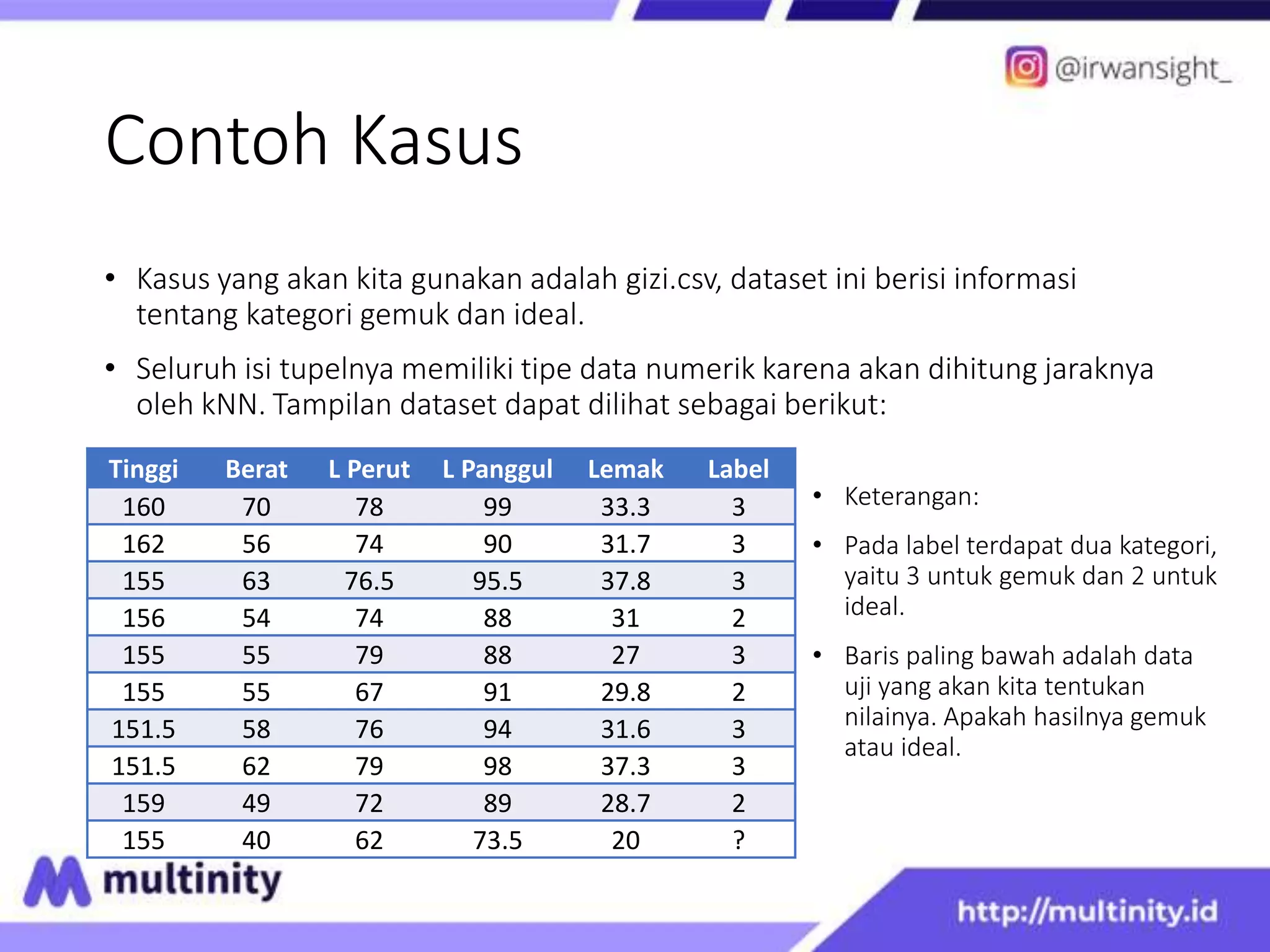
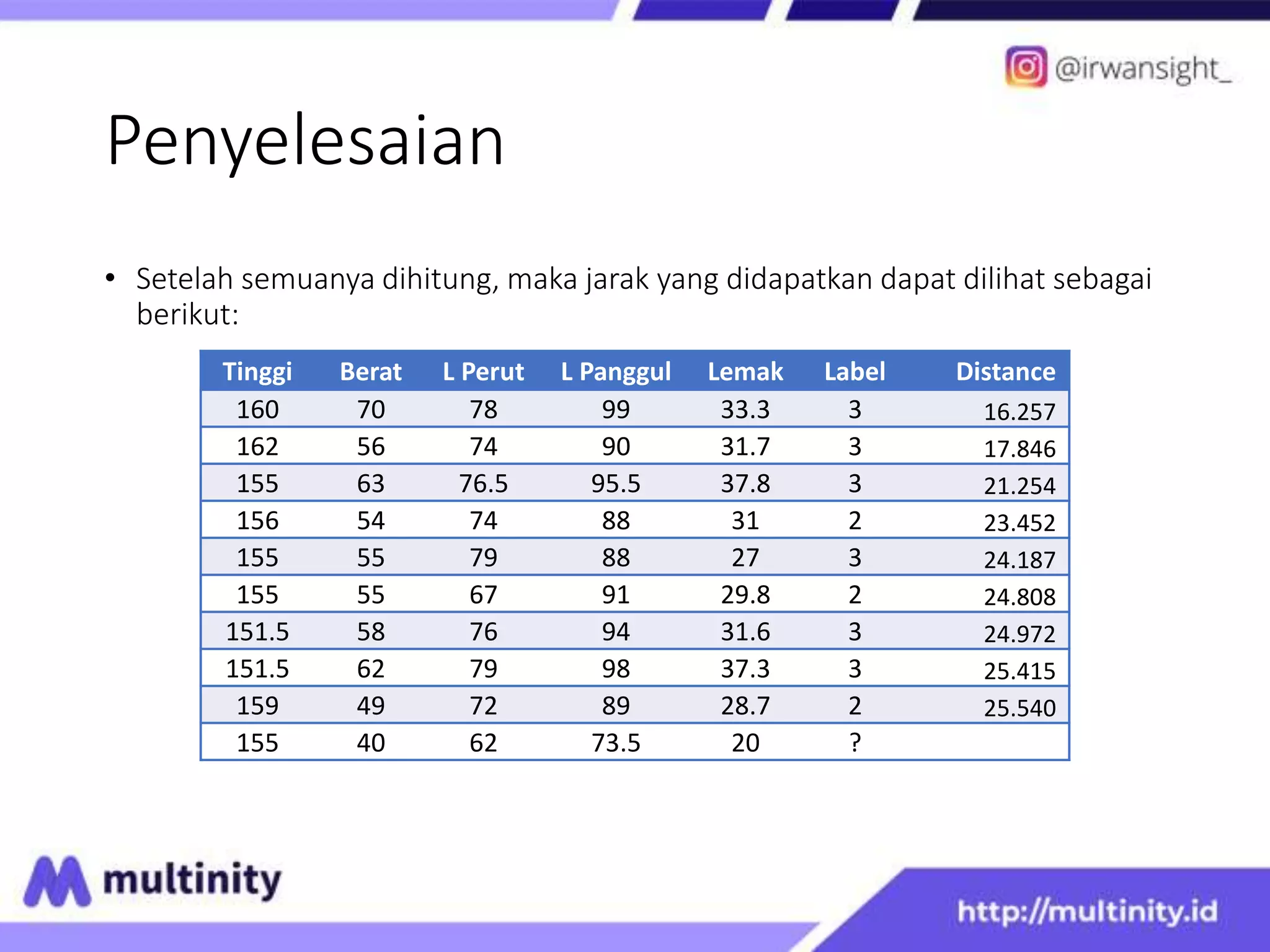
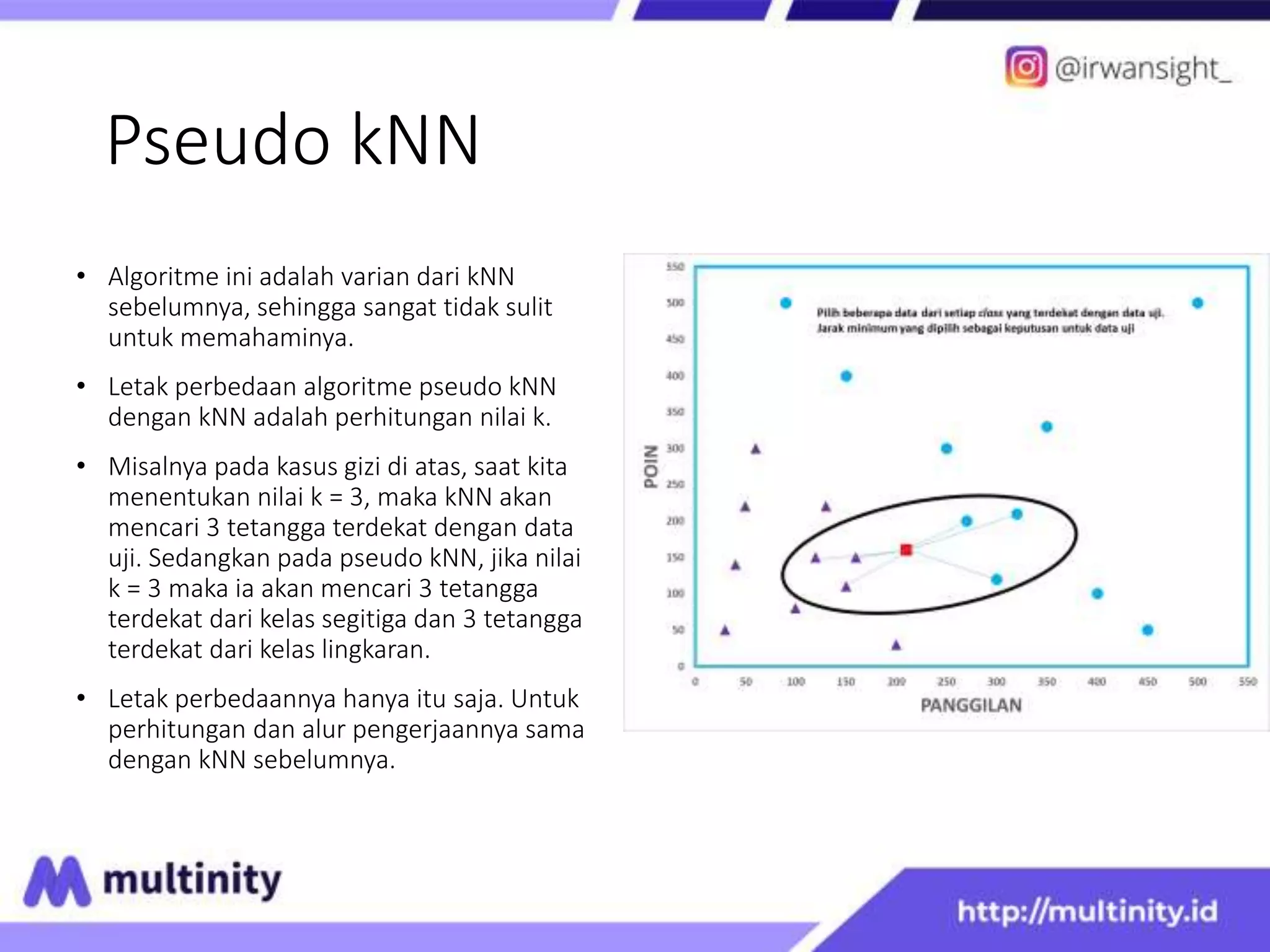
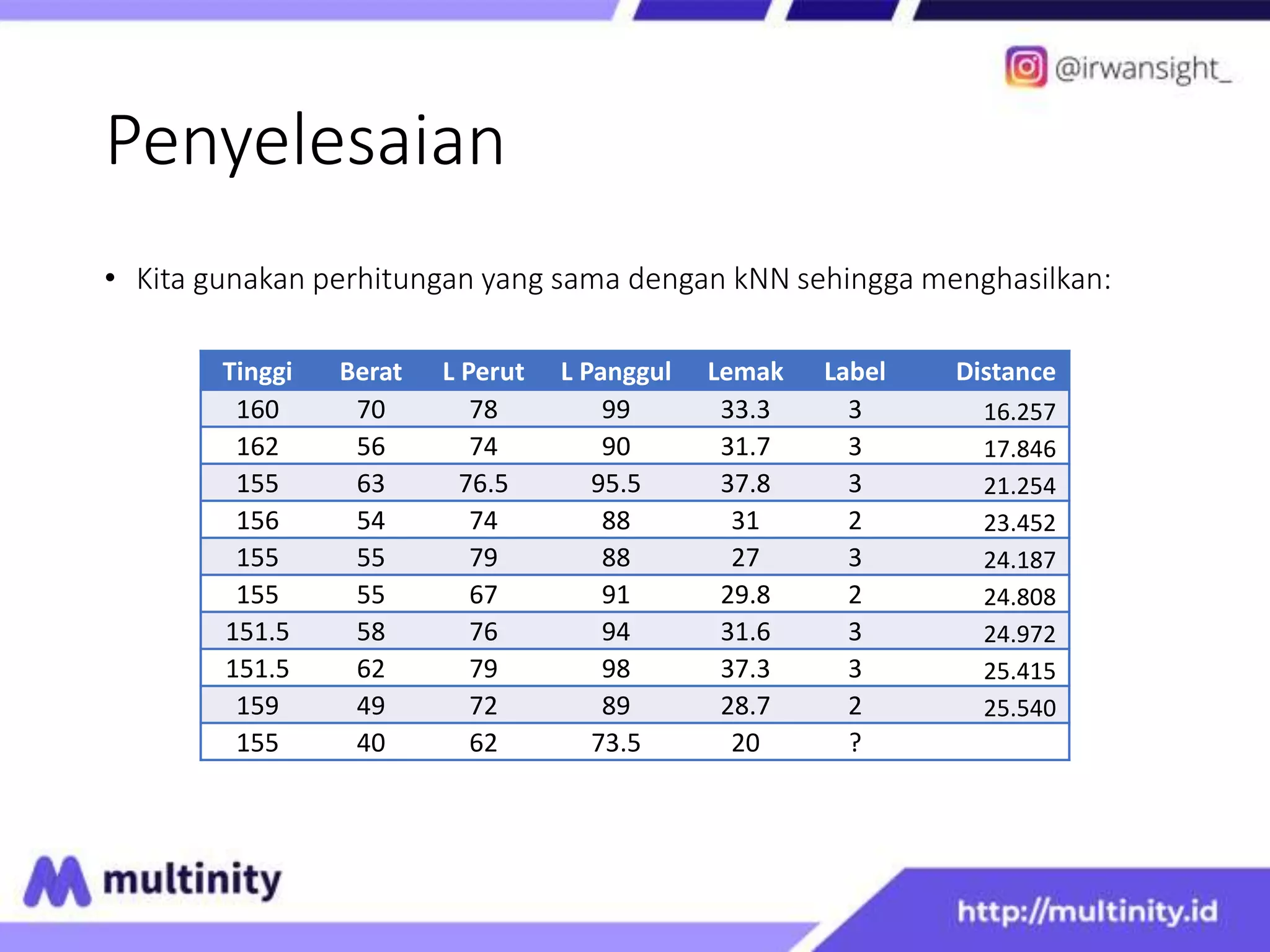
This document discusses K Nearest Neighbor and Pseudo kNN algorithms. It begins with an introduction to KNN, explaining that KNN classifies new data based on the labels of the K nearest neighbors. It then provides an example using a nutrition dataset to classify a new data point as either obese or ideal. For KNN, it calculates the distances to each data point and determines the label based on the labels of the K closest points. Pseudo KNN is similar but considers the K closest points within each class separately before determining the overall label.