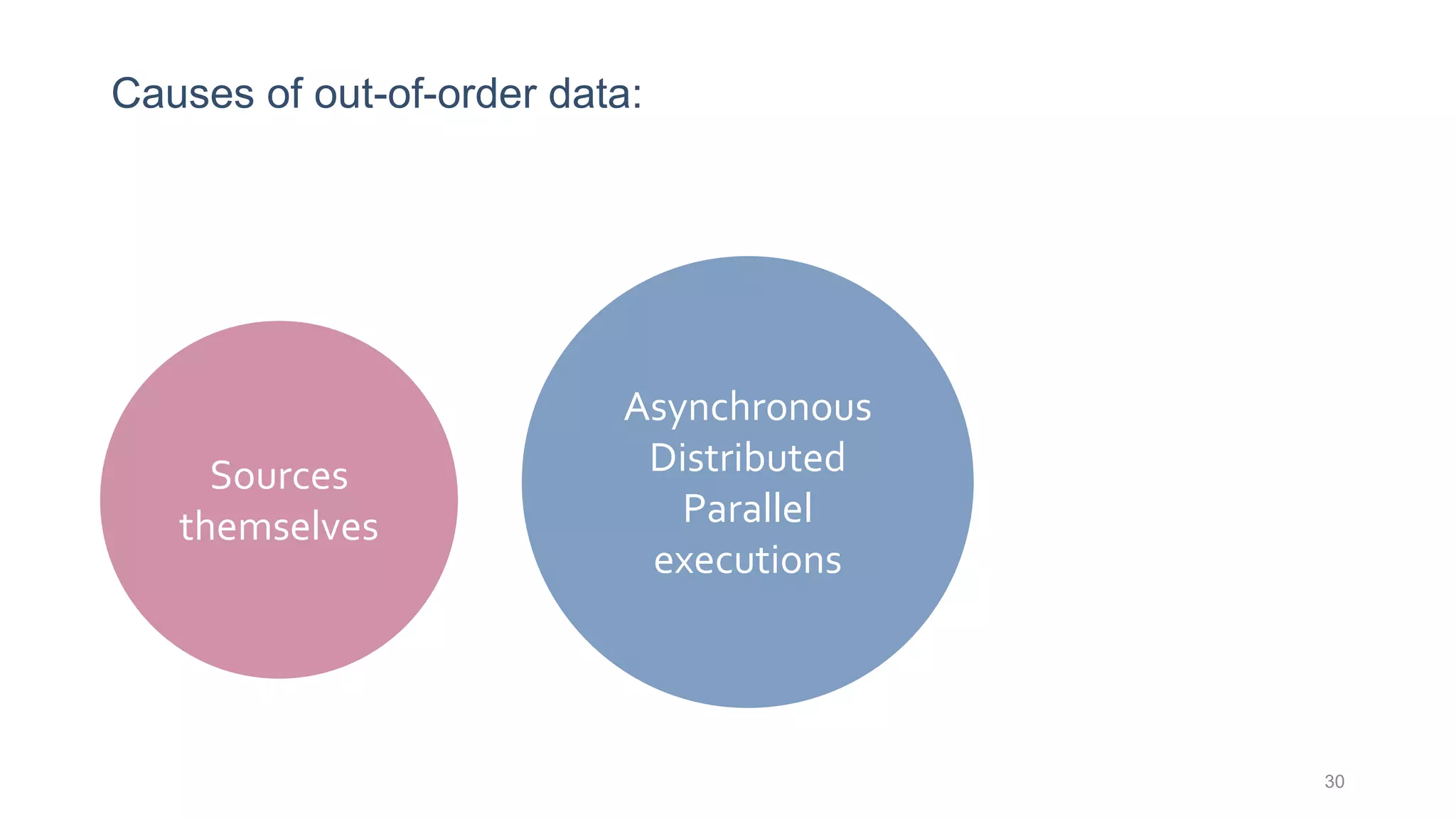

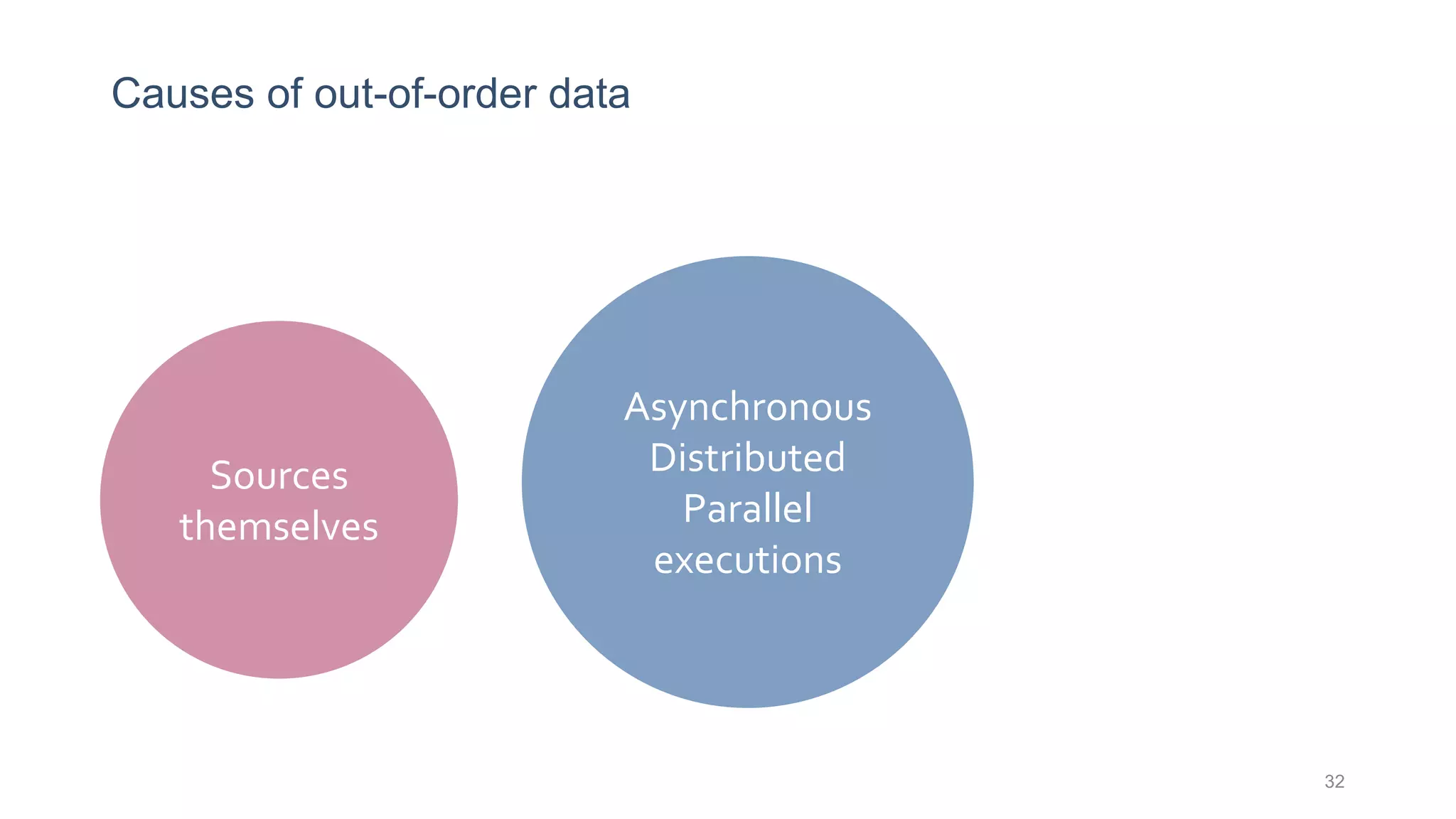
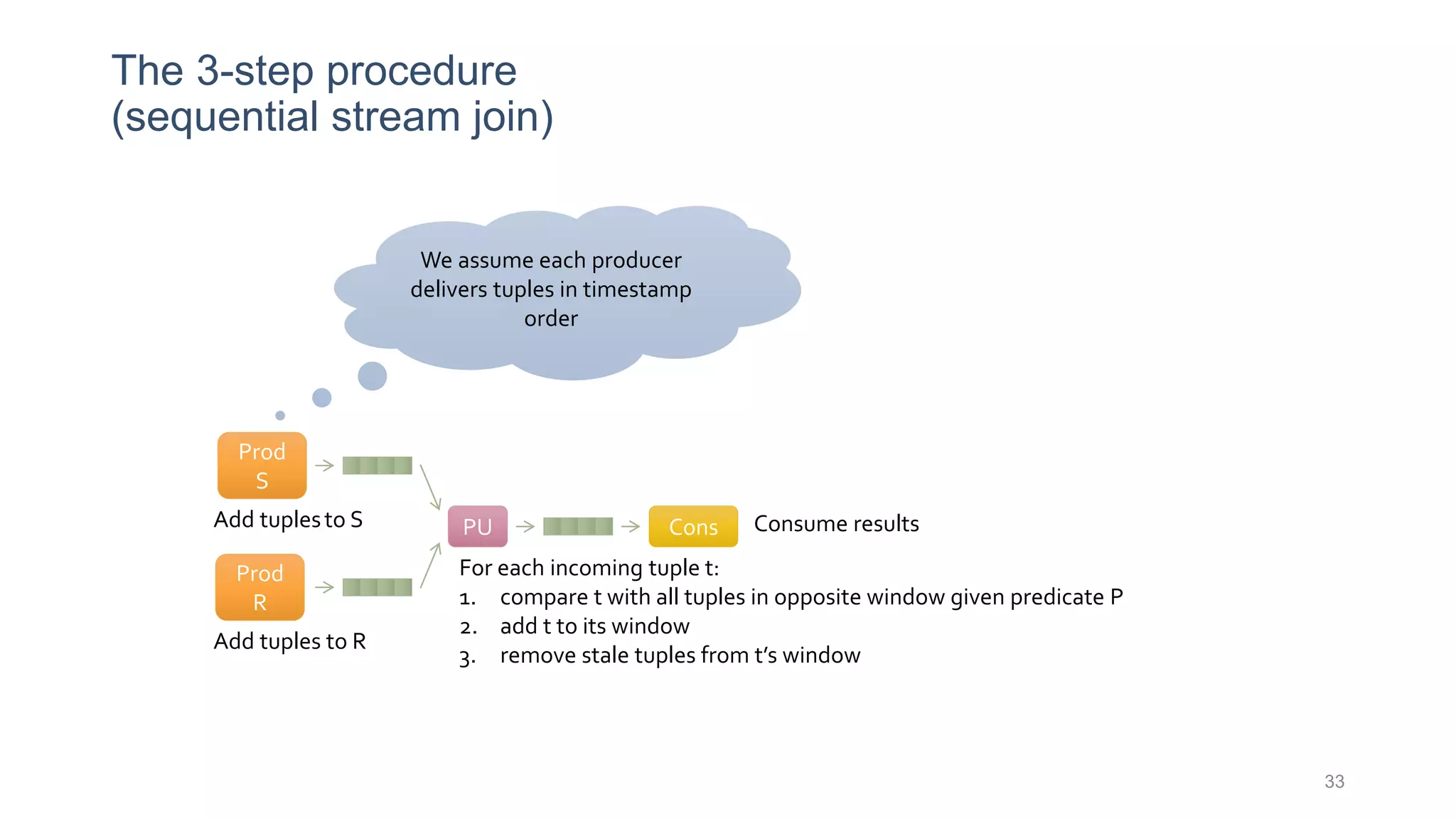
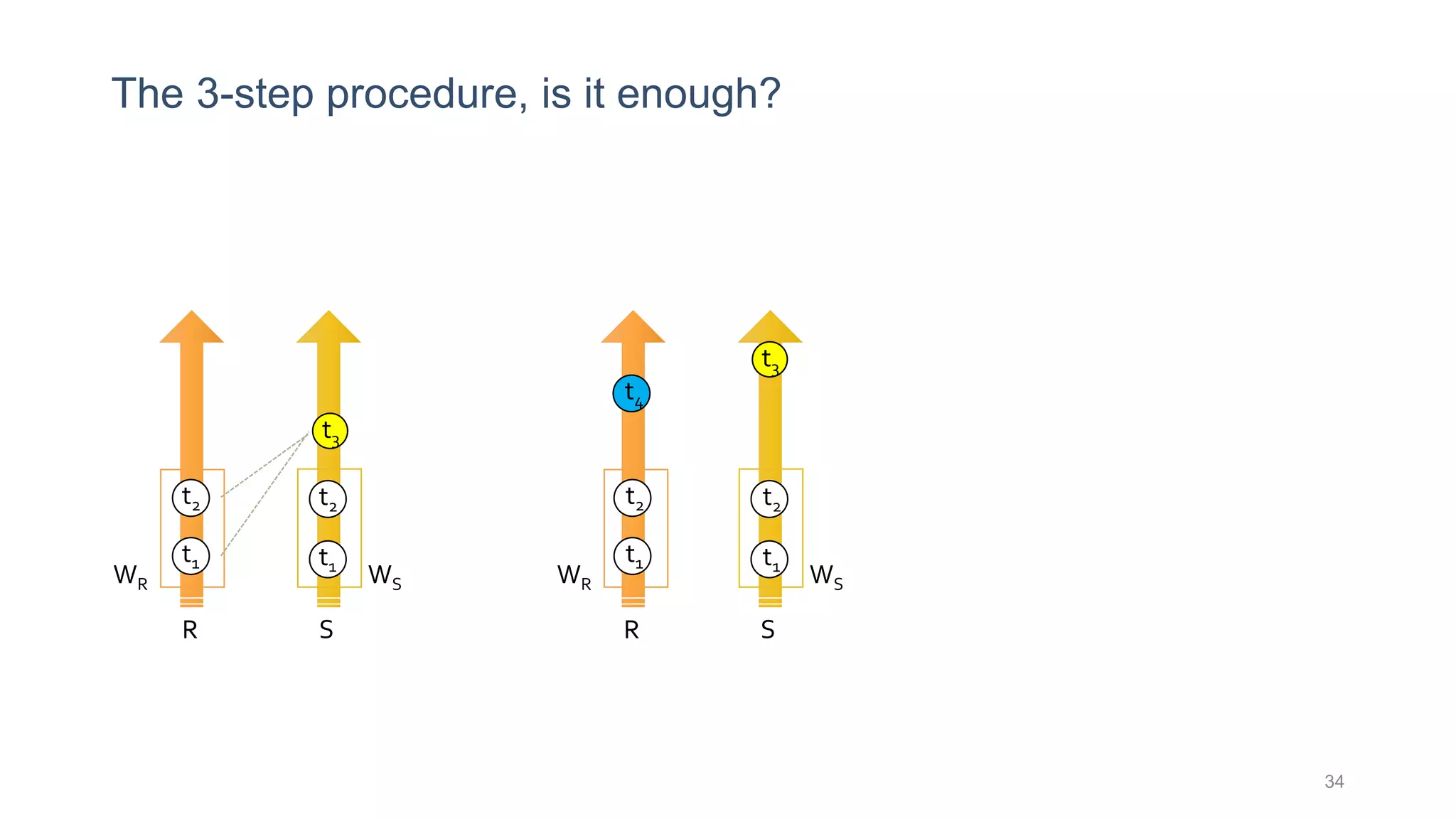
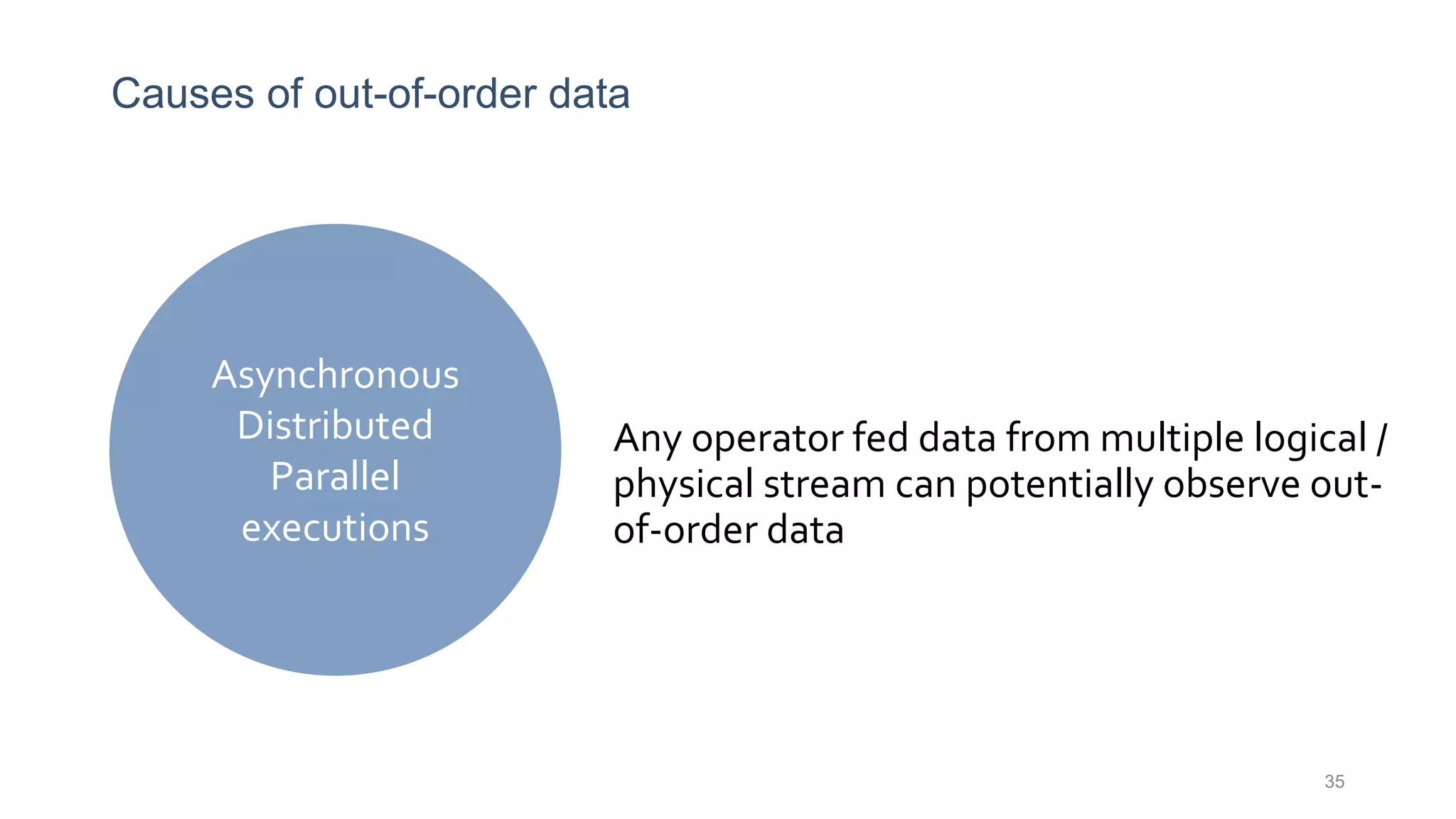
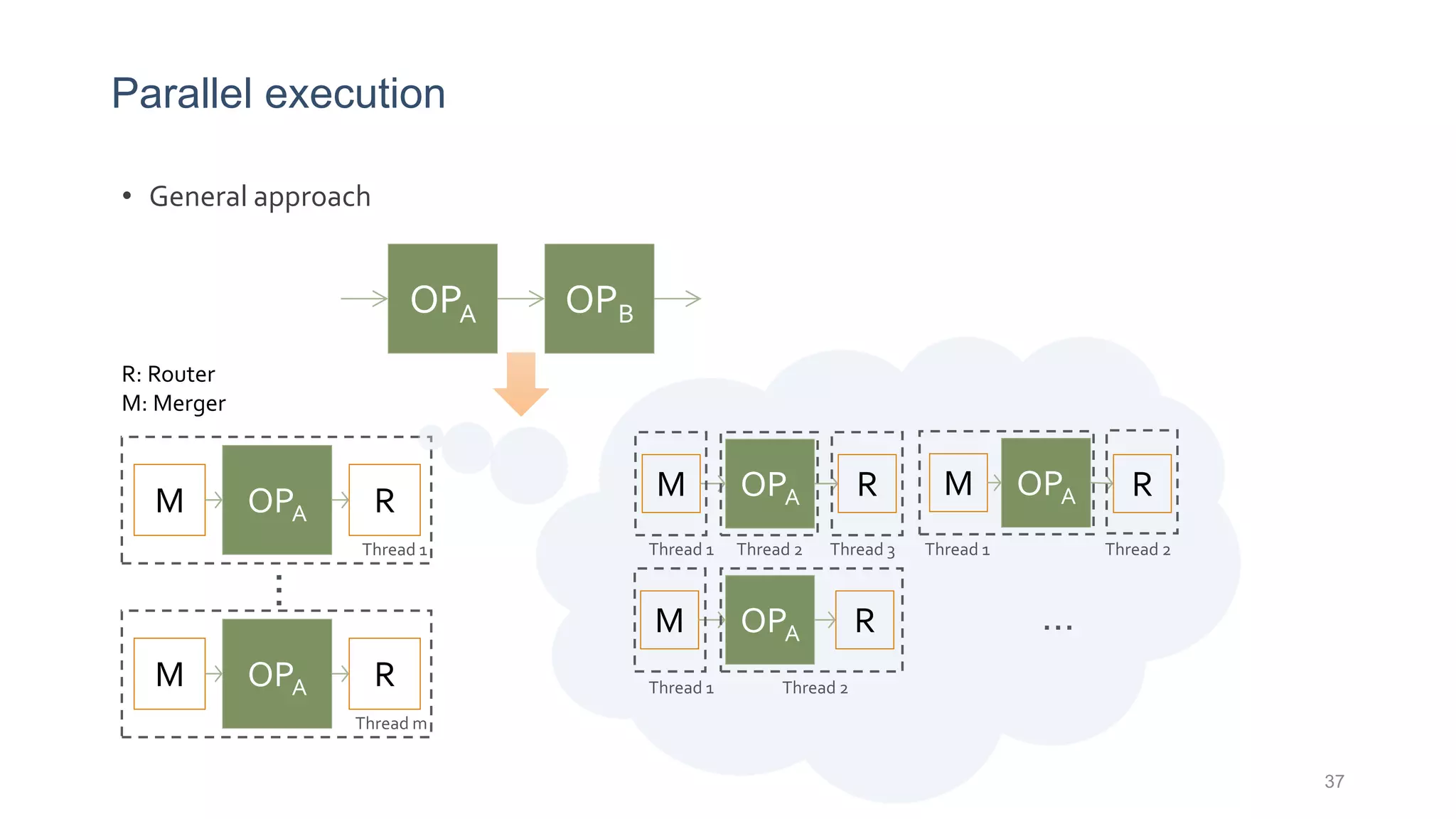
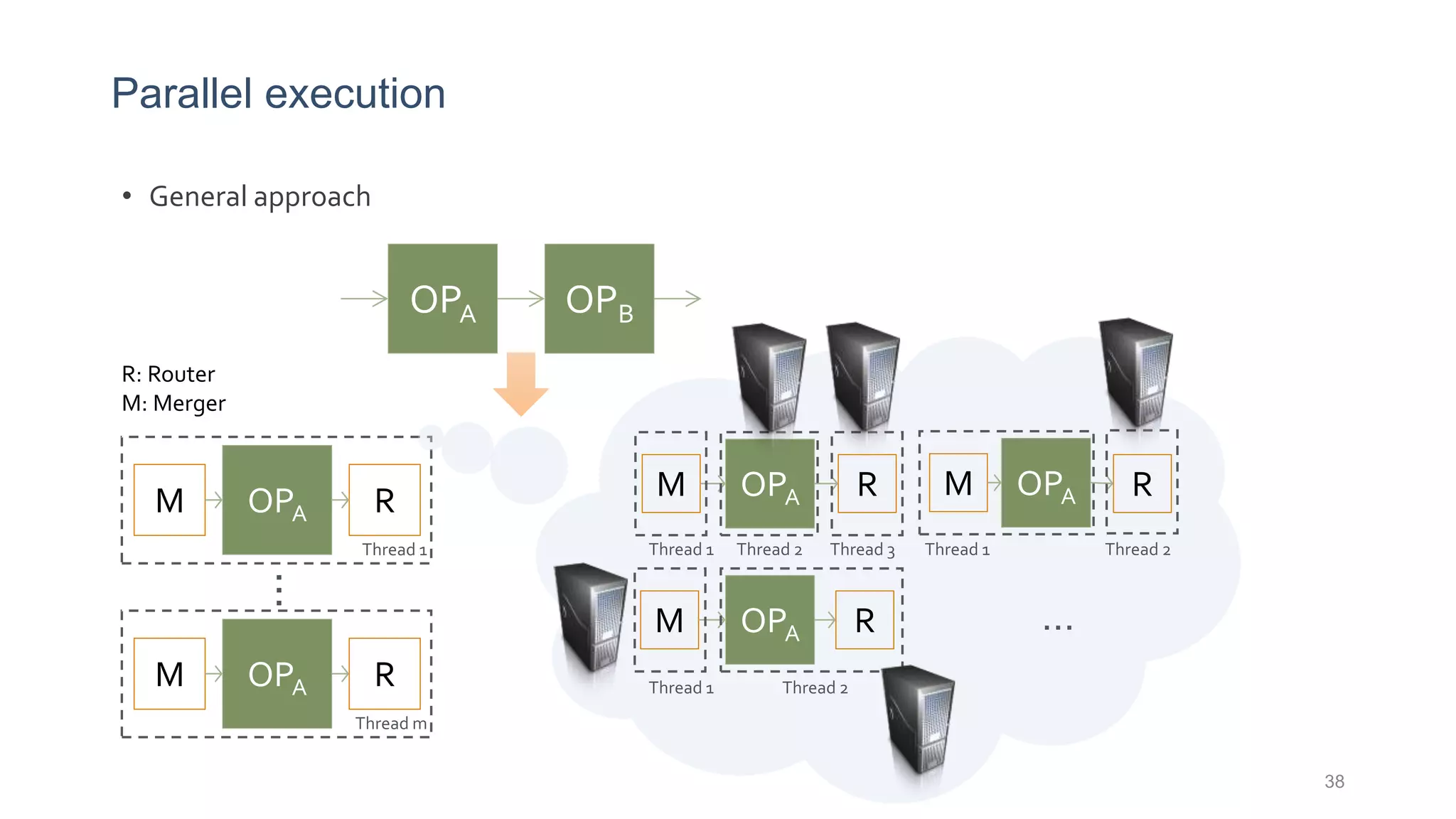
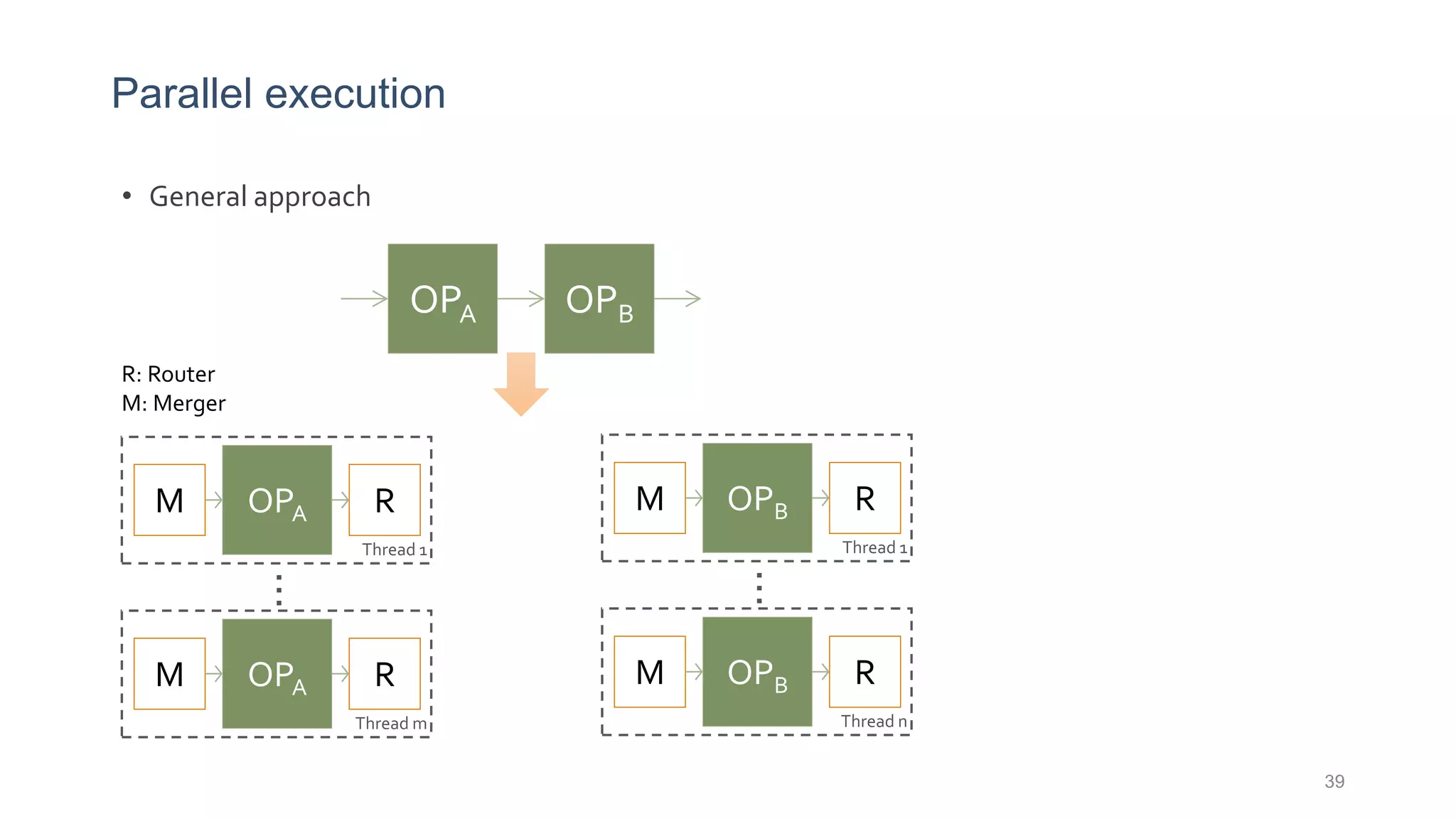
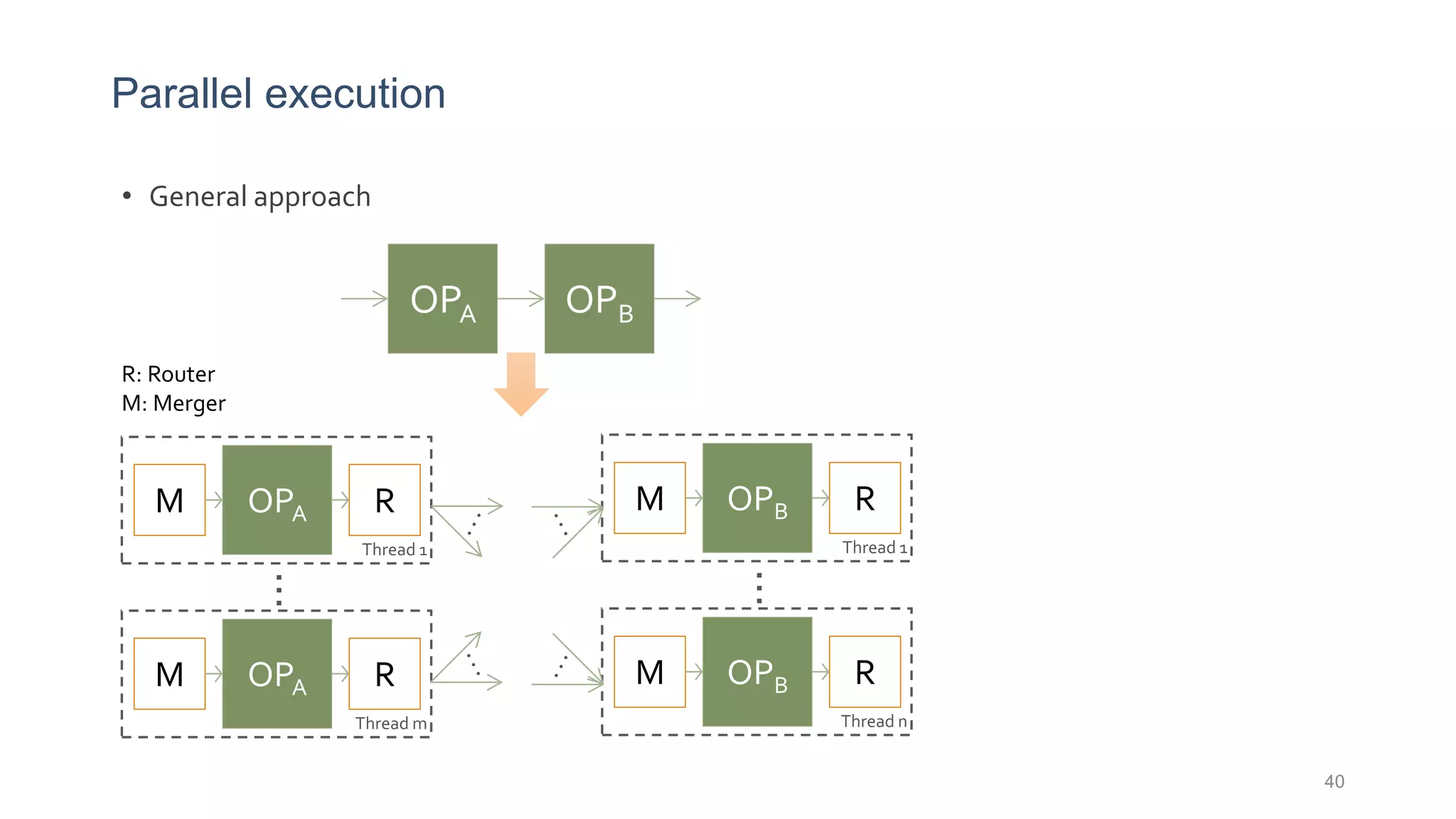
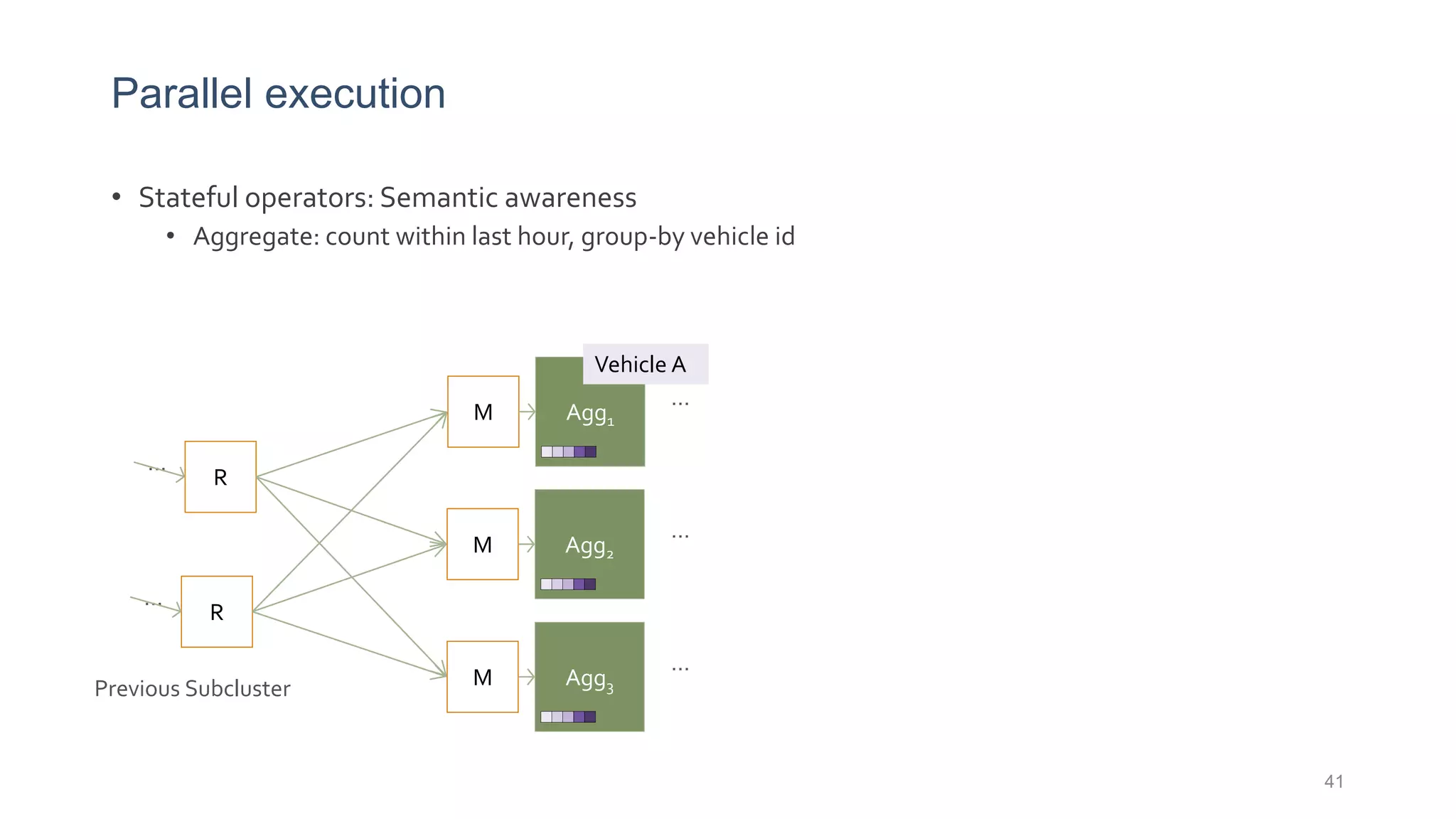


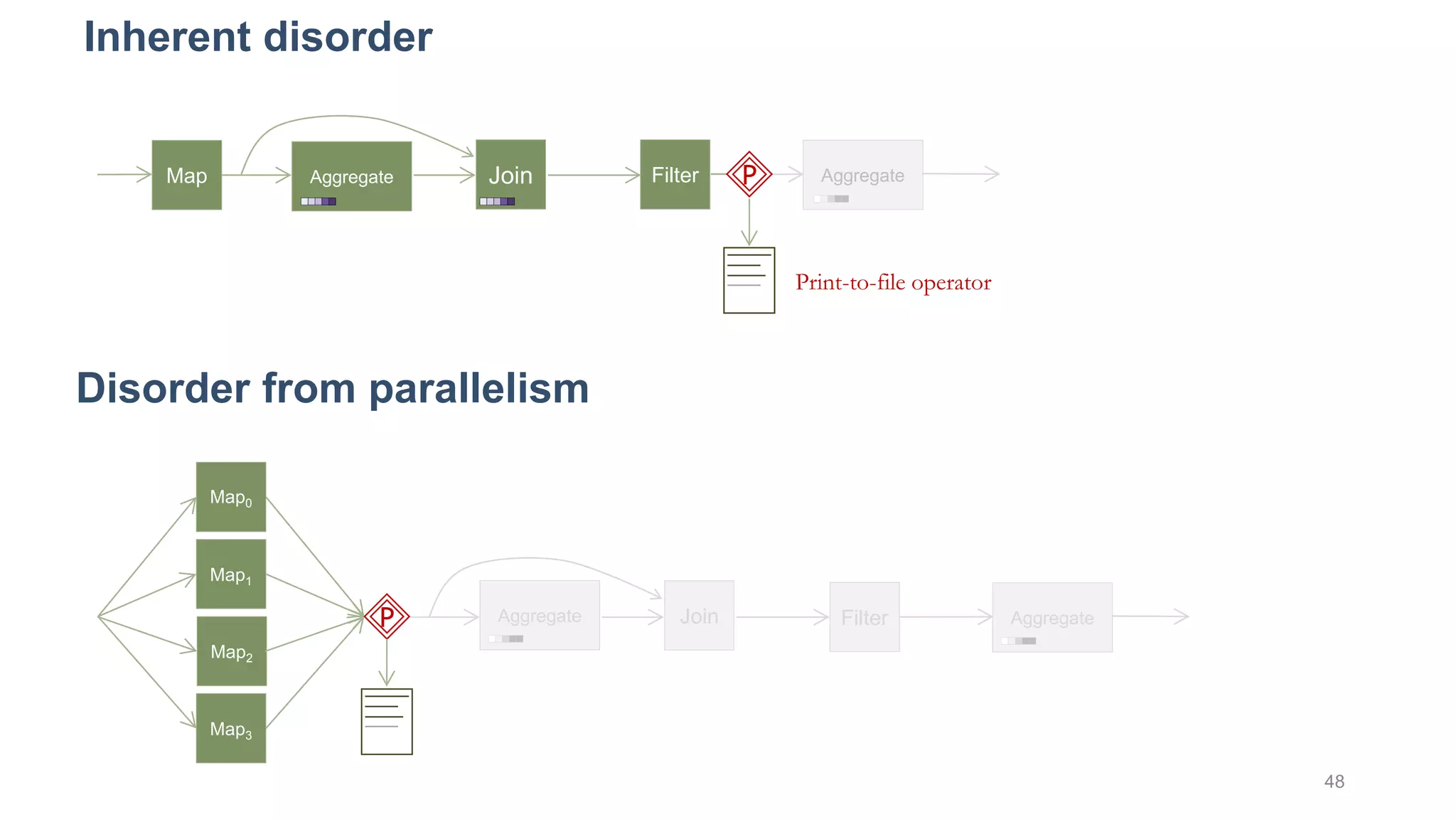

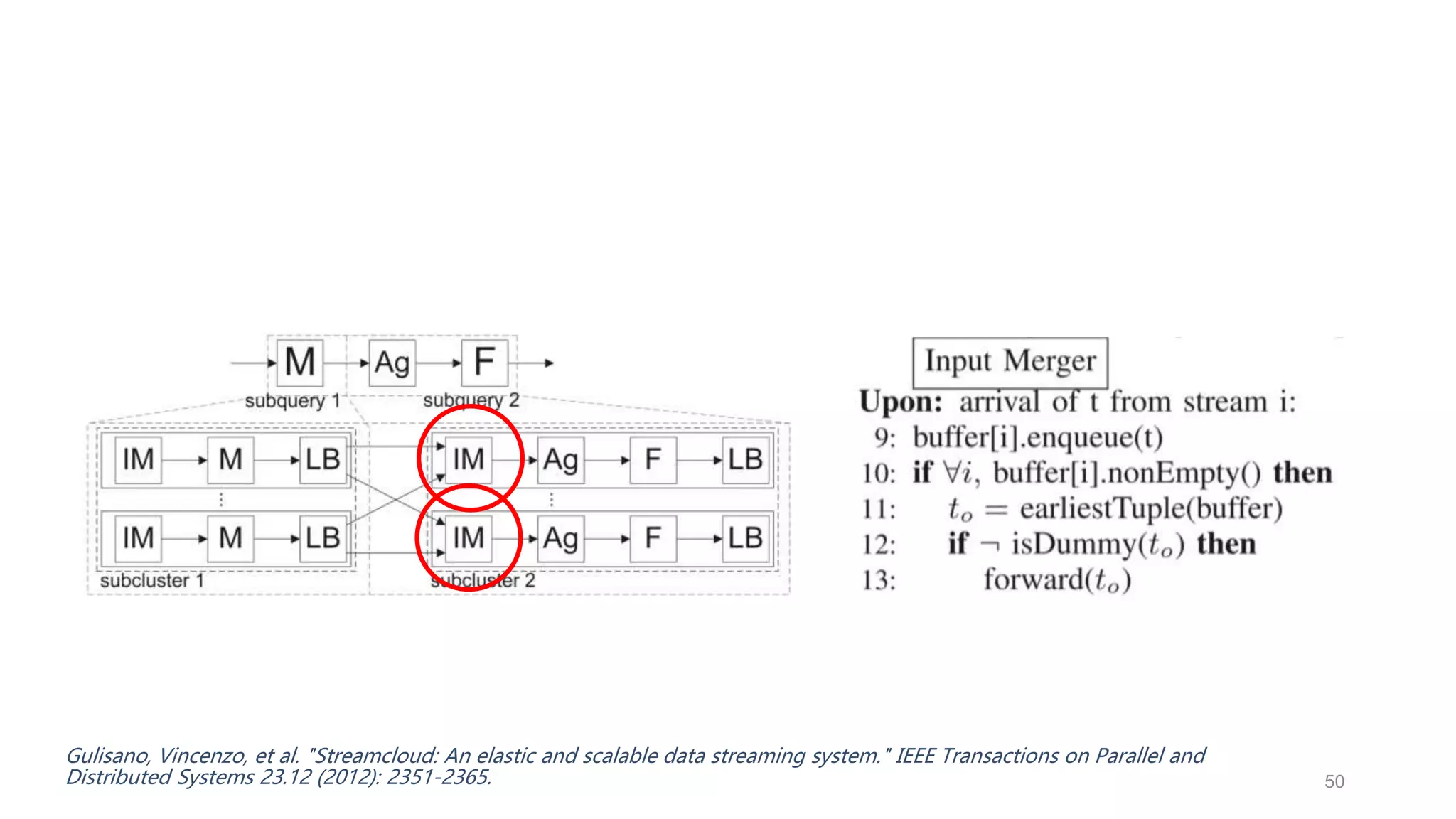
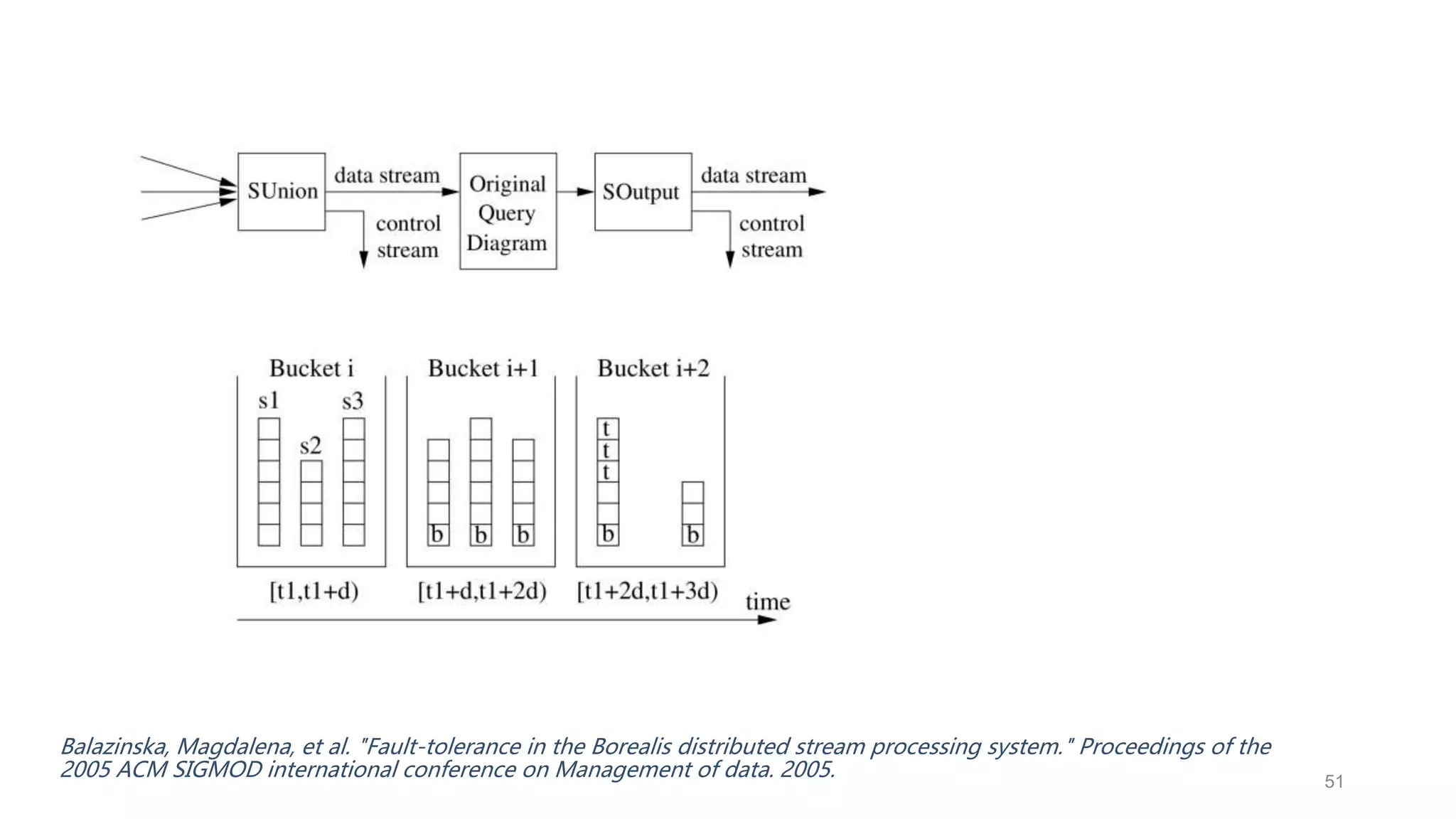
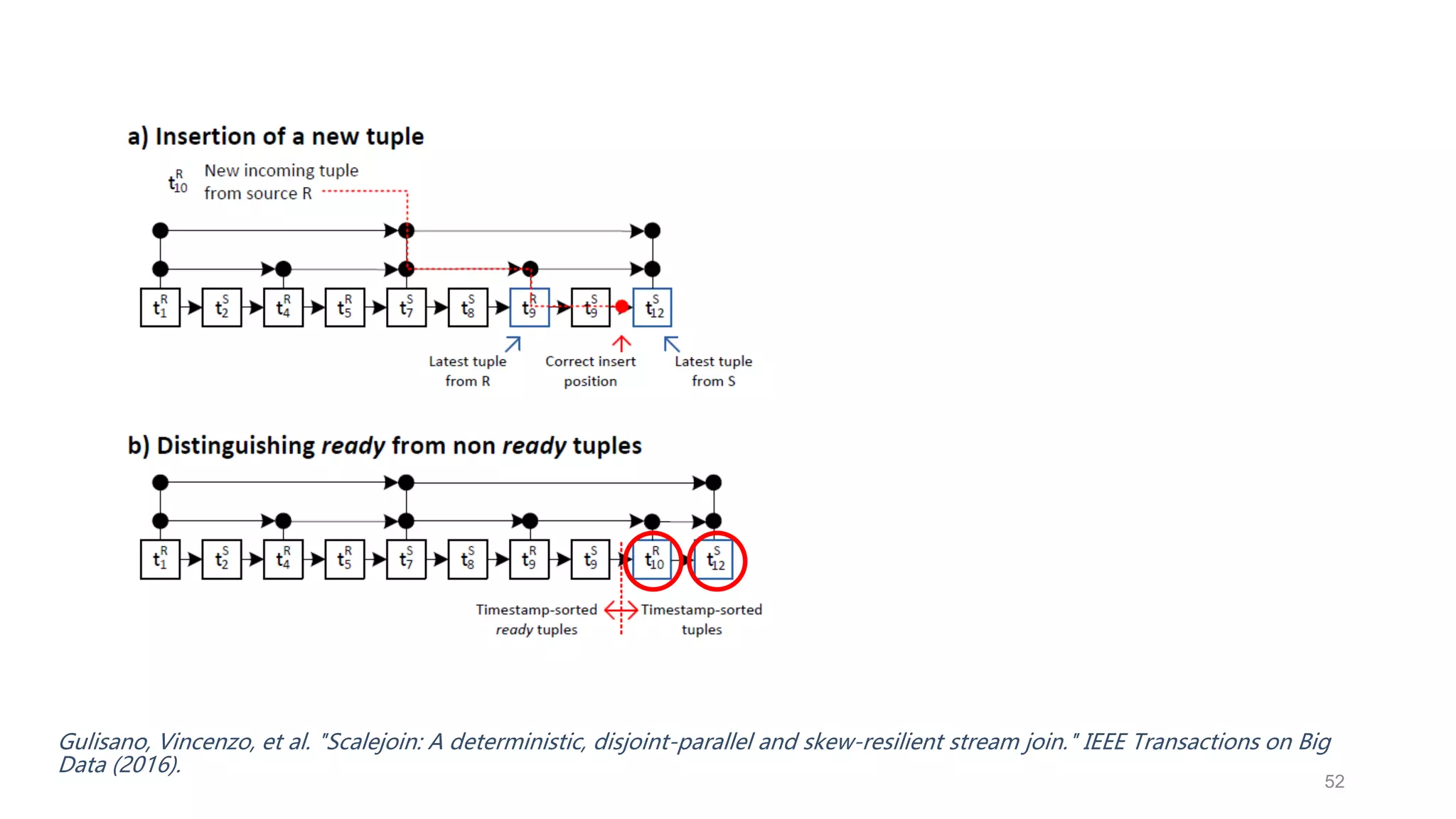








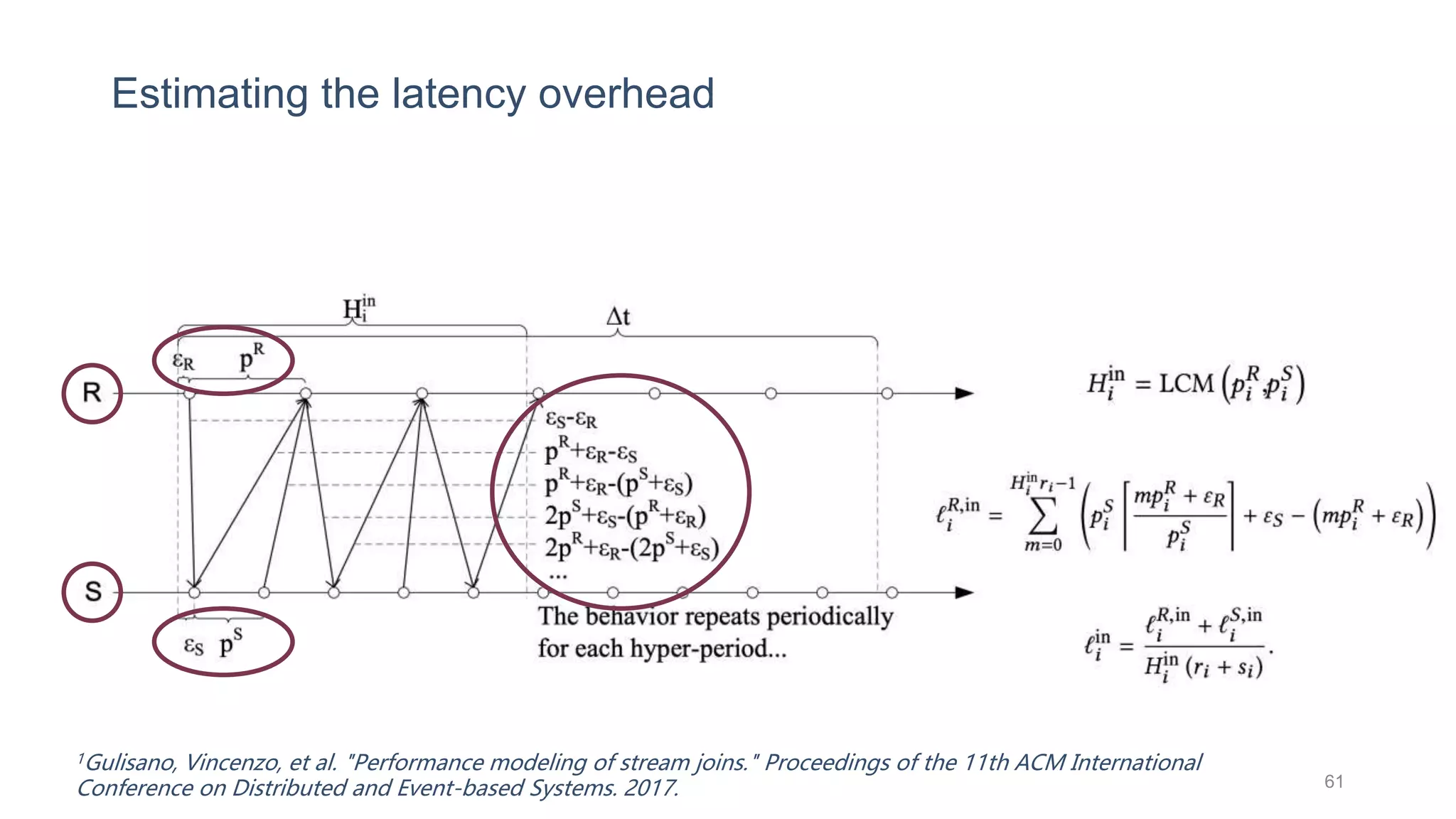

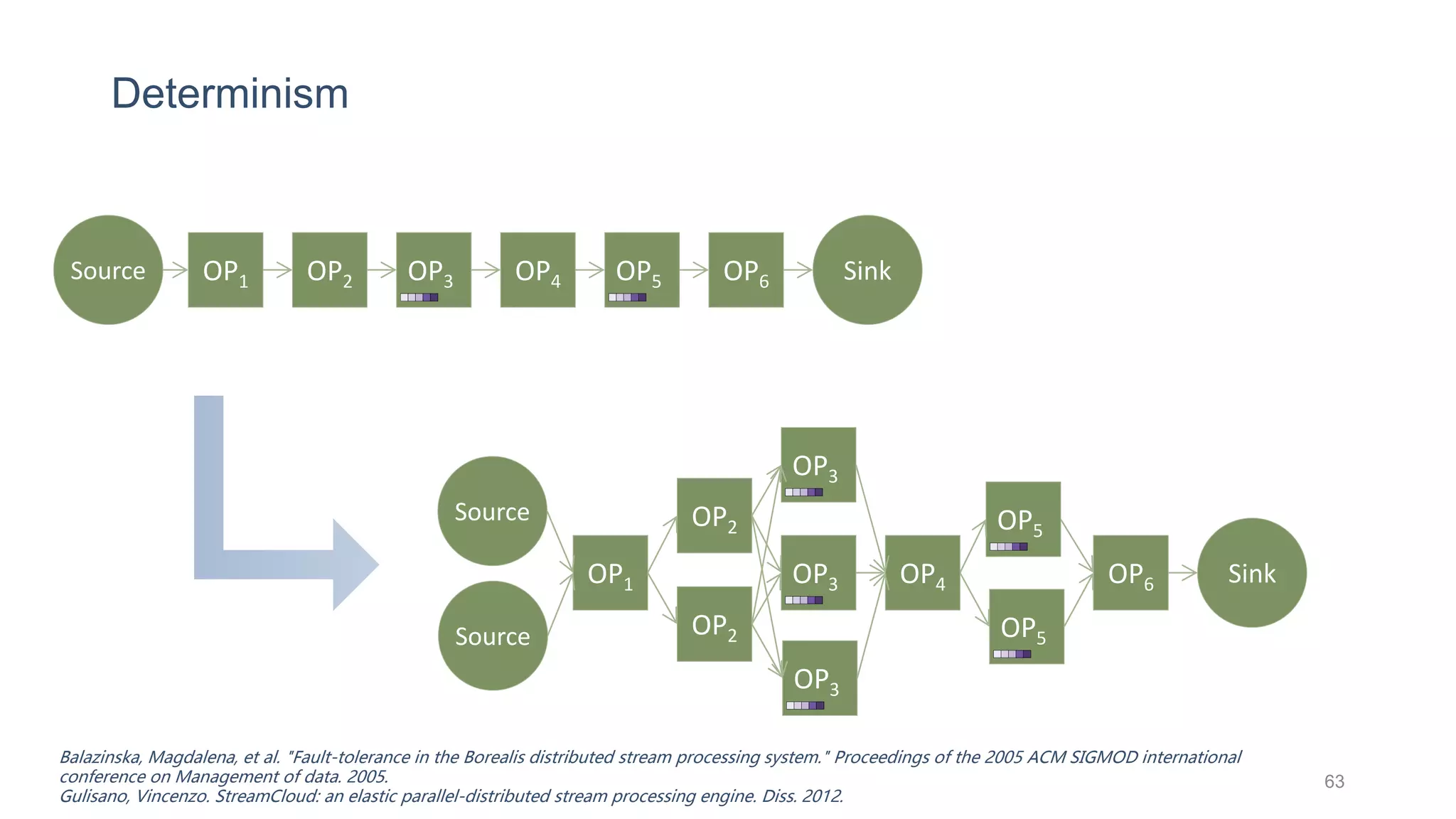
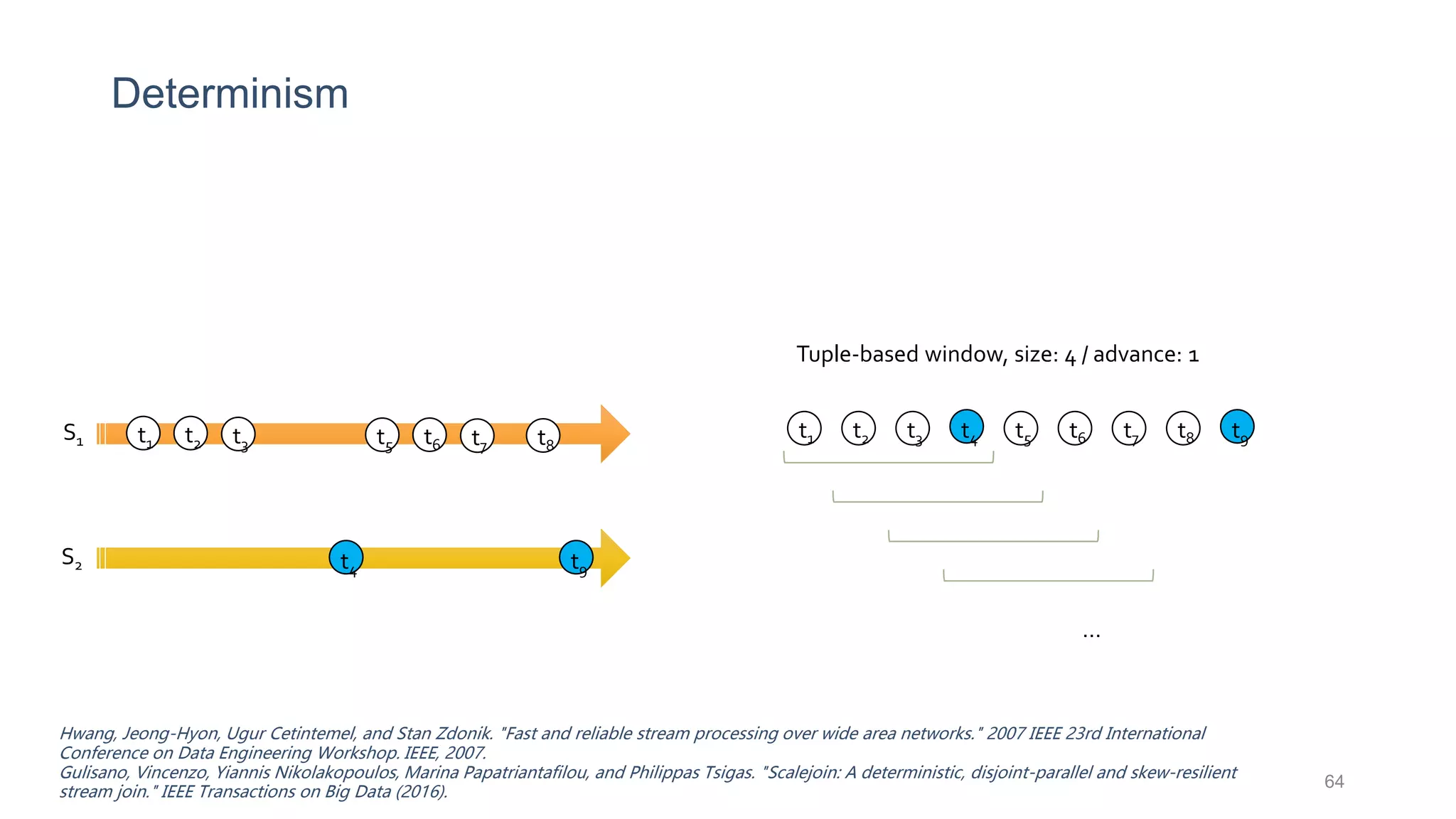

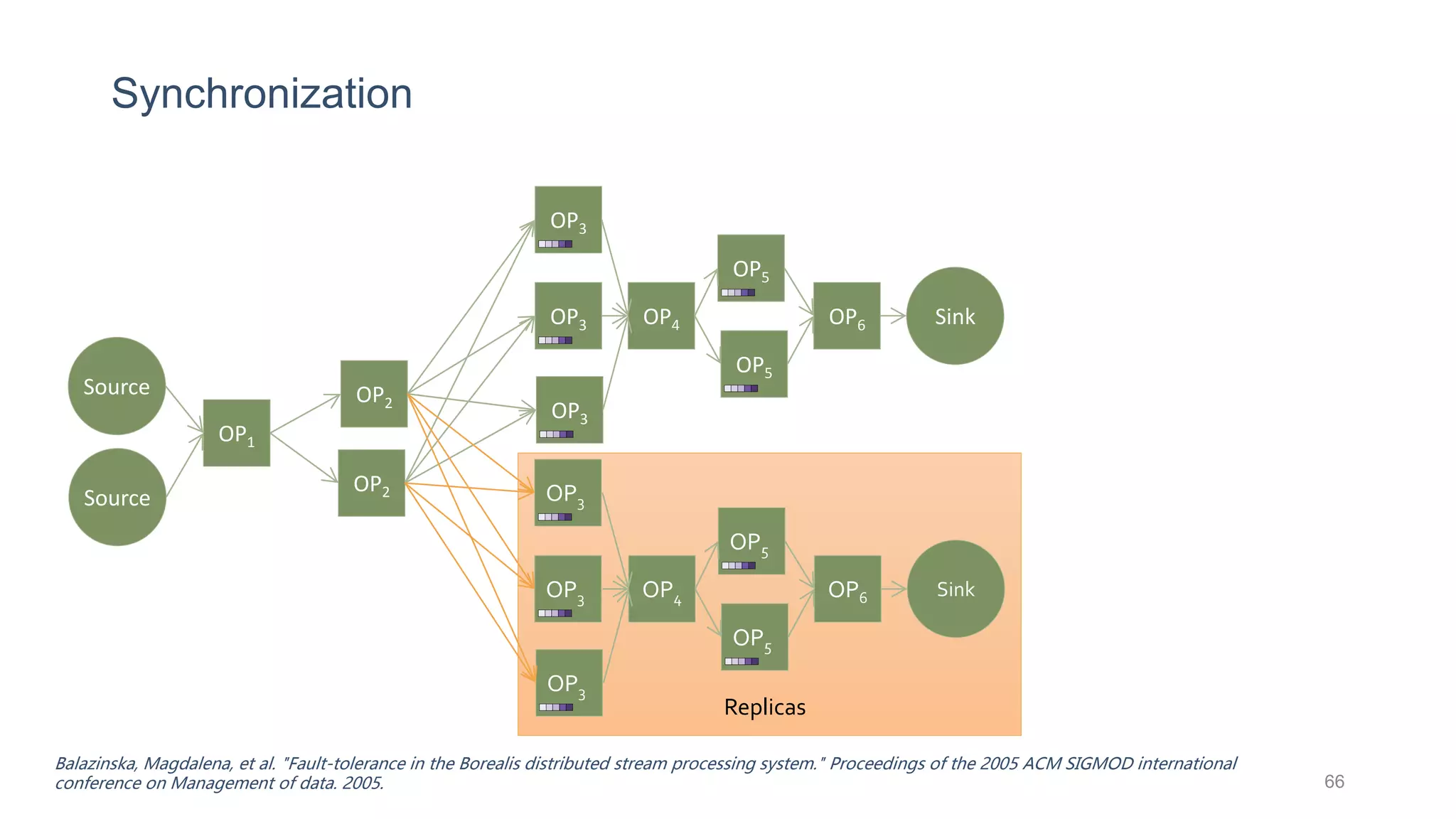
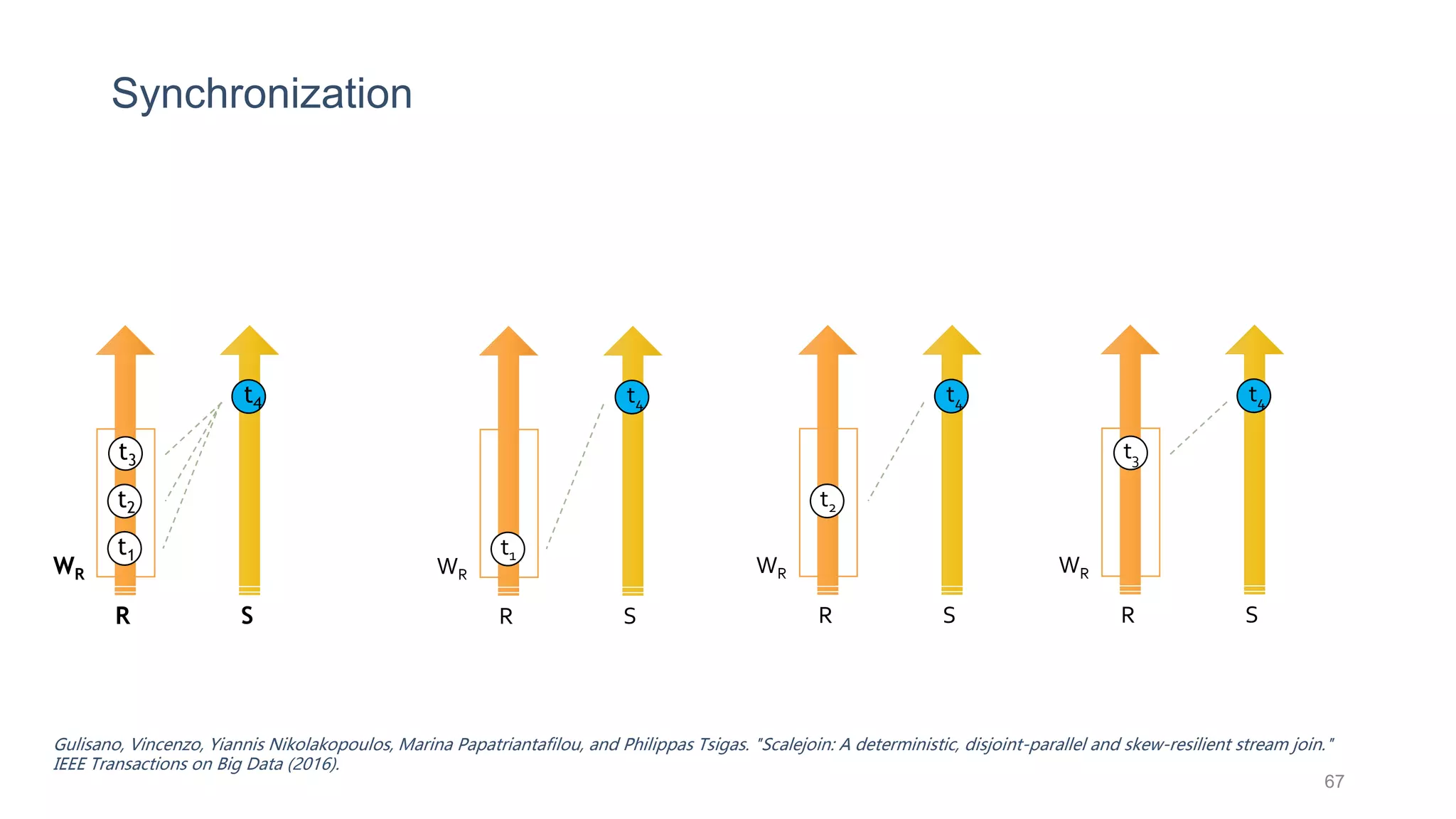
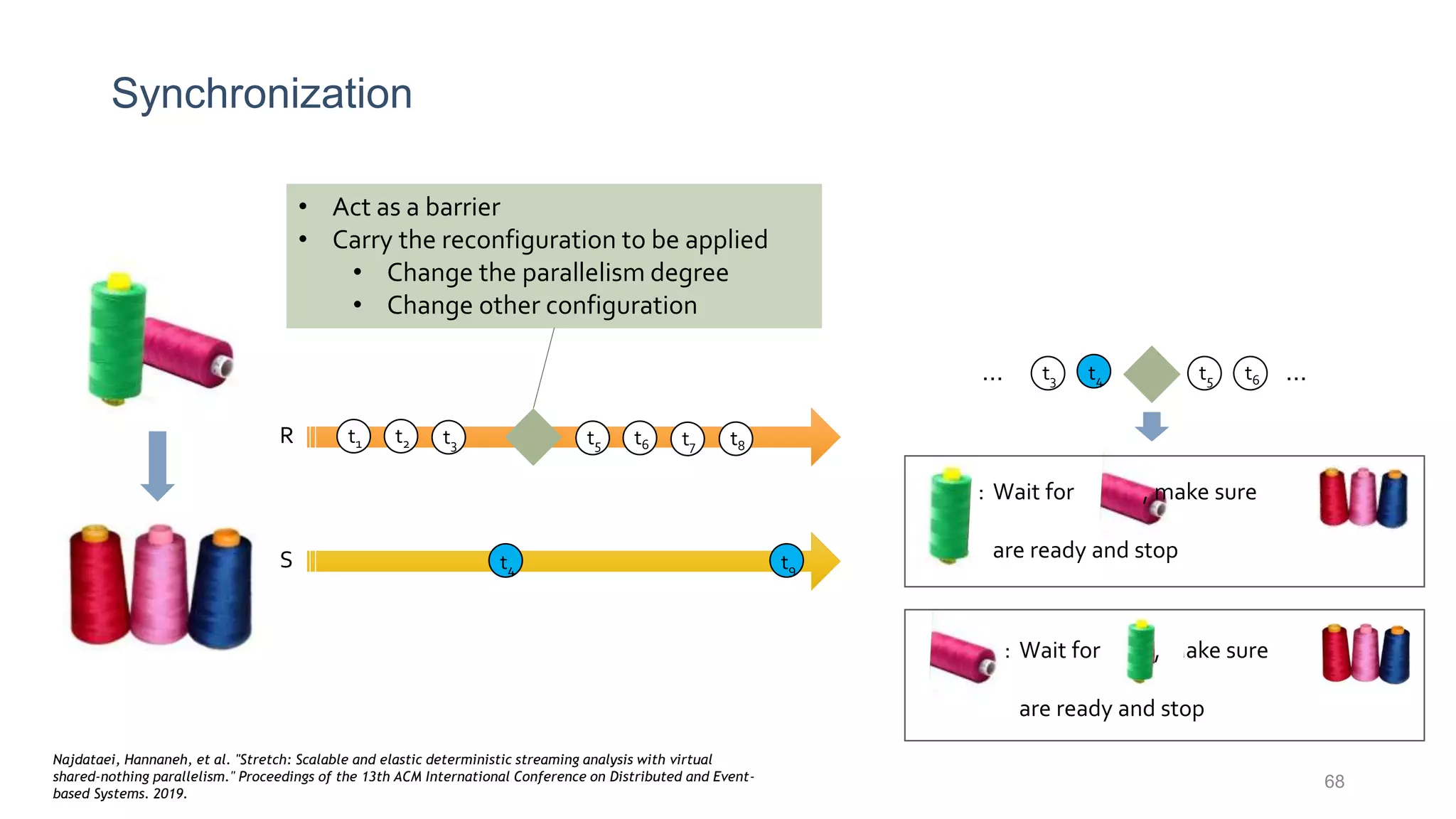

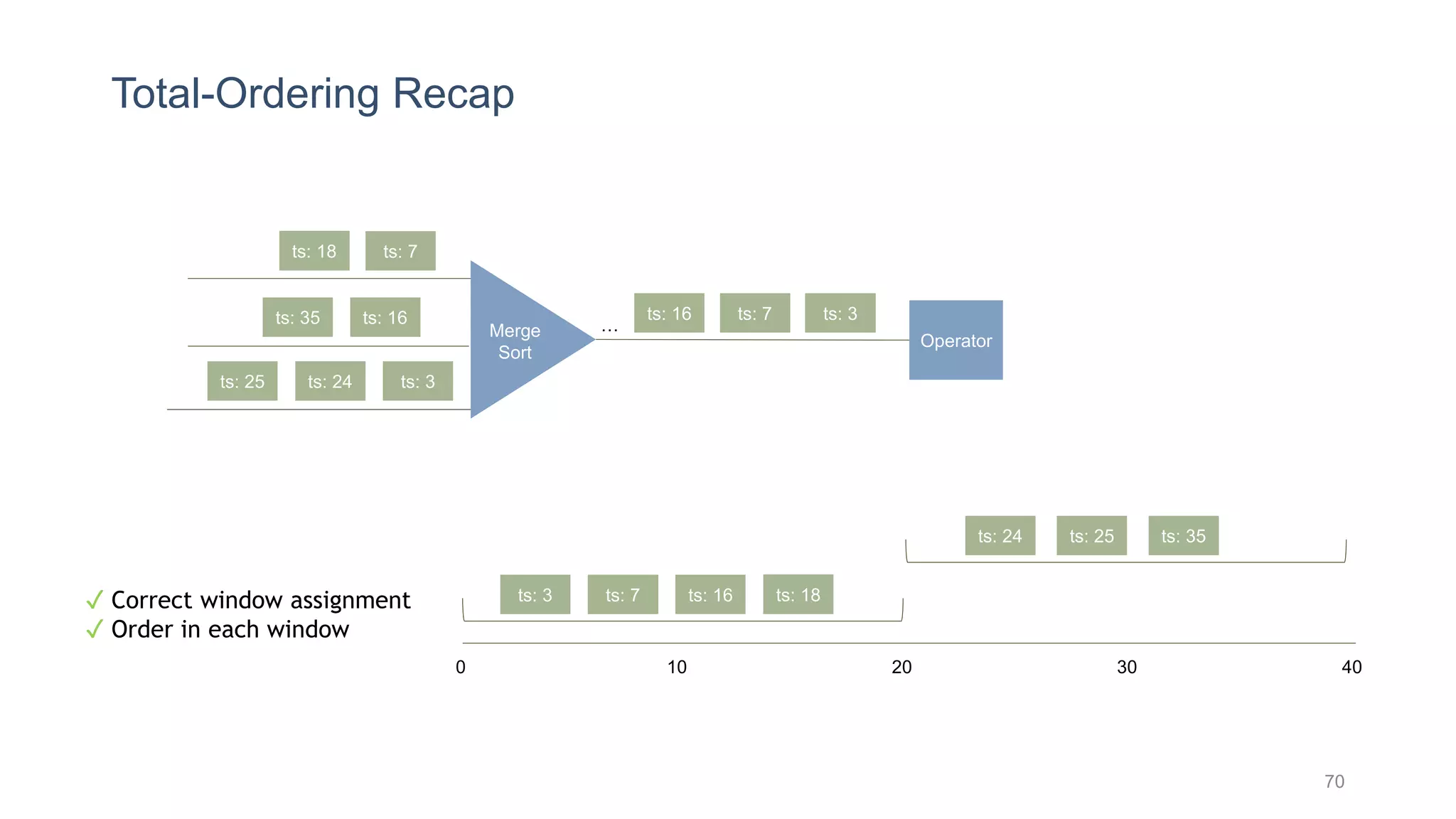
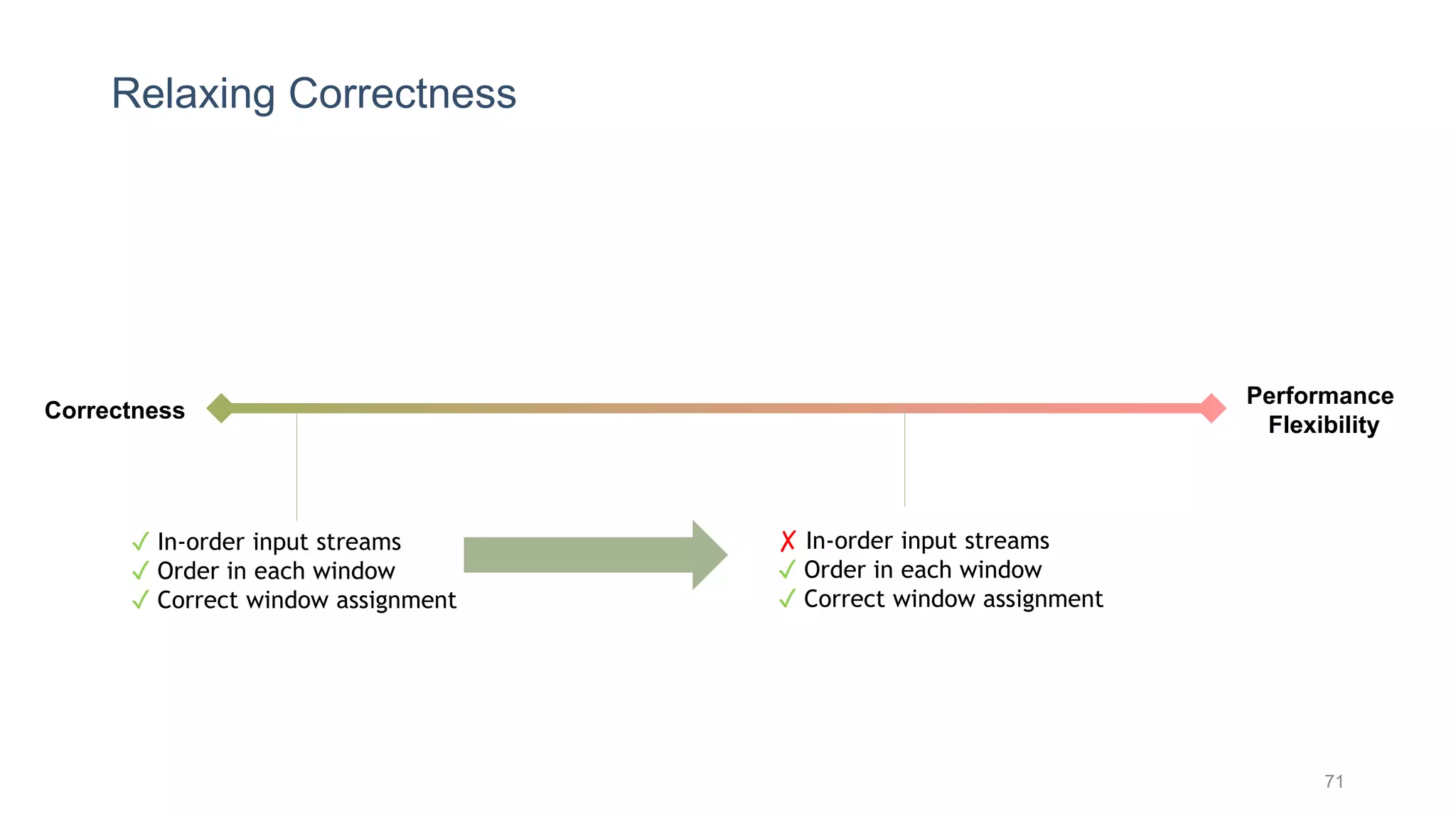
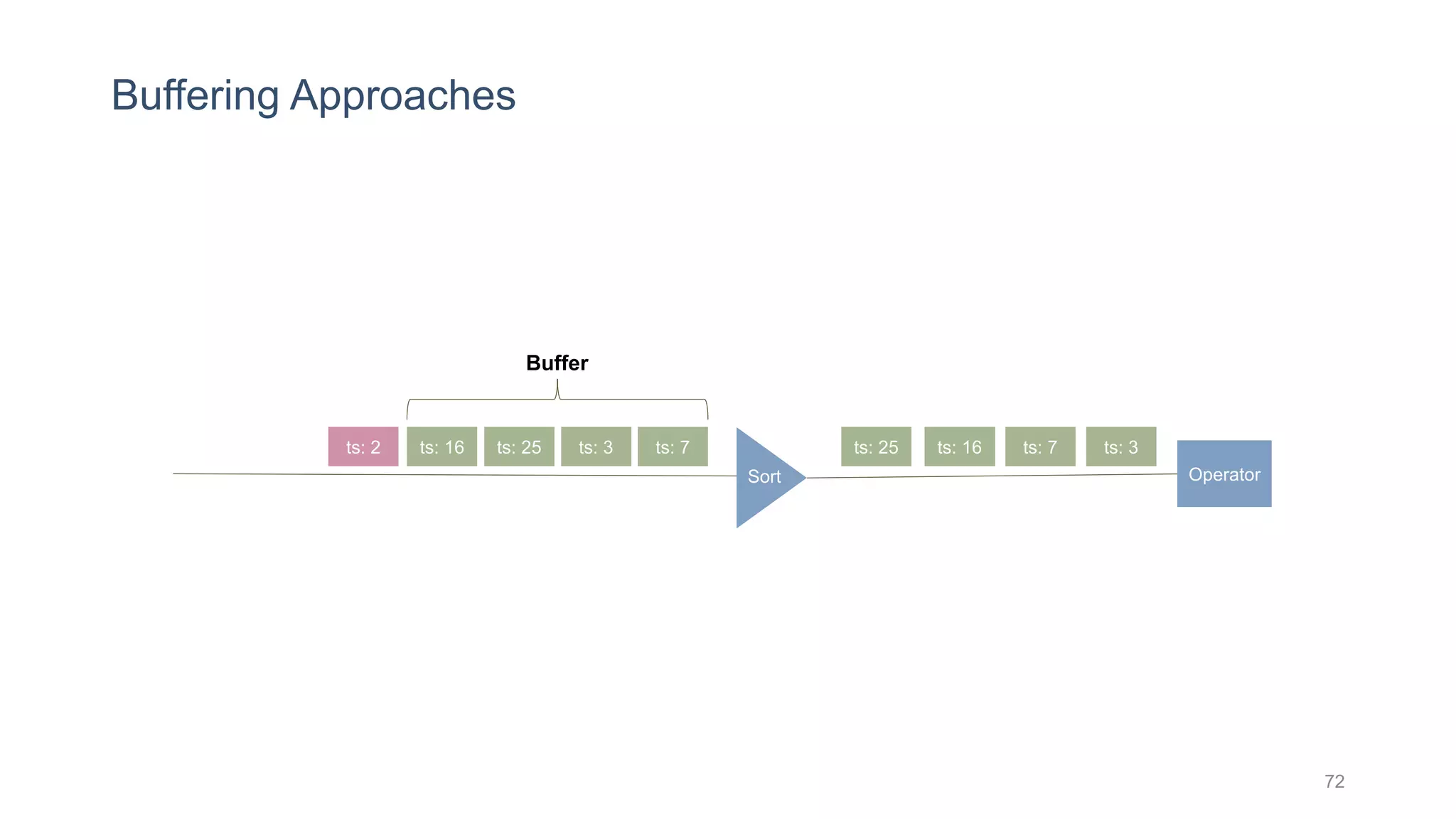
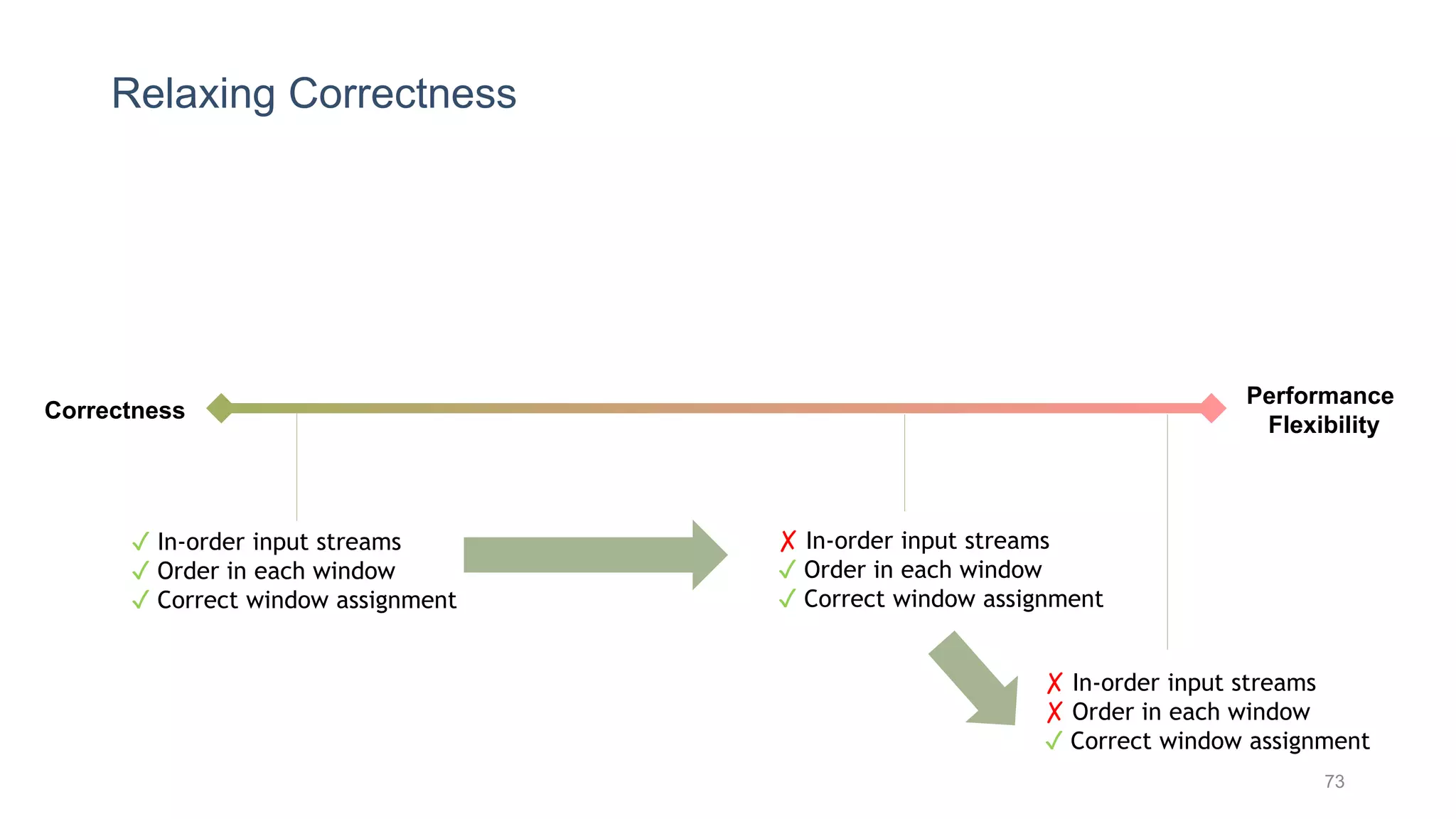
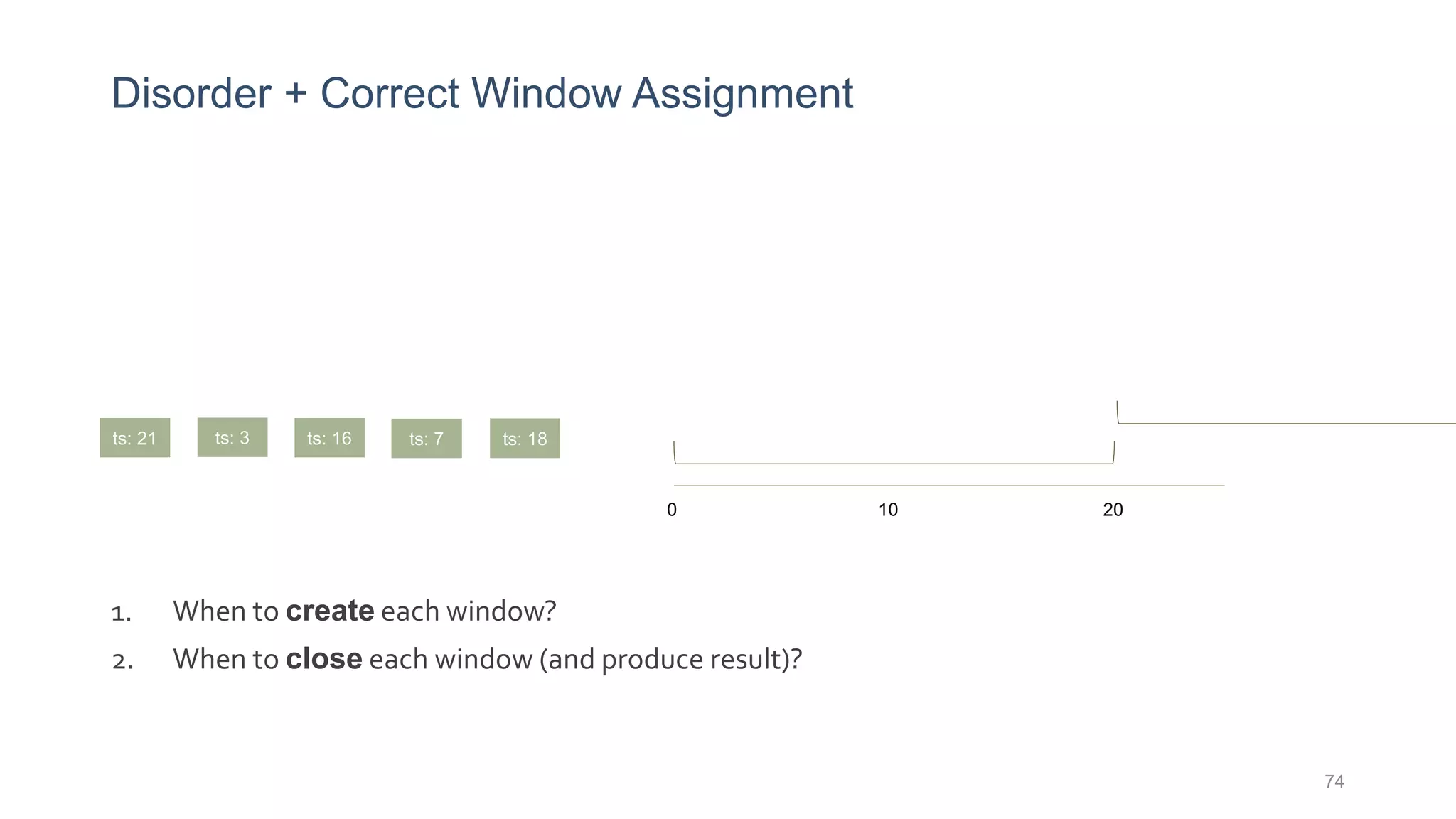

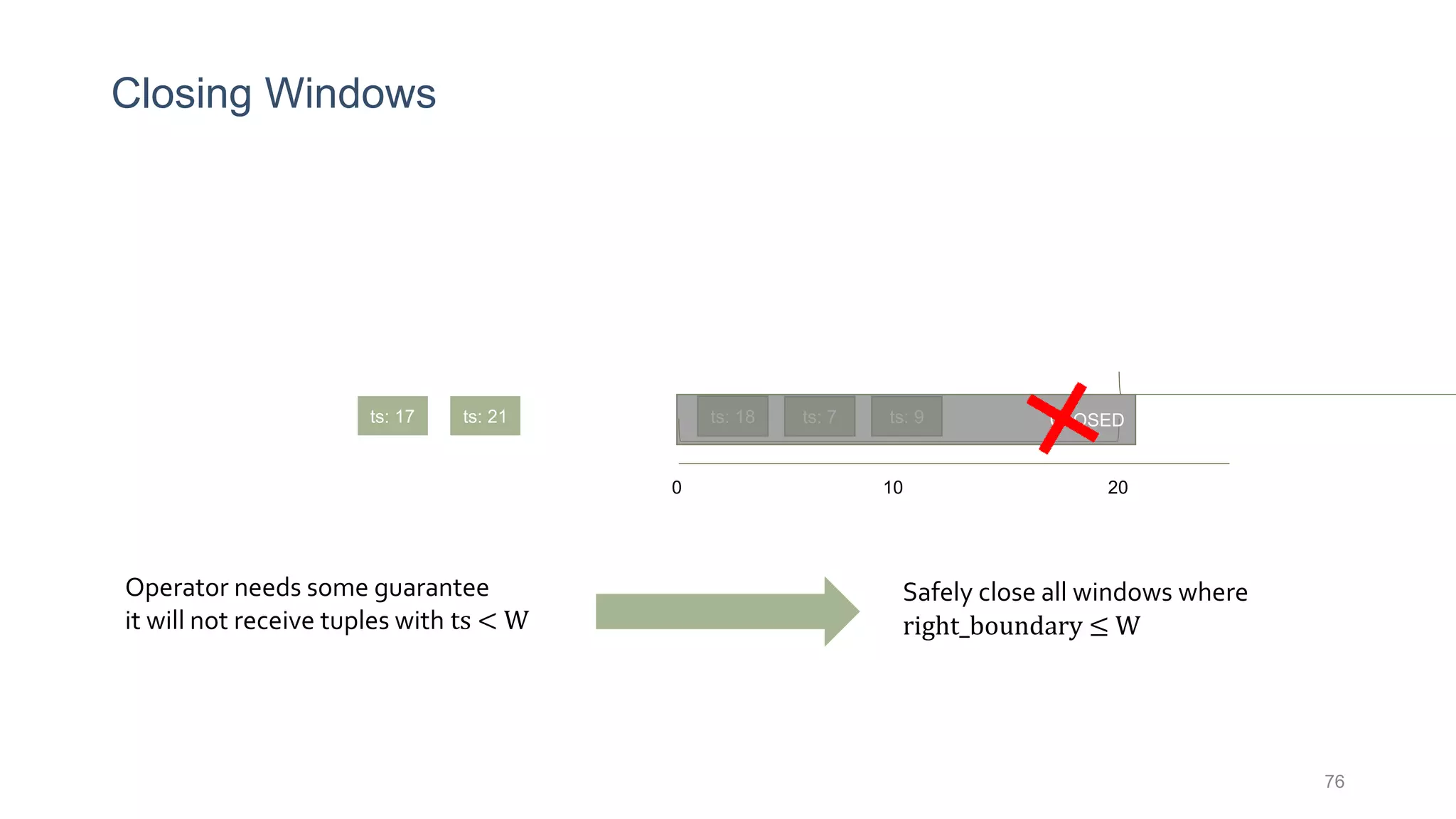

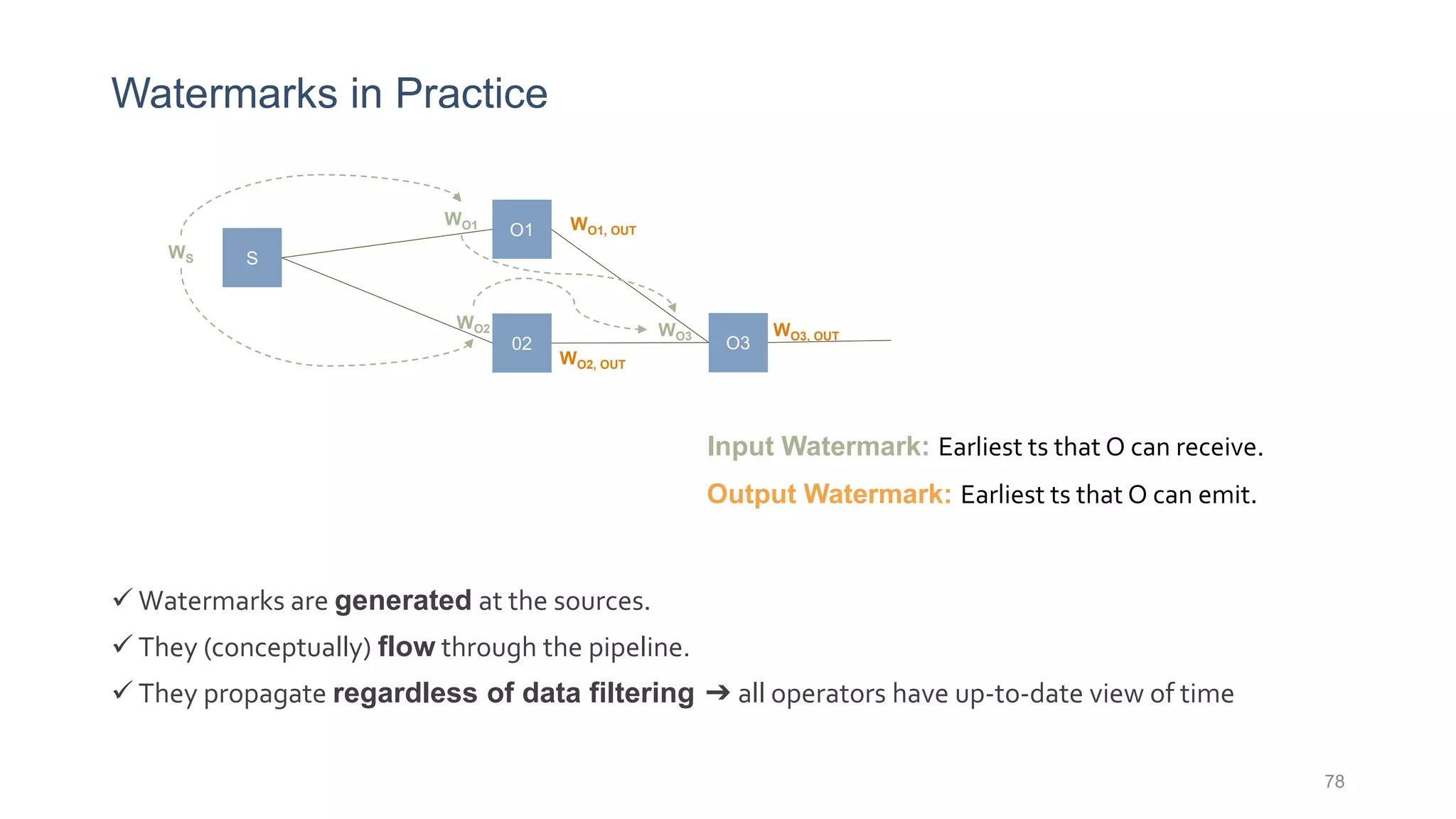
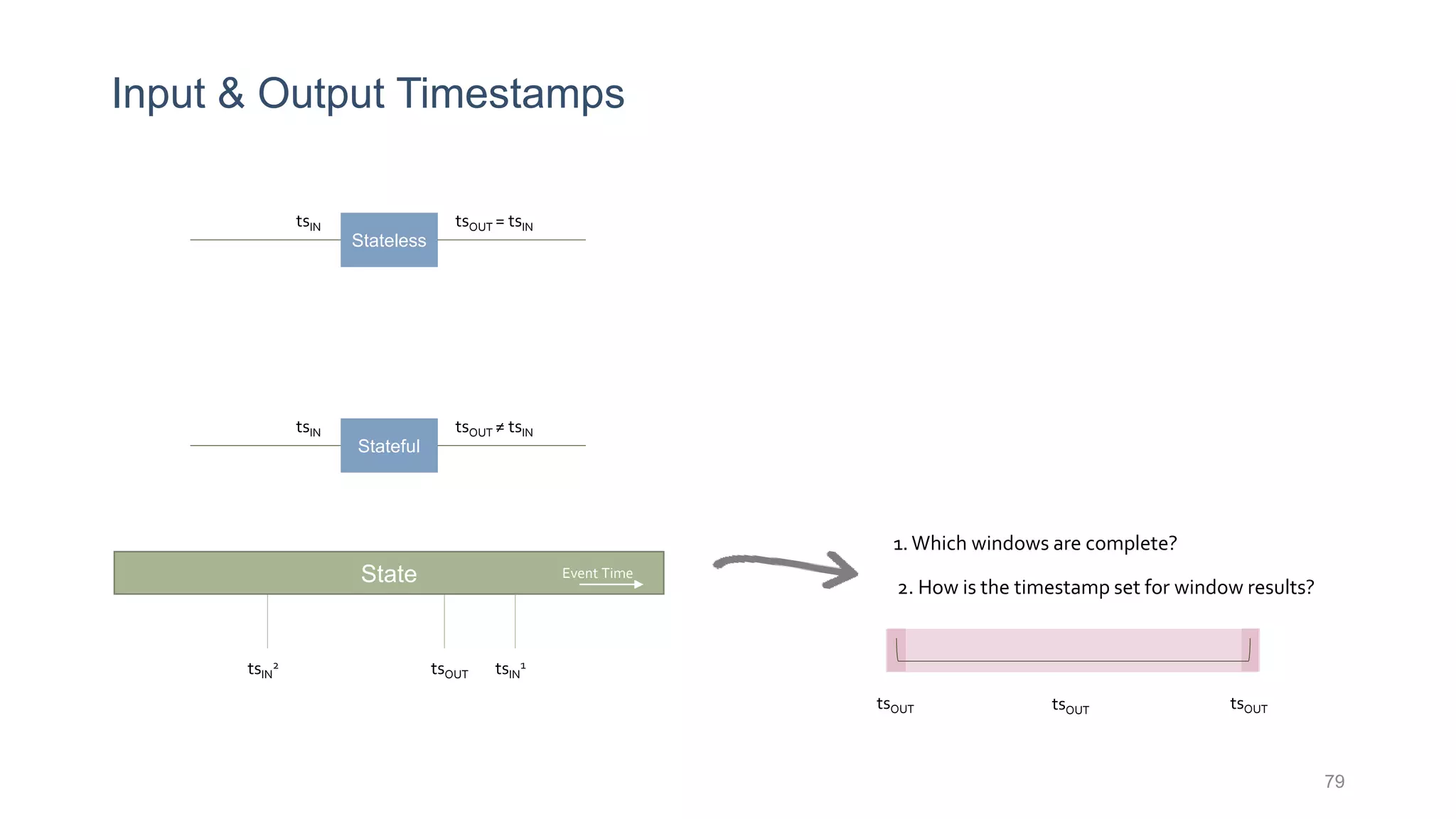
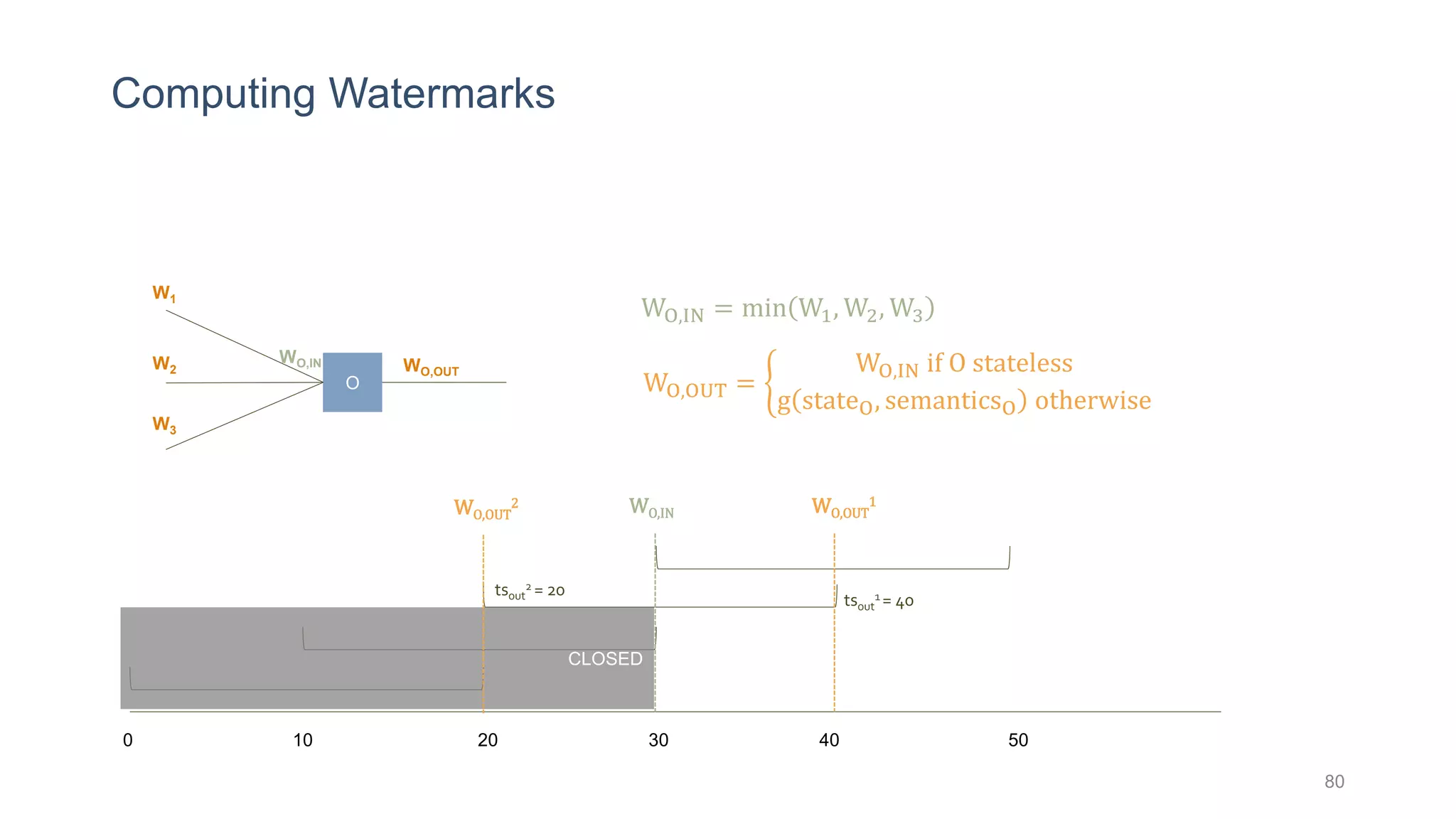
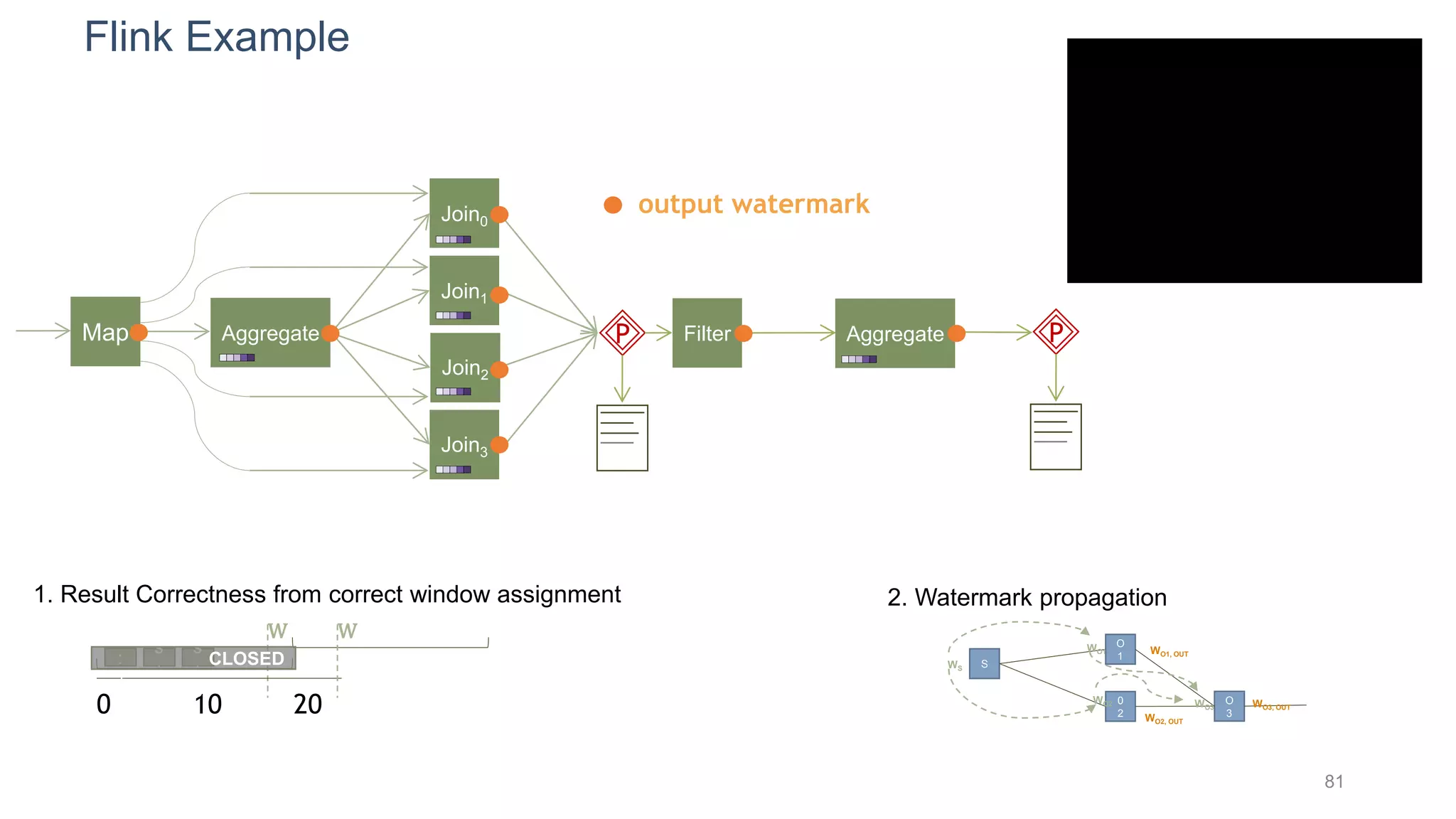

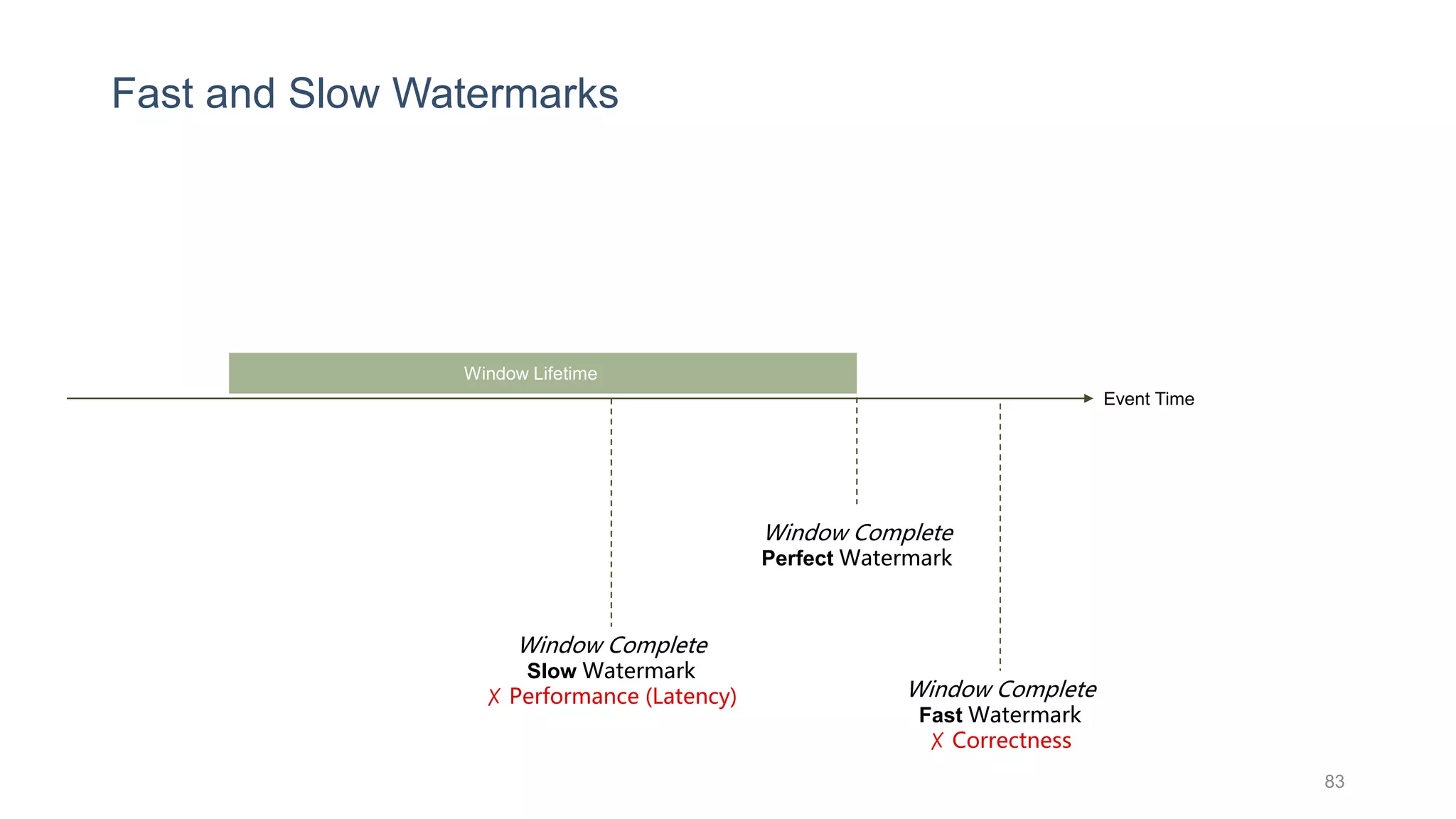
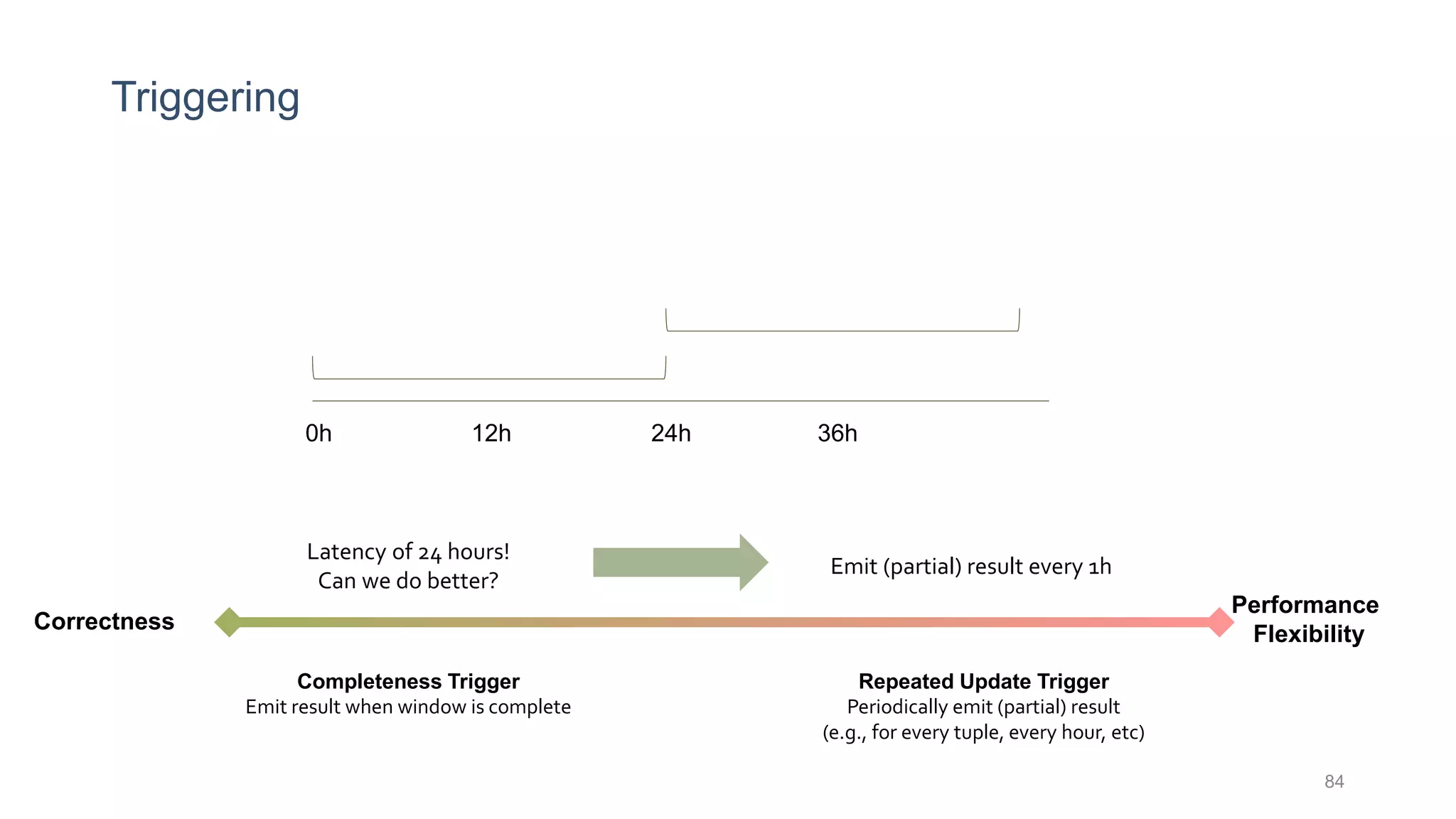
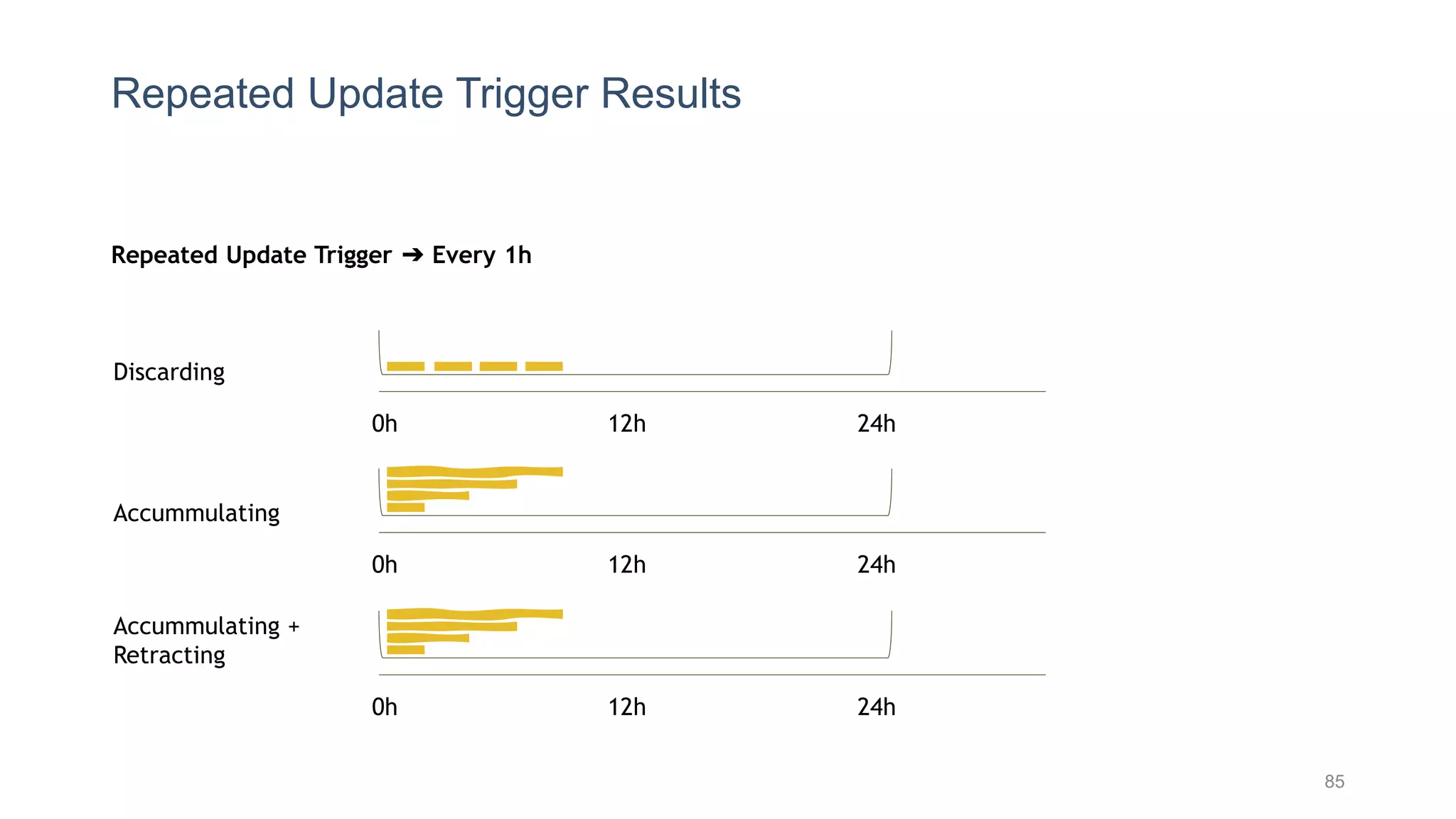
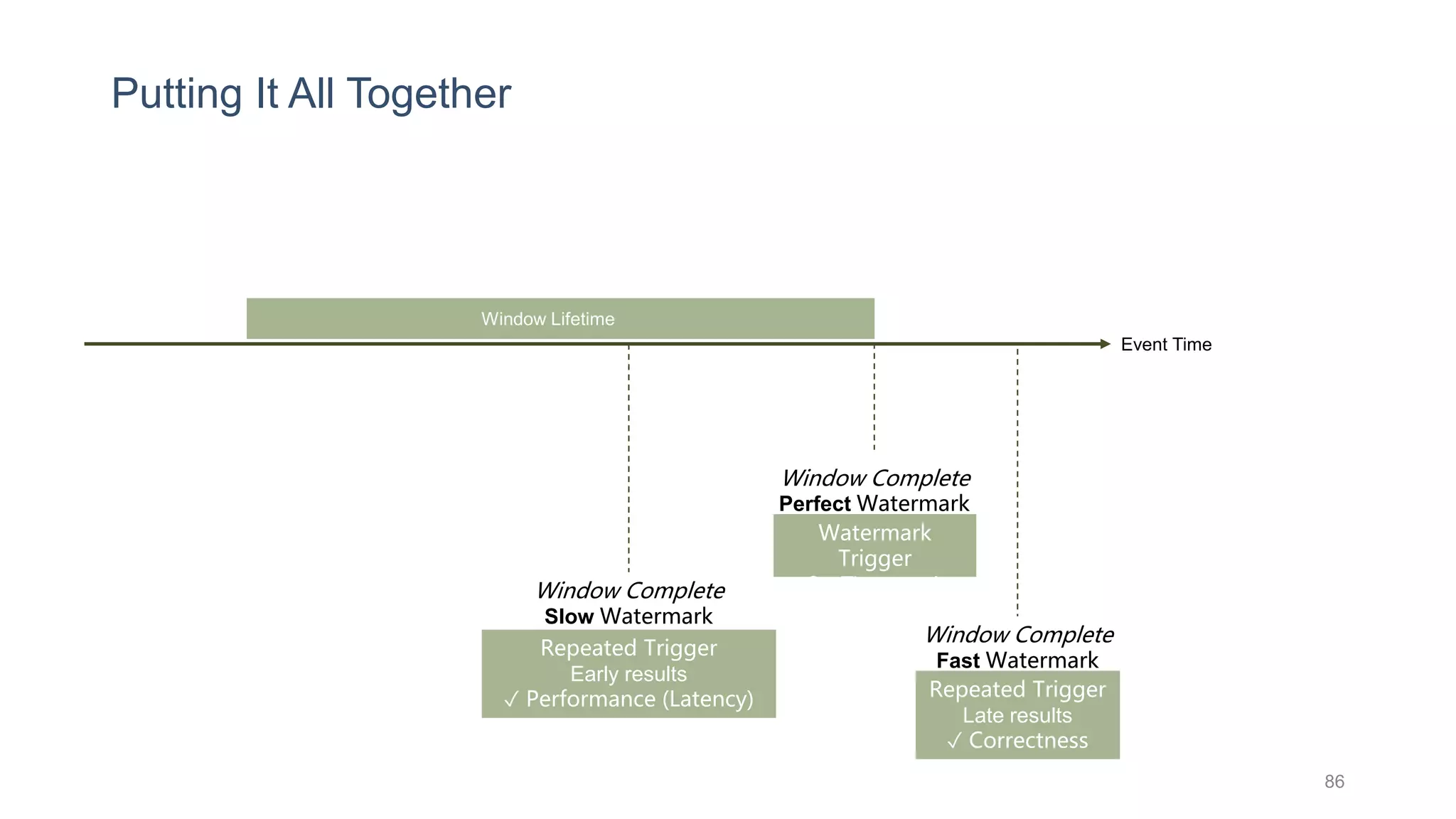

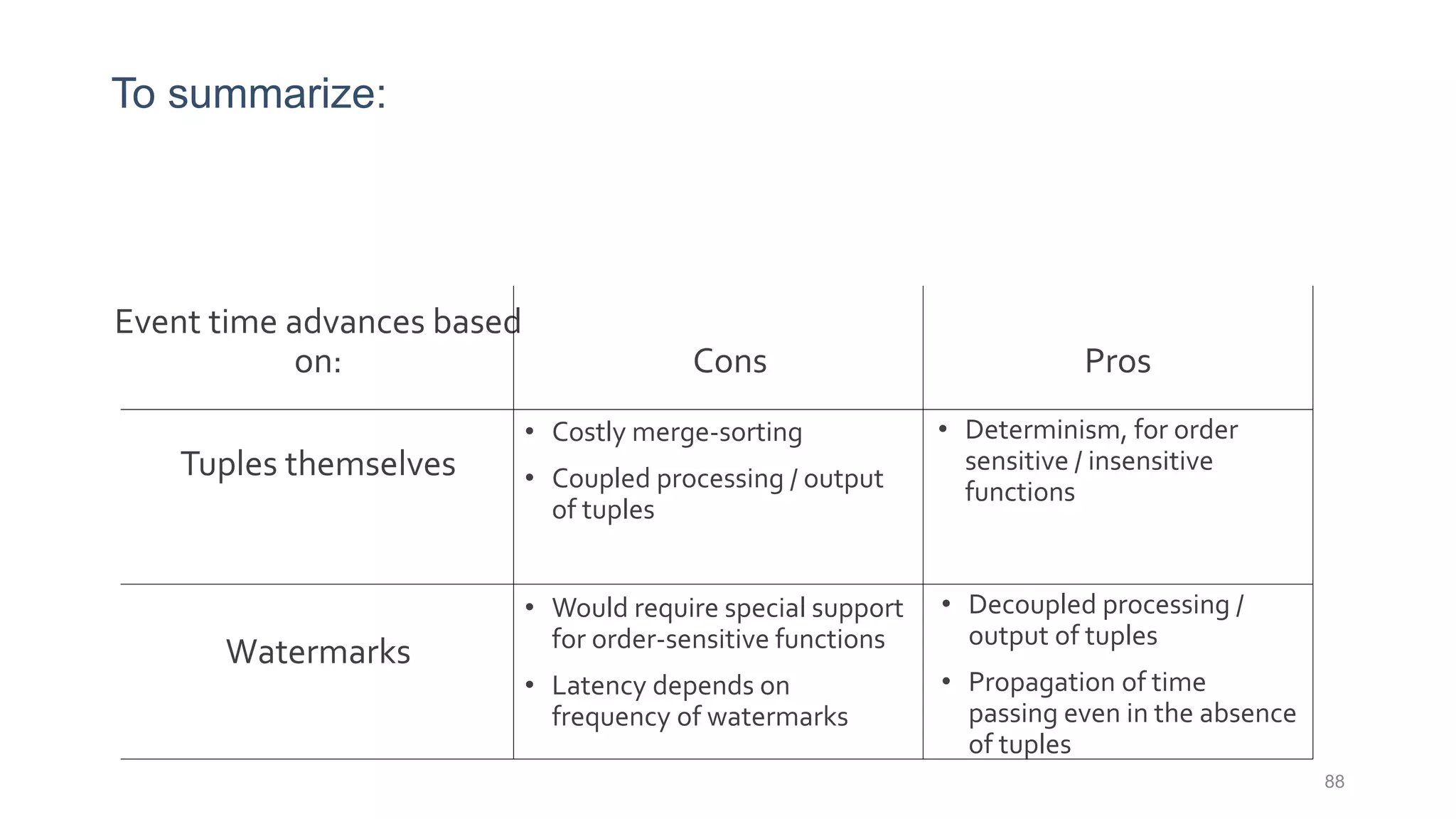


This document provides a tutorial on the role of event-time order in data streaming analysis. The agenda covers motivations and examples of data streaming and stream processing engines, causes of out-of-order data and solutions to enforce total ordering, pros and cons of total ordering, and relaxation of total ordering using watermarks. Enforcing total ordering through techniques like sorting tuples is computationally expensive but provides benefits like determinism and synchronization. However, it may be an overkill for some applications and increase latency.























![[EUC2016] FFWD: latency-aware event stream processing via domain-specific loa...](https://cdn.slidesharecdn.com/ss_thumbnails/ffwd-171206183549-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[ODSC EUROPE 2022] Eagleeye - Data Pipeline for Anomaly Detection in Cyber Se...](https://cdn.slidesharecdn.com/ss_thumbnails/odsceurope2022eagleeye-datapipelineforanomalydetectionincybersecurity-250320161155-77fa6dd8-thumbnail.jpg?width=640&height=640&fit=bounds)























