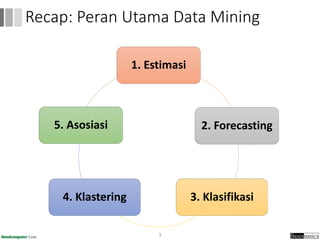
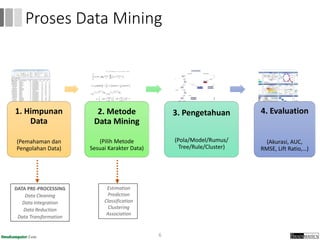
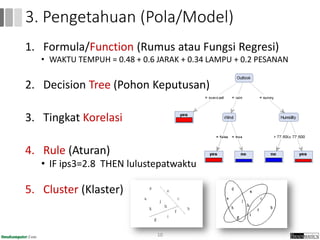
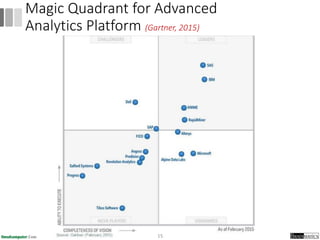
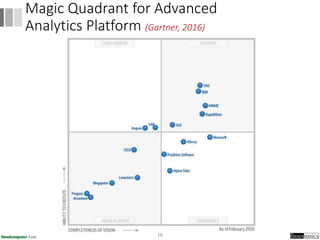
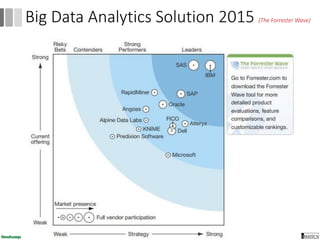
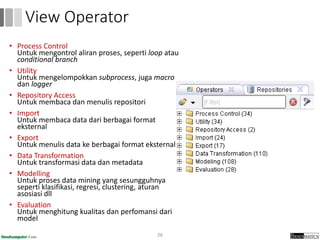
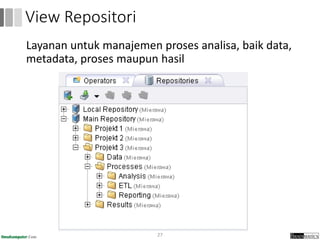
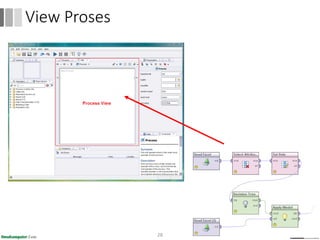
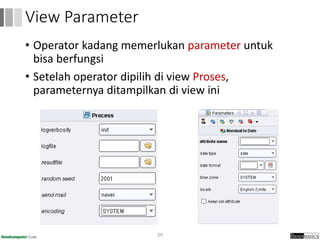
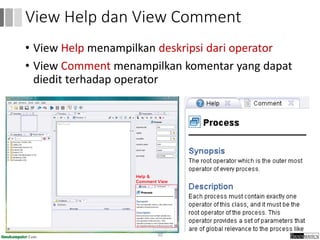
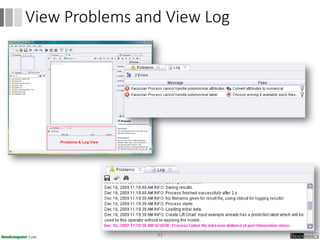
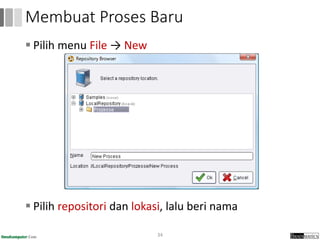
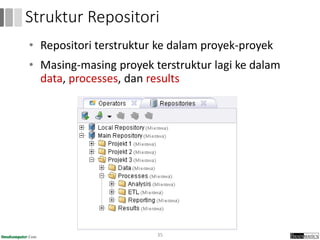
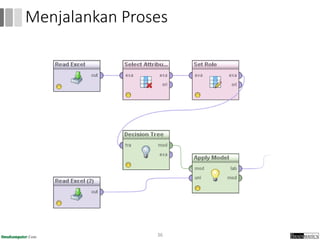
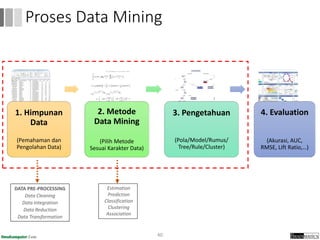
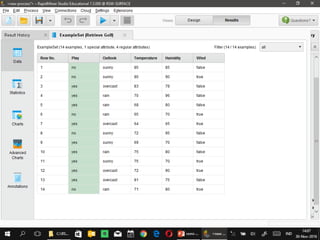
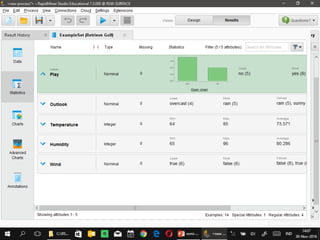
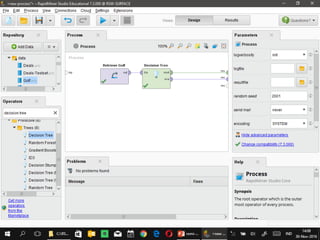
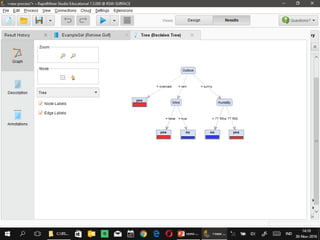
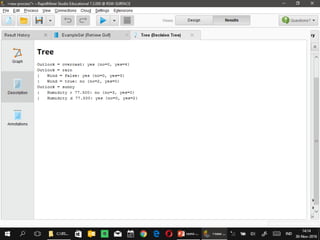
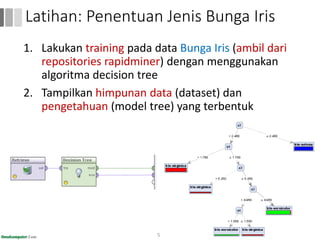
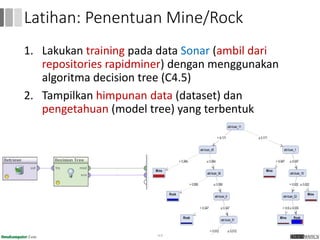
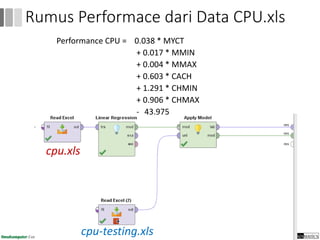
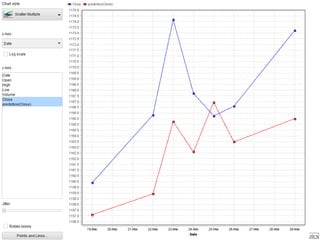
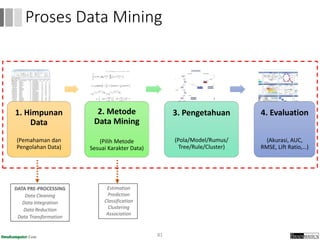
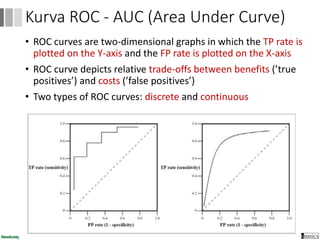
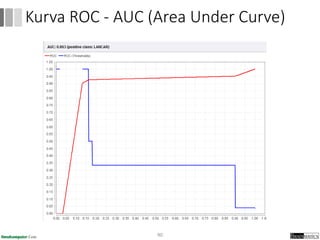
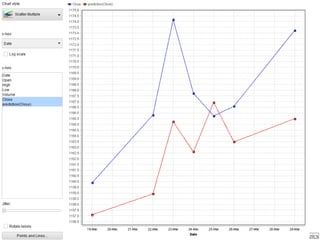
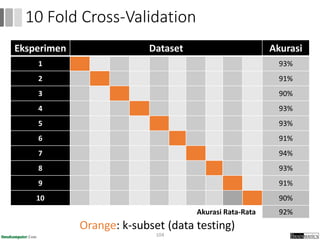
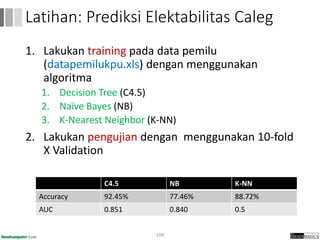
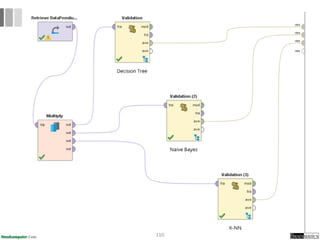
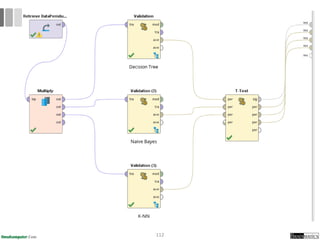
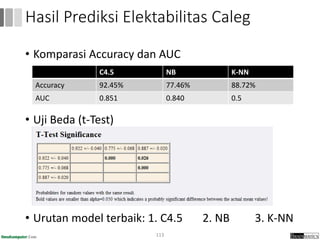
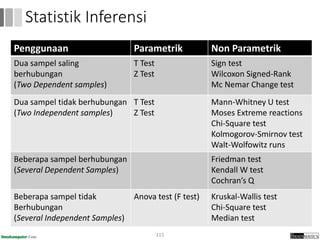
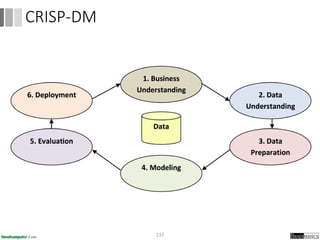
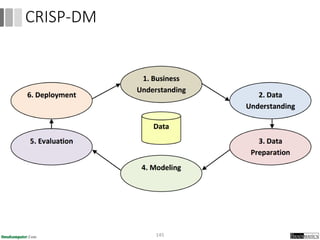
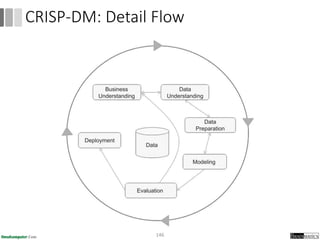
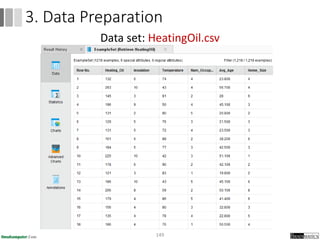
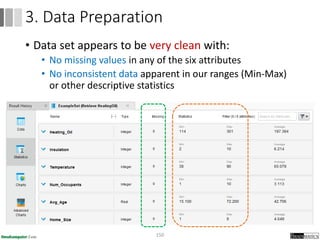
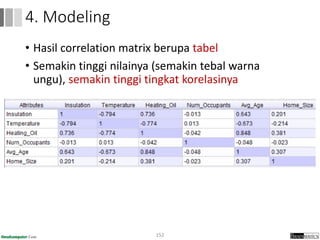
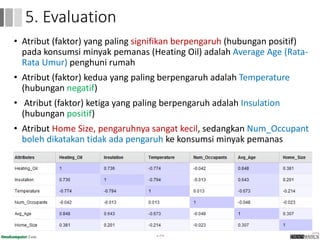
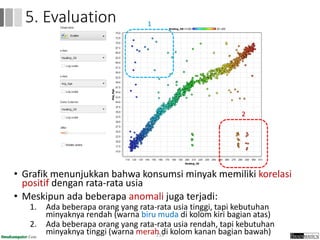
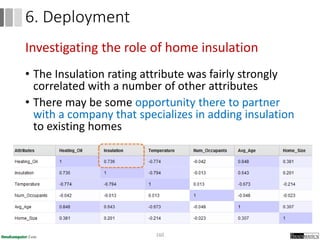
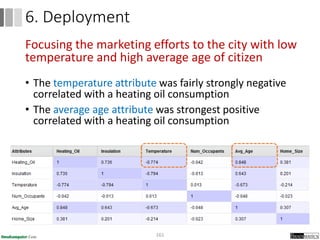
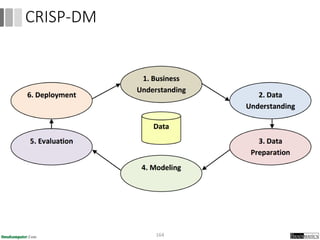
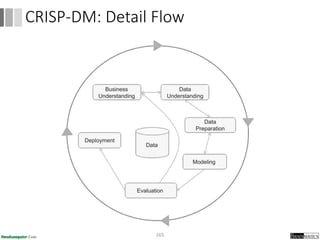
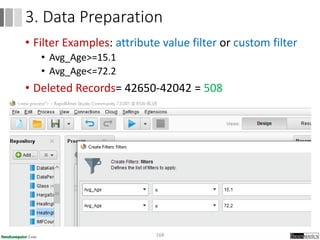
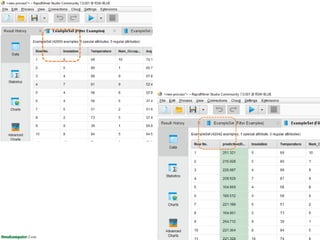
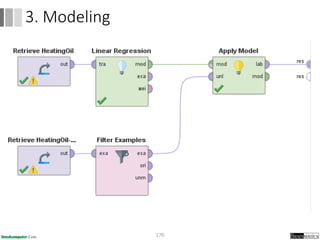
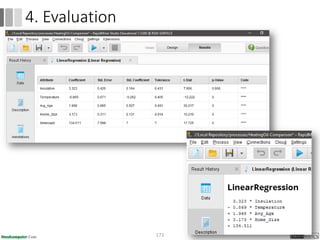
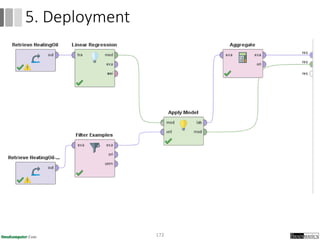
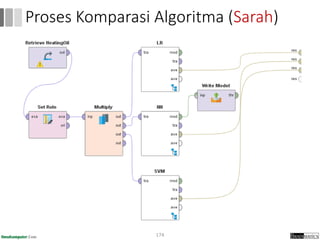
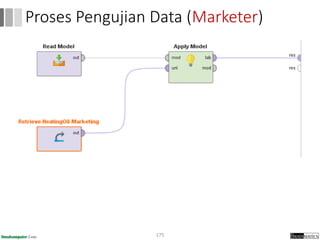
Dokumen ini menjelaskan proses data mining, mencakup teknik seperti estimasi, klasifikasi, klastering, dan asosiasi, serta langkah-langkah dalam penerapan data mining menggunakan alat seperti RapidMiner. Terdapat referensi pada metode evaluasi dan validasi model, serta pentingnya penggunaan dataset publik untuk penelitian yang dapat dibandingkan. Selain itu, dokumen ini menyediakan panduan latihan untuk mengaplikasikan algoritma data mining pada berbagai dataset.