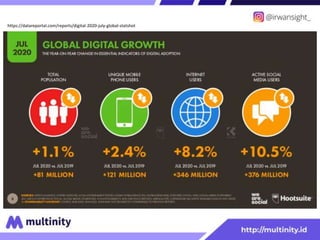
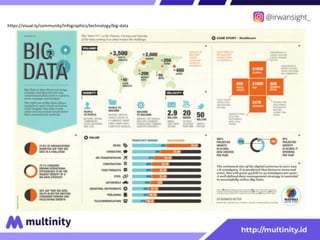
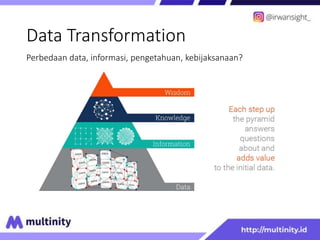
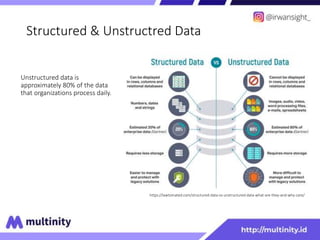
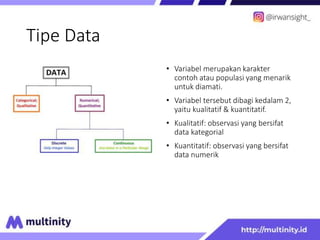
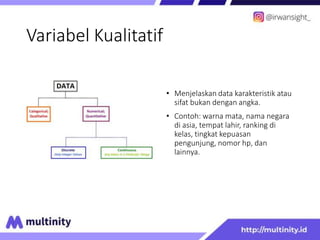
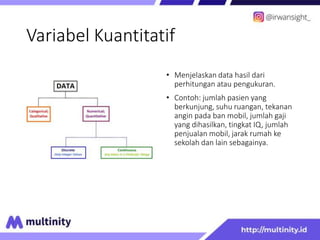
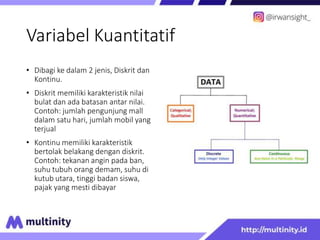
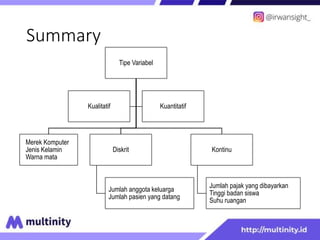
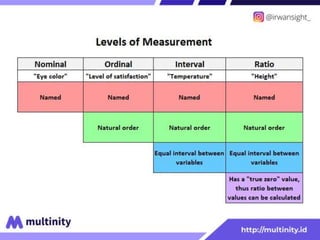
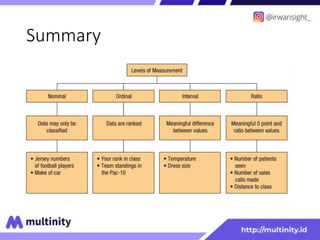
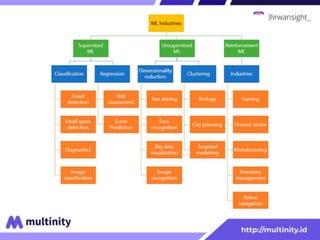
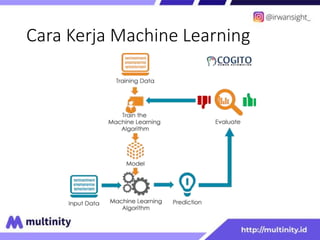
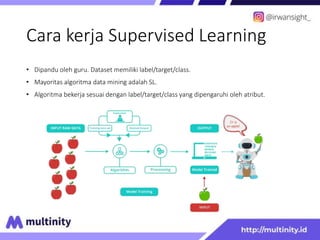
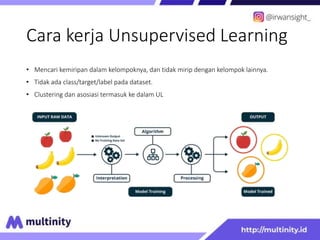
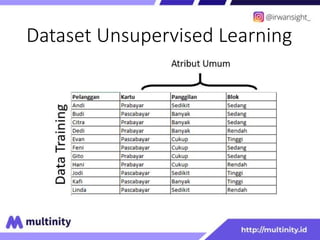
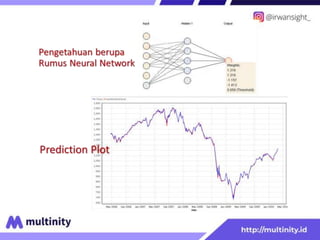
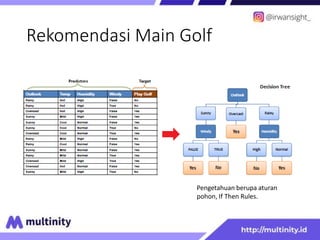
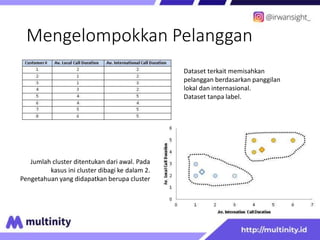
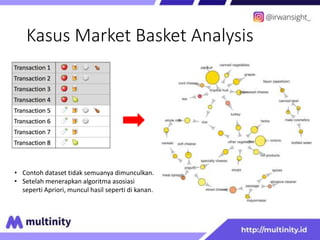
Dokumen ini adalah materi ajar mengenai data mining yang ditulis oleh Irwansyah Saputra, yang mencakup konsep dasar, tipe data, metode, dan algoritma data mining. Juga dijelaskan tentang penerapan data mining dalam berbagai konteks, termasuk estimasi, klasifikasi, dan asosiasi. Penulis merupakan seorang dosen ilmu komputer dan mahasiswa S3 yang memiliki minat di bidang kecerdasan komputasi dan optimisasi.