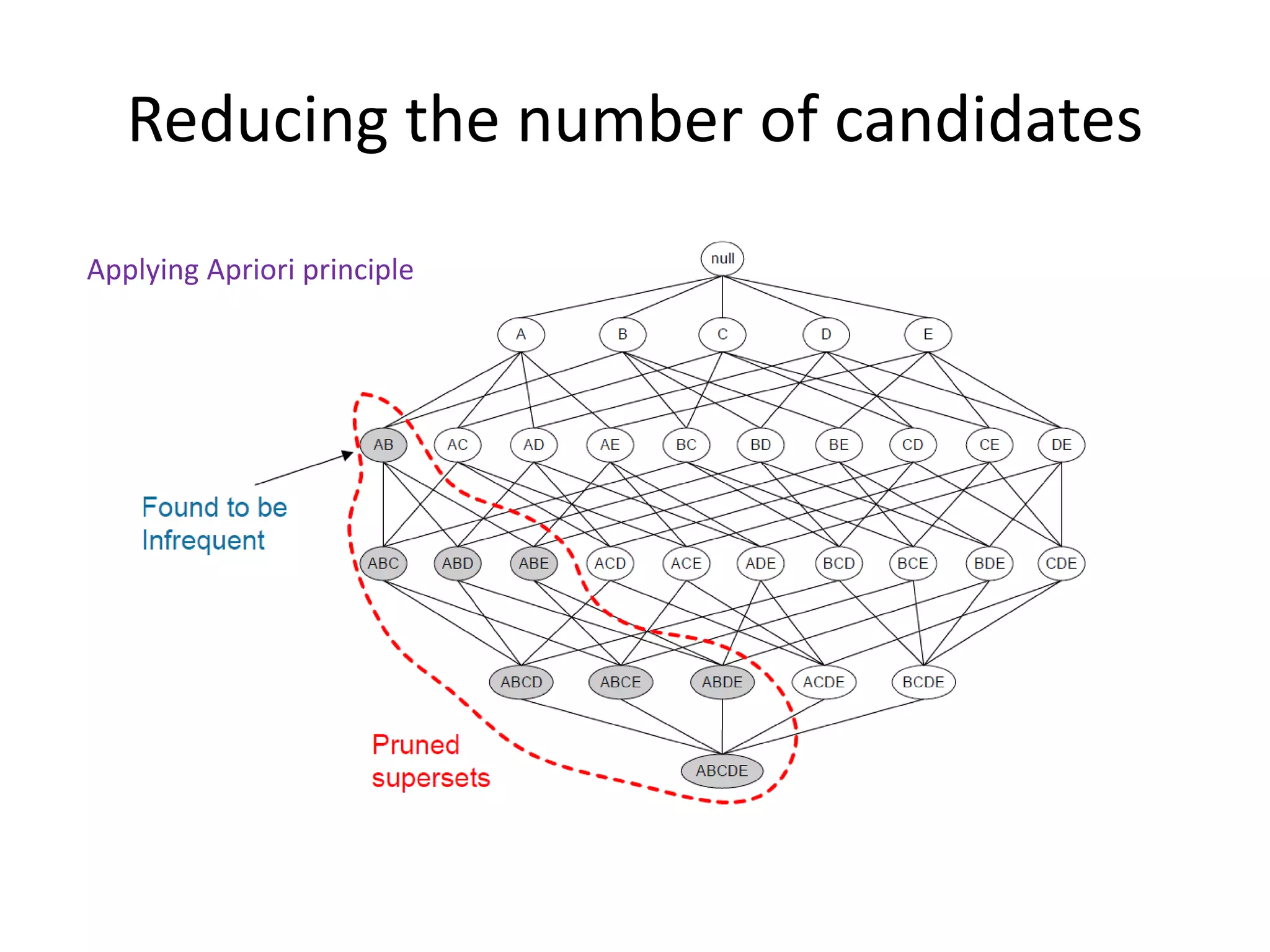
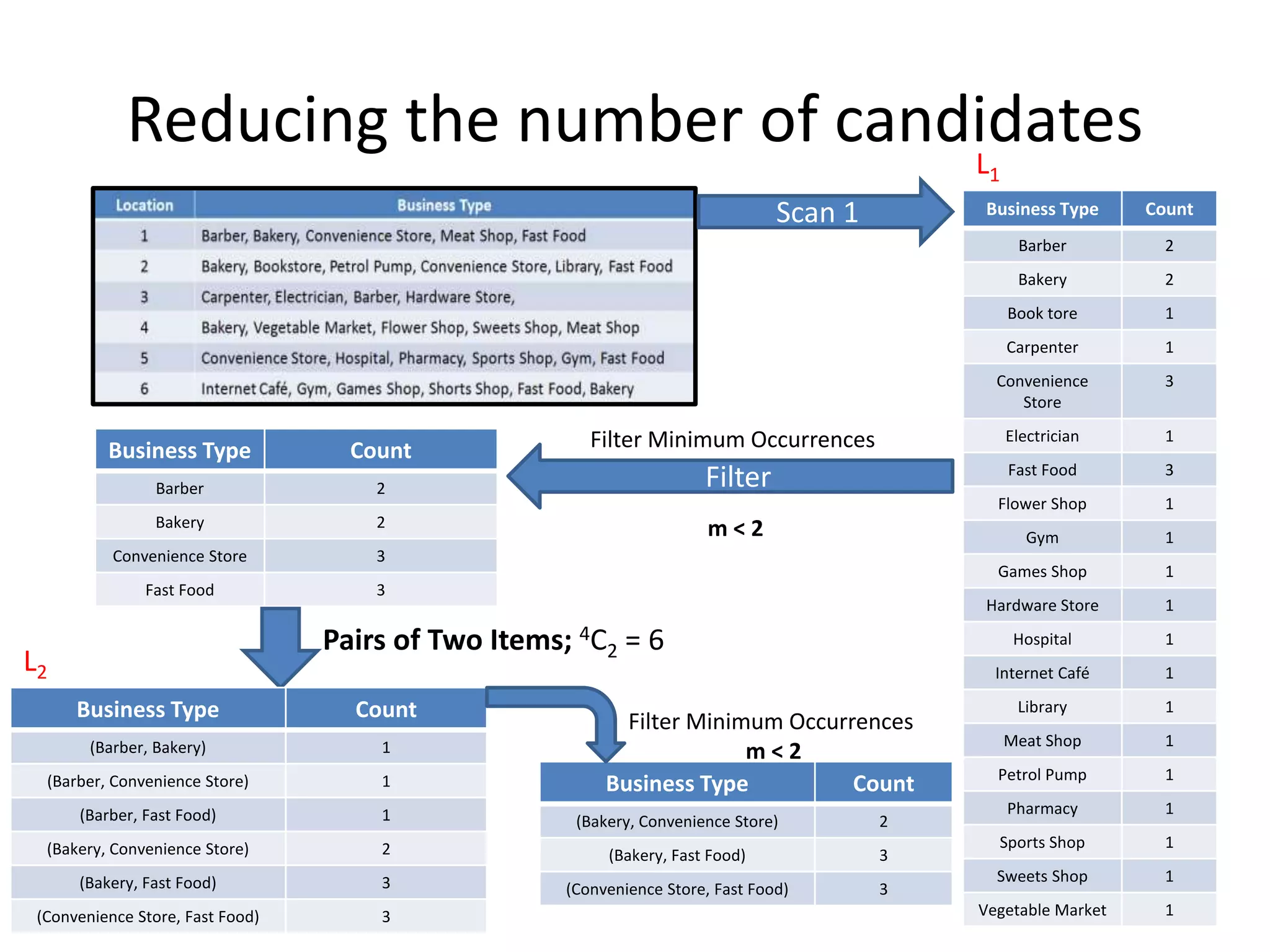
The document discusses association rule mining to discover relationships between data items in large datasets. It describes how association rules have the form of X → Y, showing items that frequently occur together. The key steps are: (1) generating frequent itemsets whose support is above a minimum threshold; (2) extracting high-confidence rules from each frequent itemset. It proposes using the Apriori algorithm to efficiently find frequent itemsets by pruning the search space based on the antimonotonicity of support.



![Association Analysis
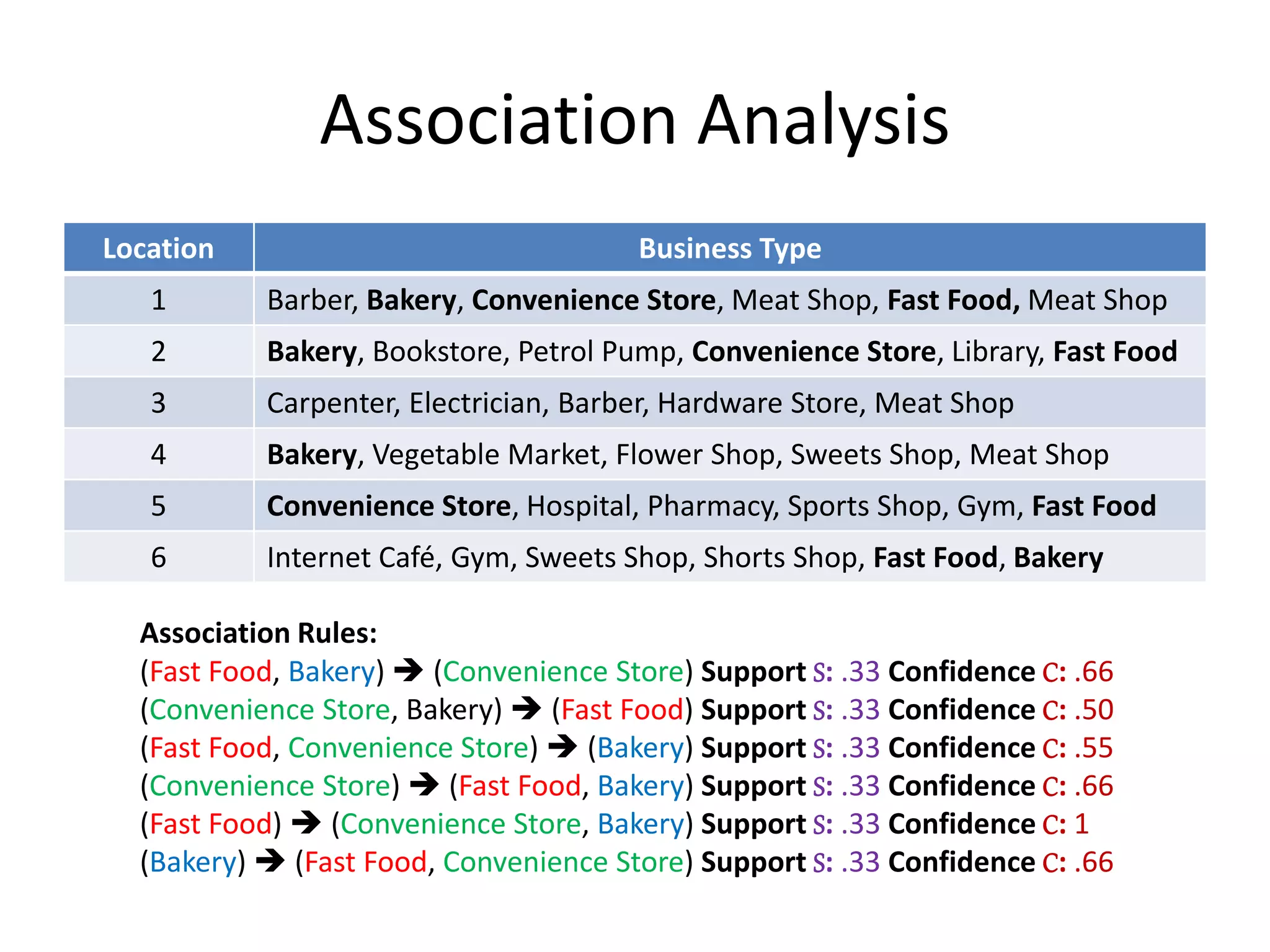
Location Business Type
1 Barber, Bakery, Convenience Store, Meat Shop, Fast Food
2 Bakery, Bookstore, Petrol Pump, Convenience Store, Library, Fast Food
3 Carpenter, Electrician, Barber, Hardware Store,
4 Bakery, Vegetable Market, Flower Shop, Sweets Shop, Meat Shop
5 Convenience Store, Hospital, Pharmacy, Sports Shop, Gym, Fast Food
6 Internet Café, Gym, Games Shop, Shorts Shop, Fast Food, Bakery
Association Rule: X Y ; (Fast Food, Bakery) (Convenience Store)
Support S: Fraction of items that contain both X and Y = P(X U Y)
S(Fast Food, Bakery, Convenience Store) = 2/6 = .33
Confidence C: how often items in Y appear in locations that contain X = P(X U Y)
C[(Fast Food, Bakery) (Convenience Store)] = P(X U Y) / P(X)
= 0.33/0.50 = .66](https://image.slidesharecdn.com/associationrulemining-160921041756/75/Association-Rule-Mining-in-Data-Mining-4-2048.jpg)