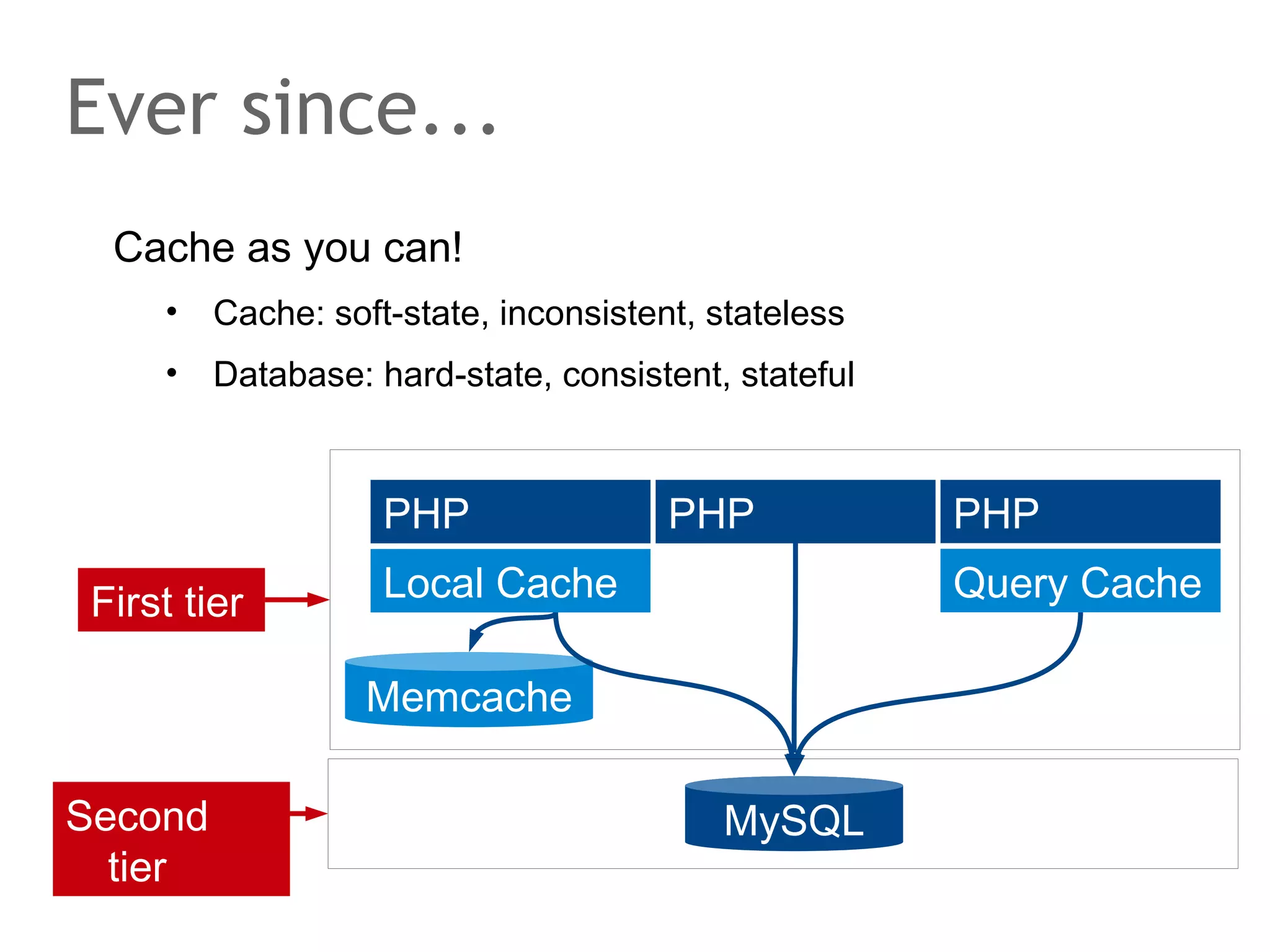
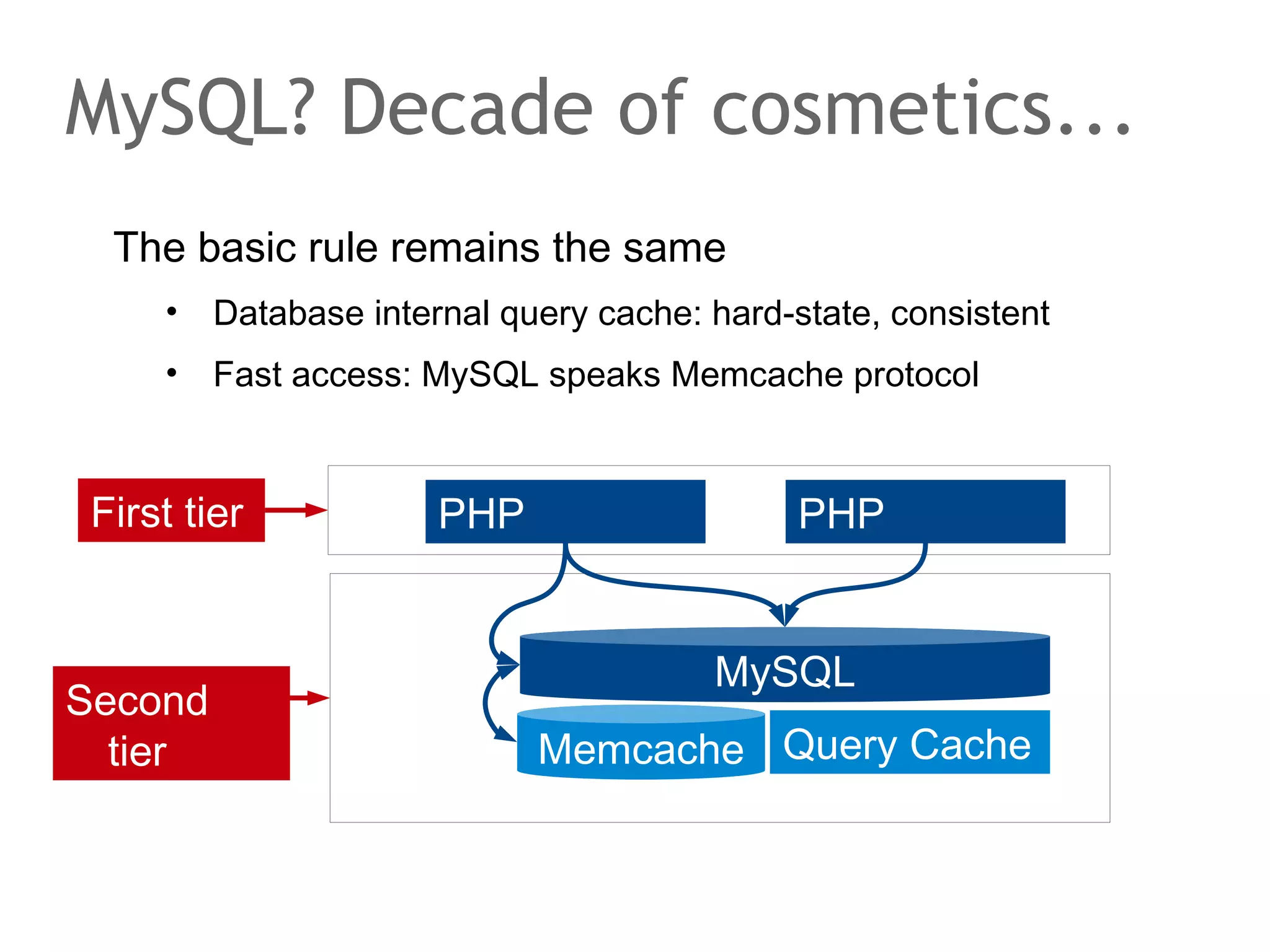
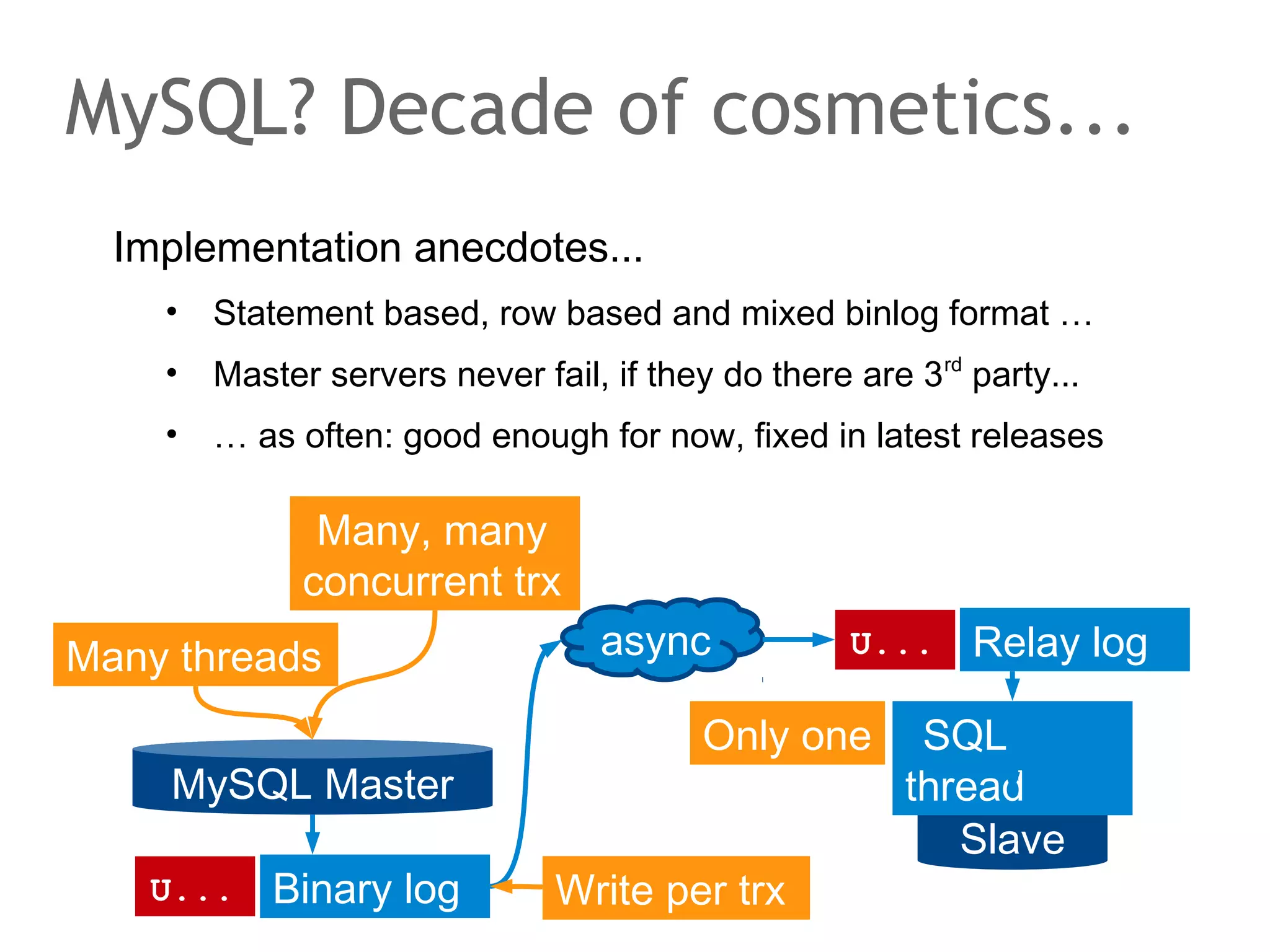
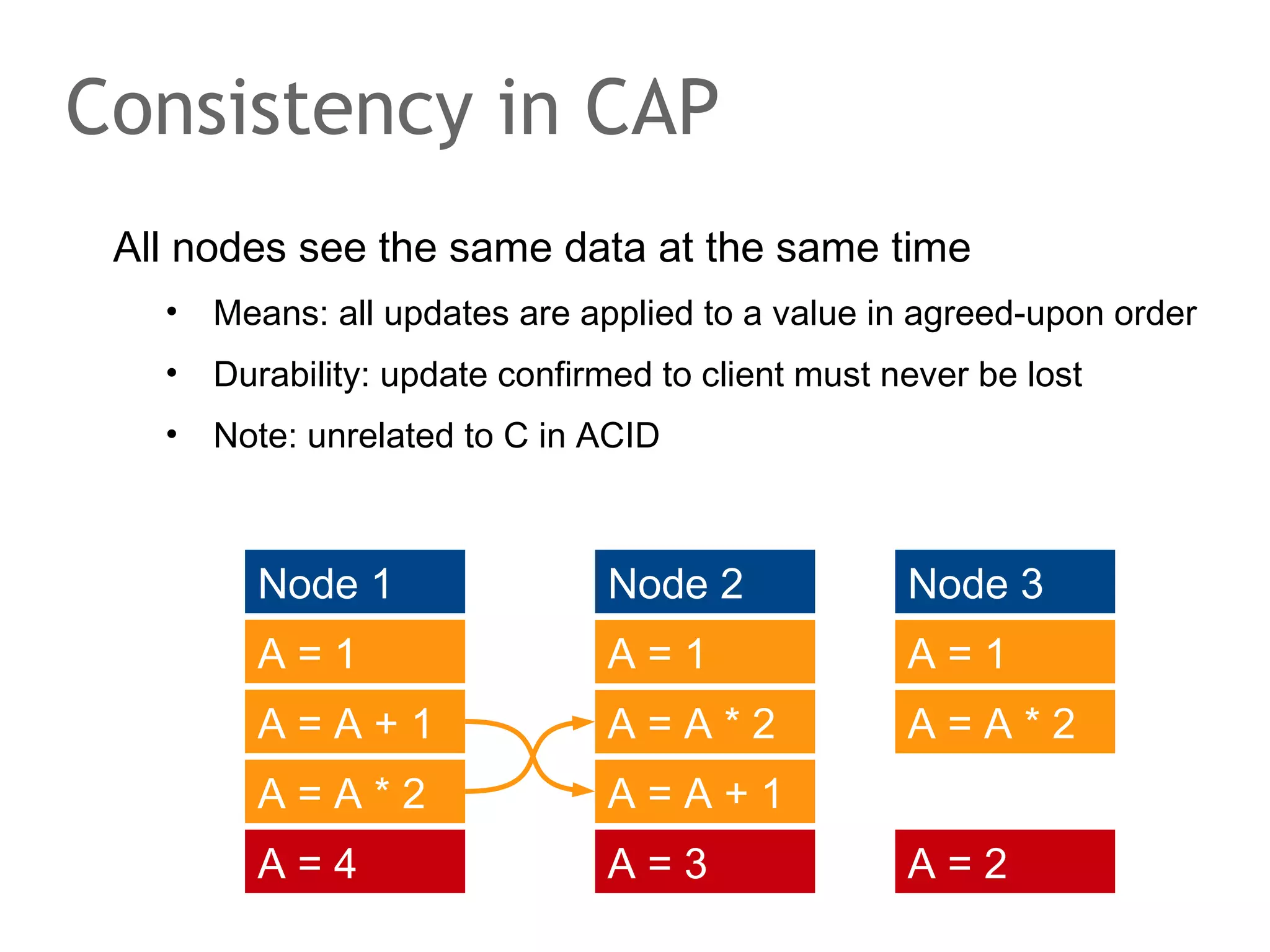
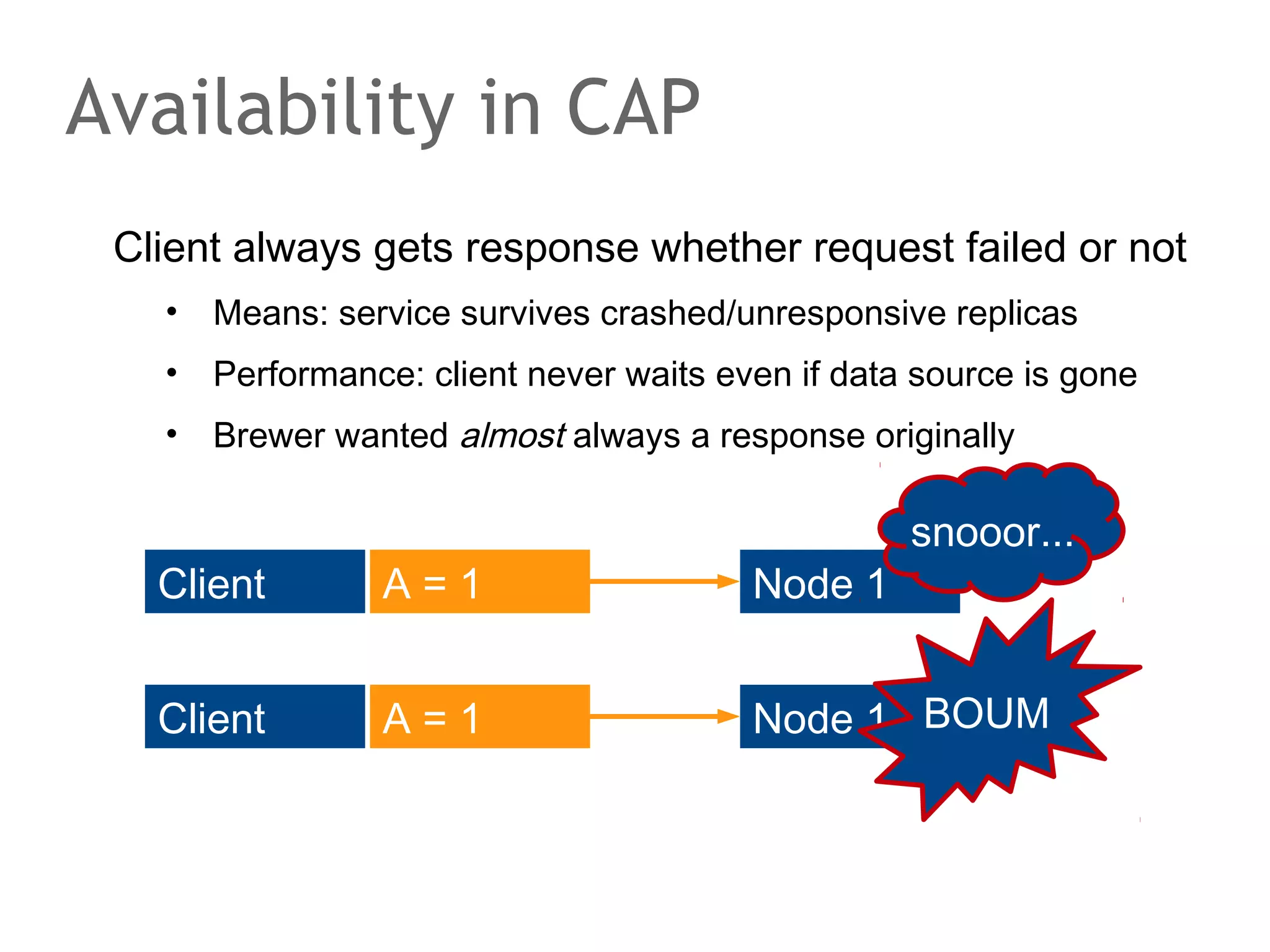
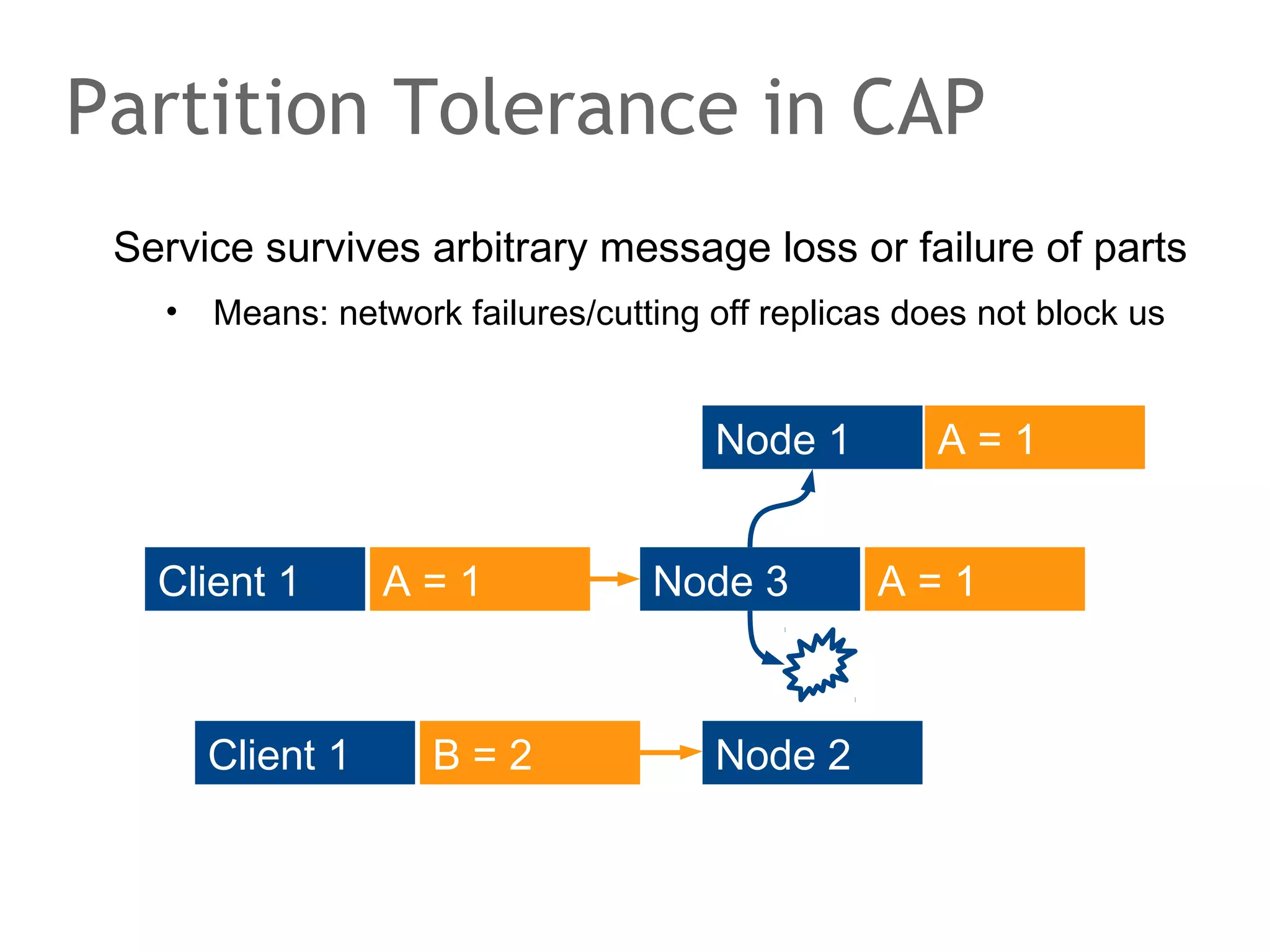
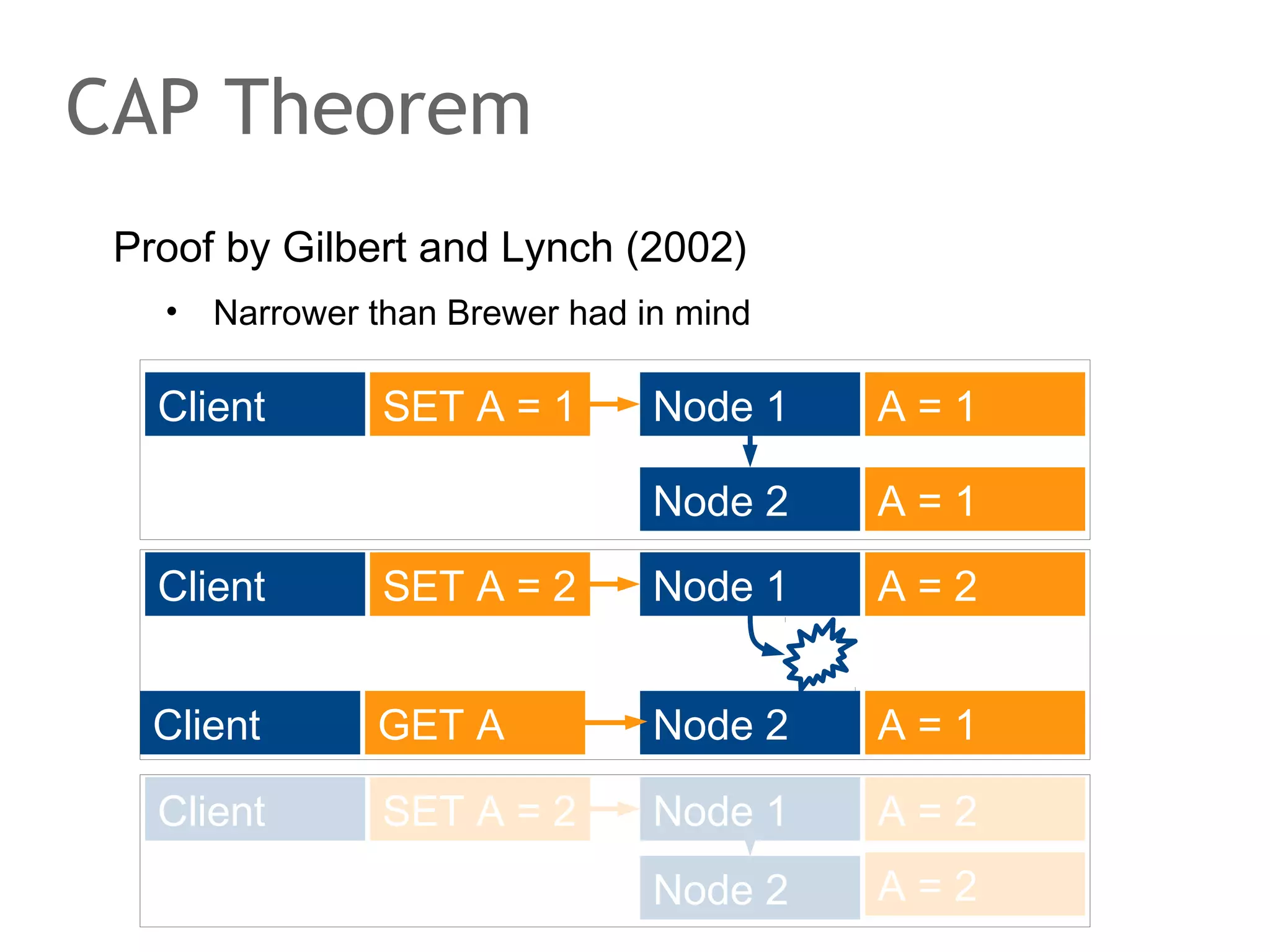
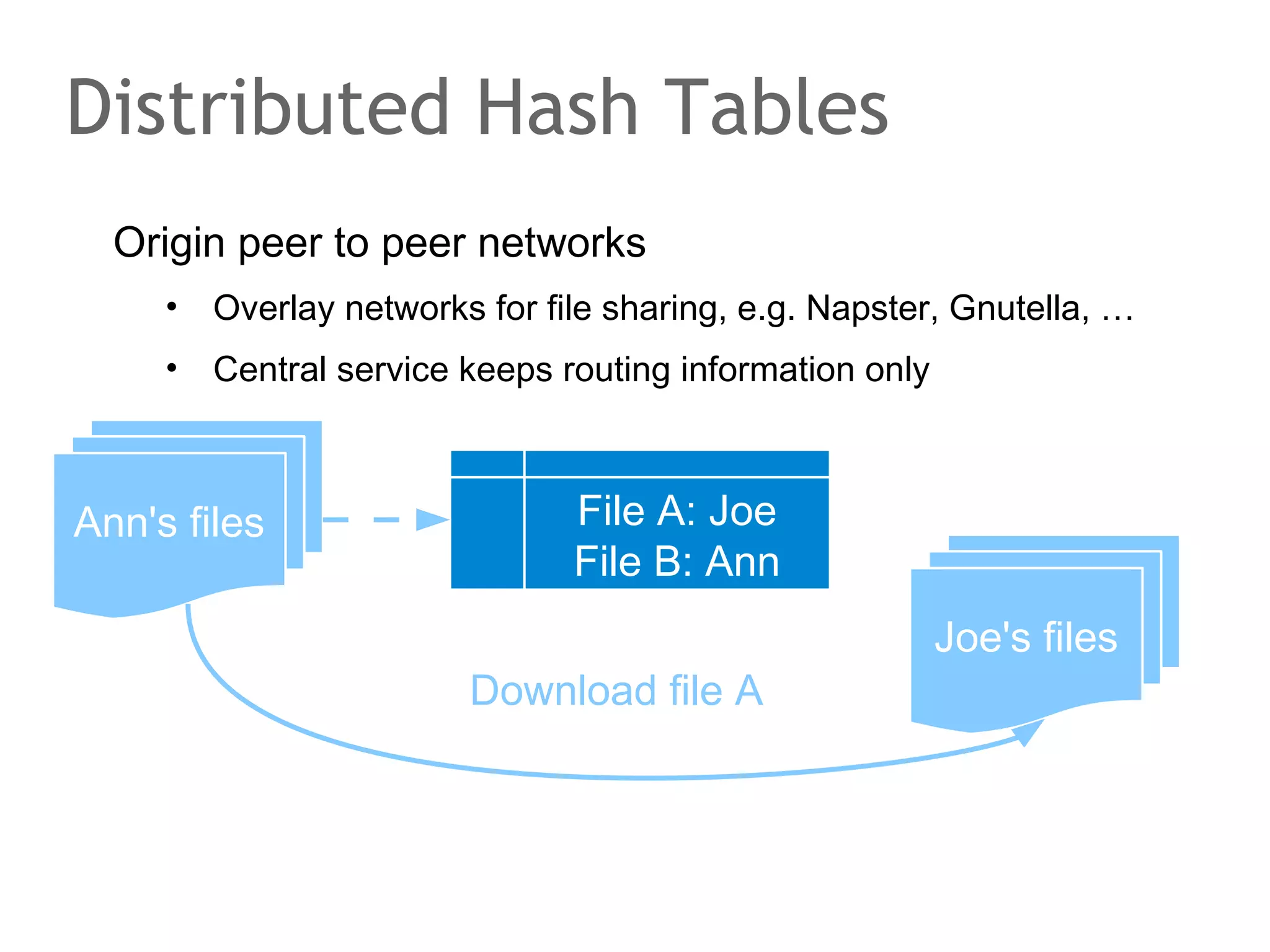
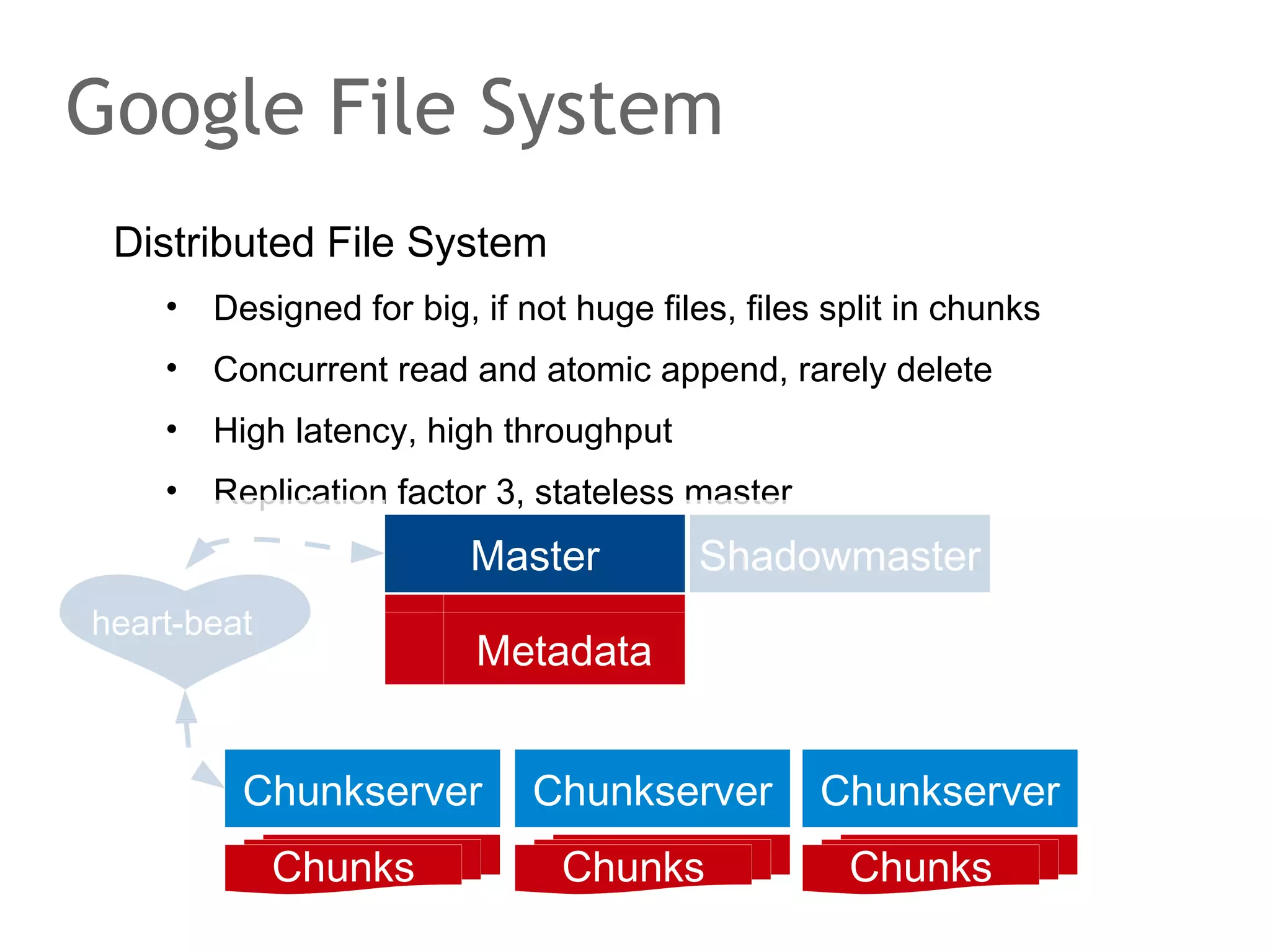
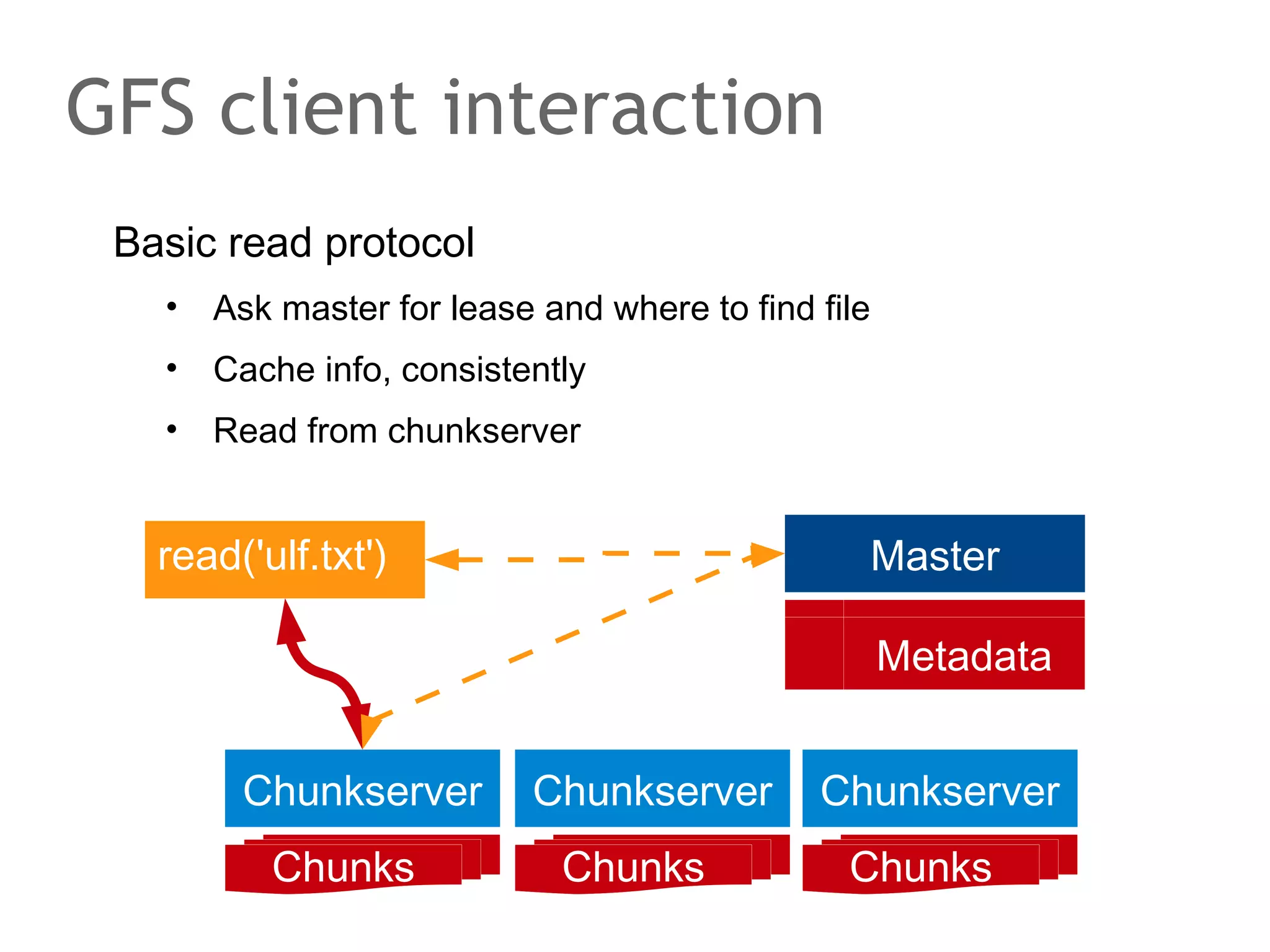
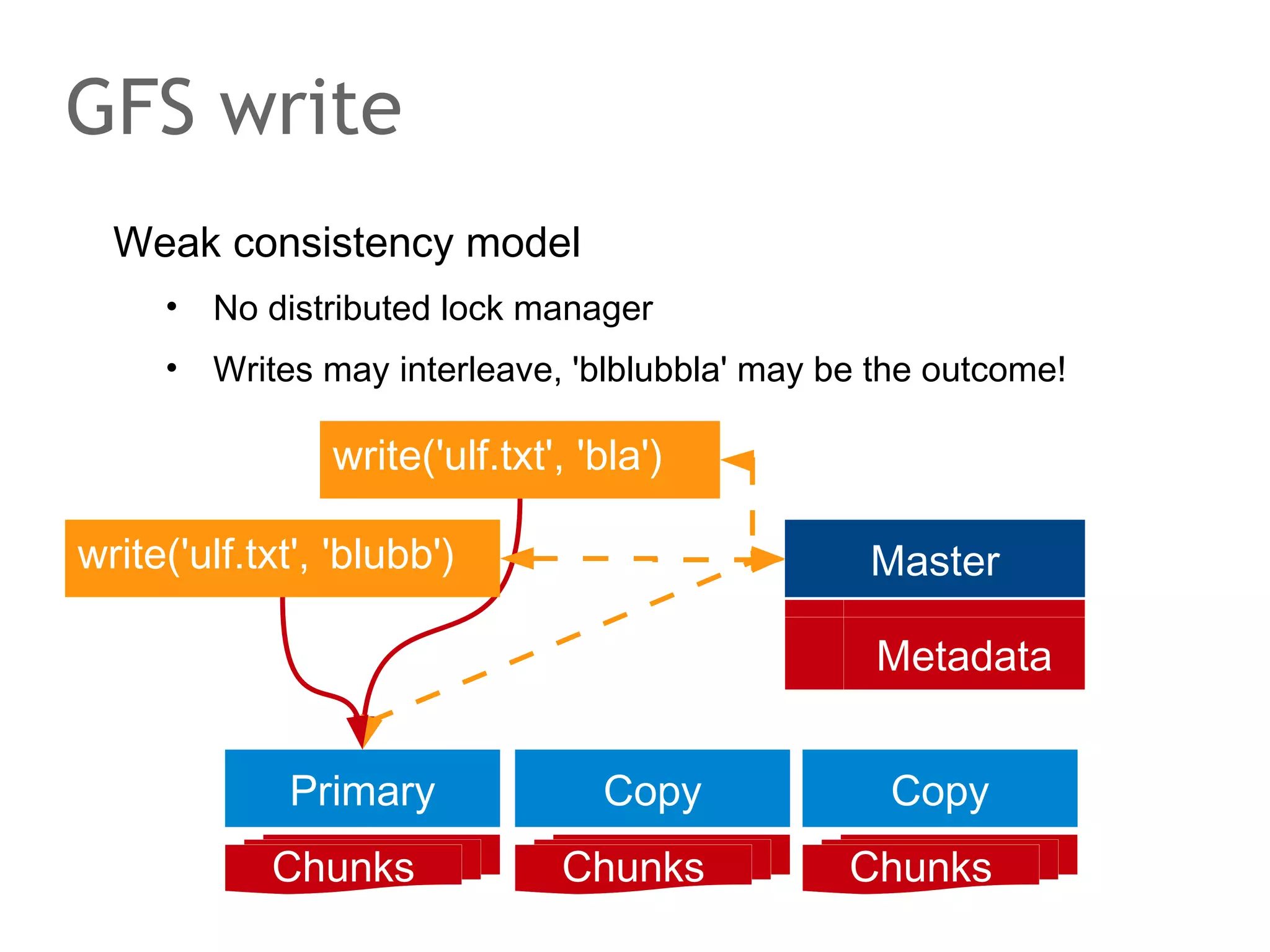
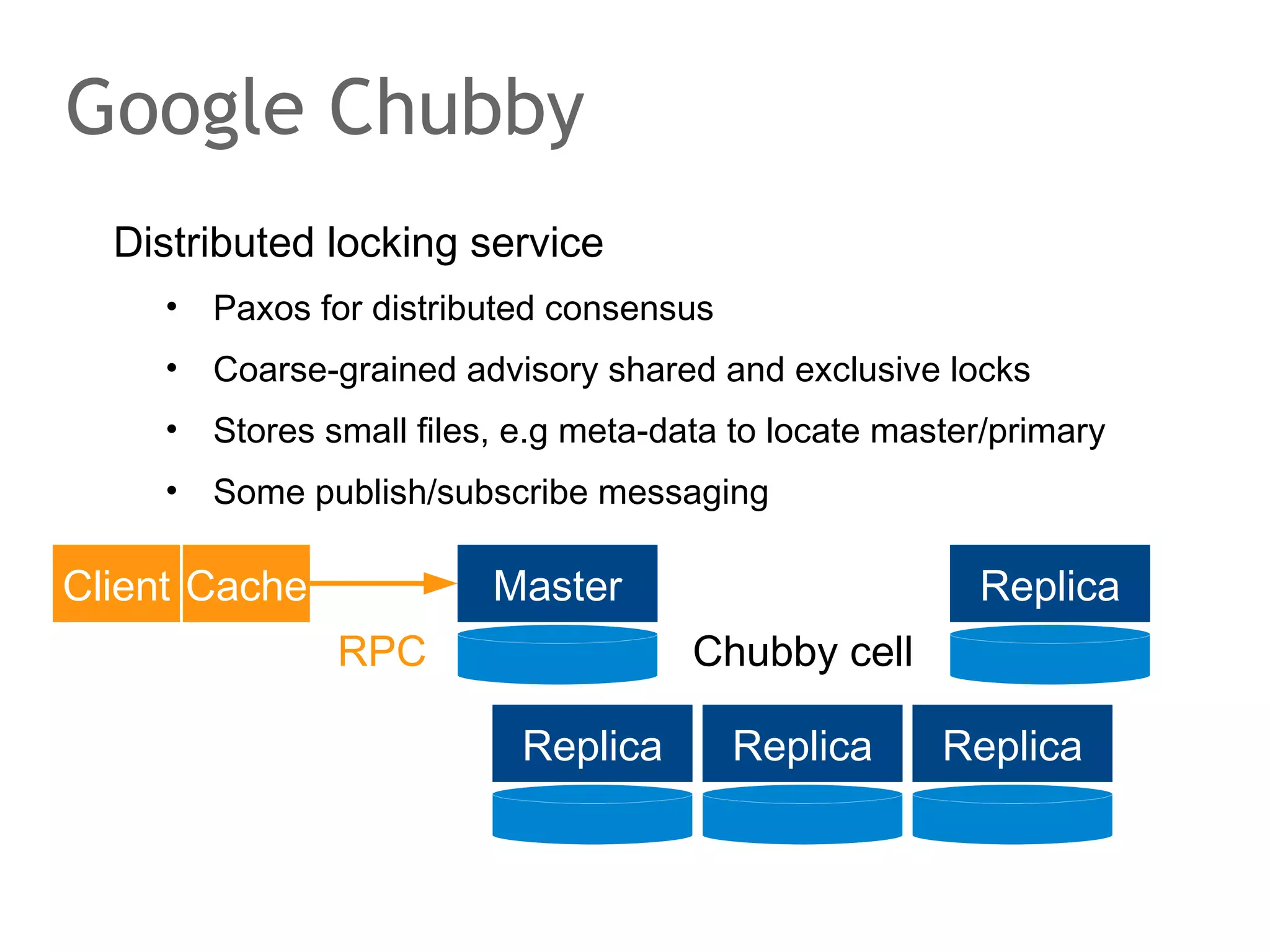
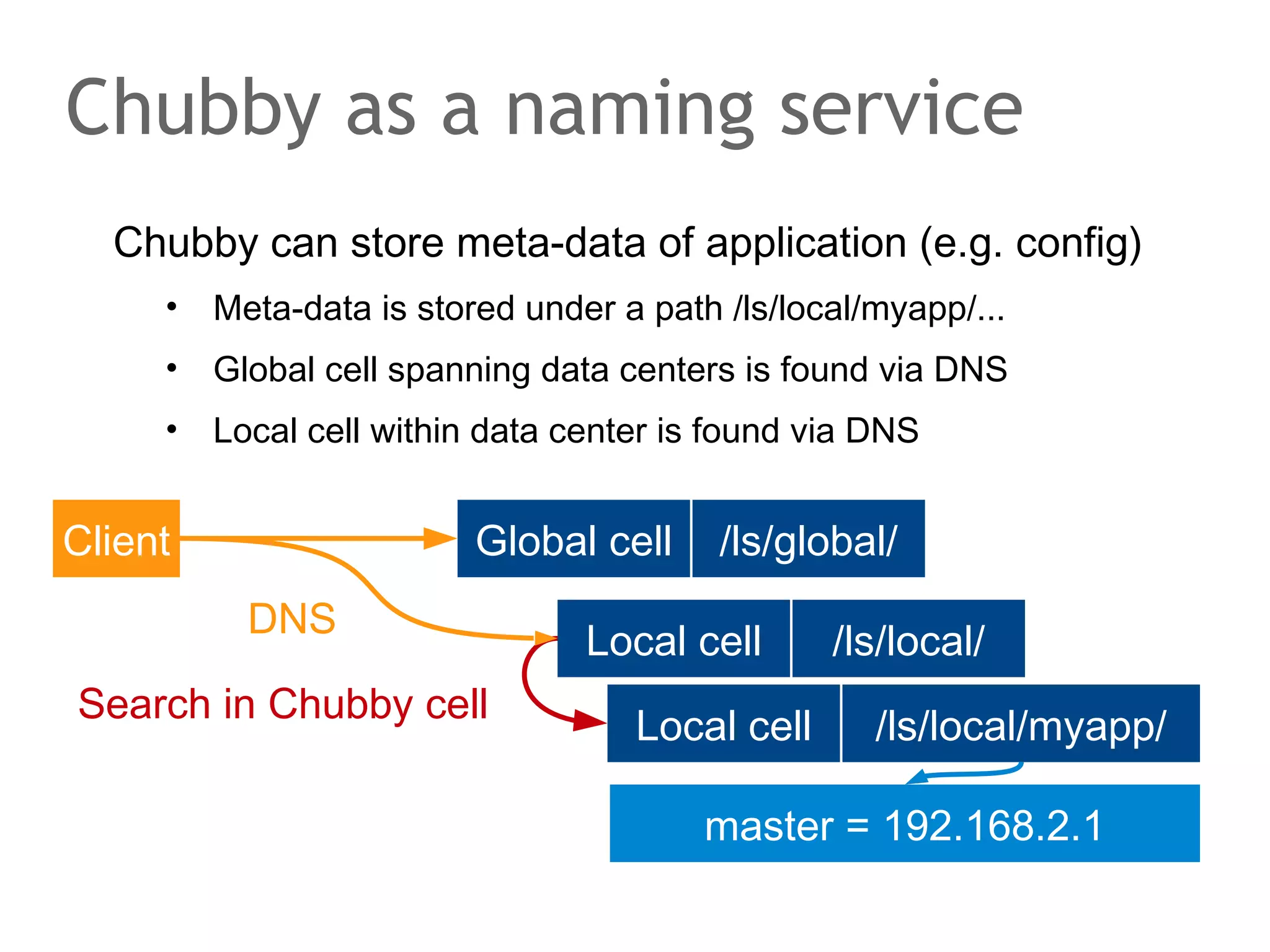
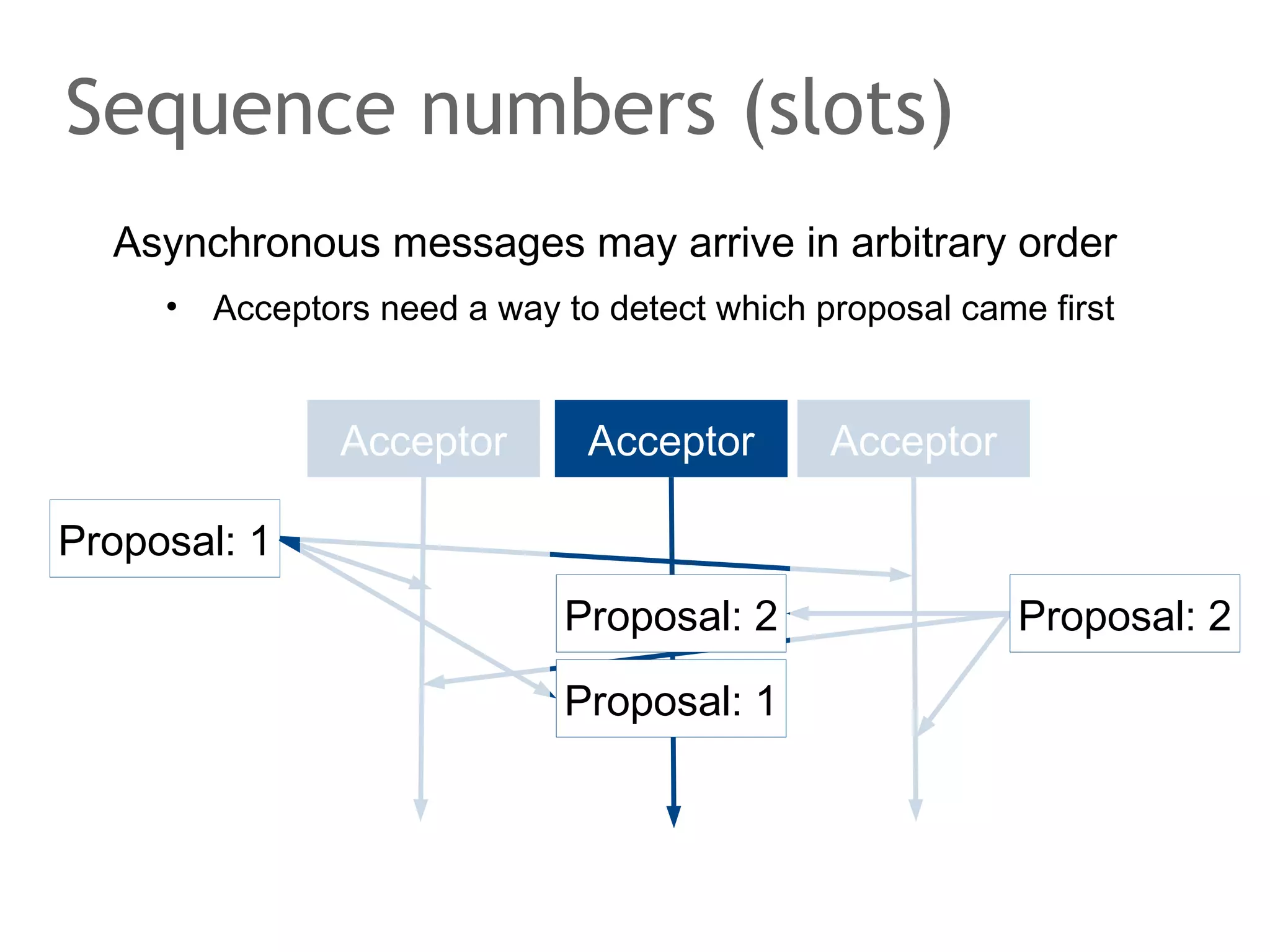
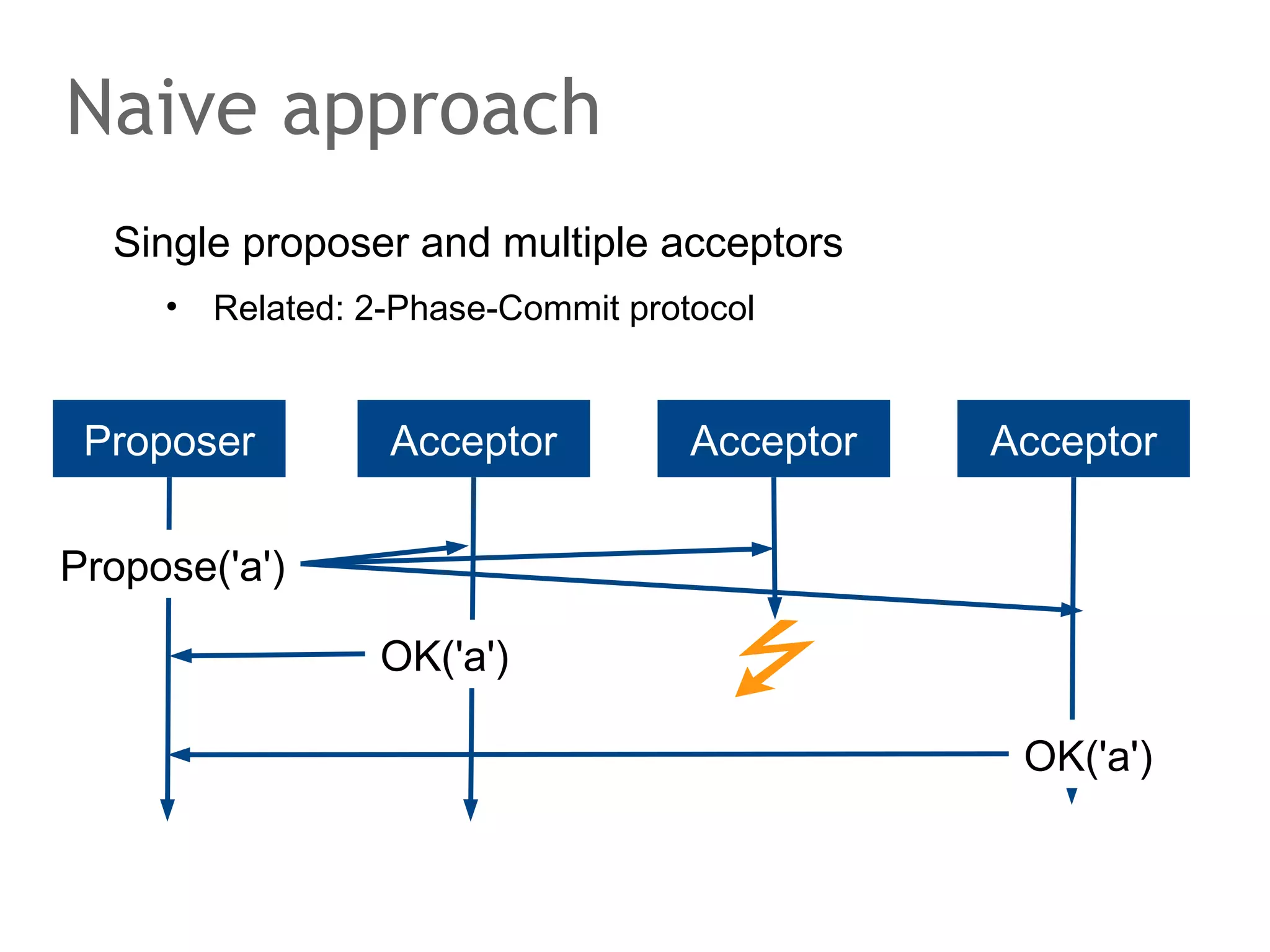
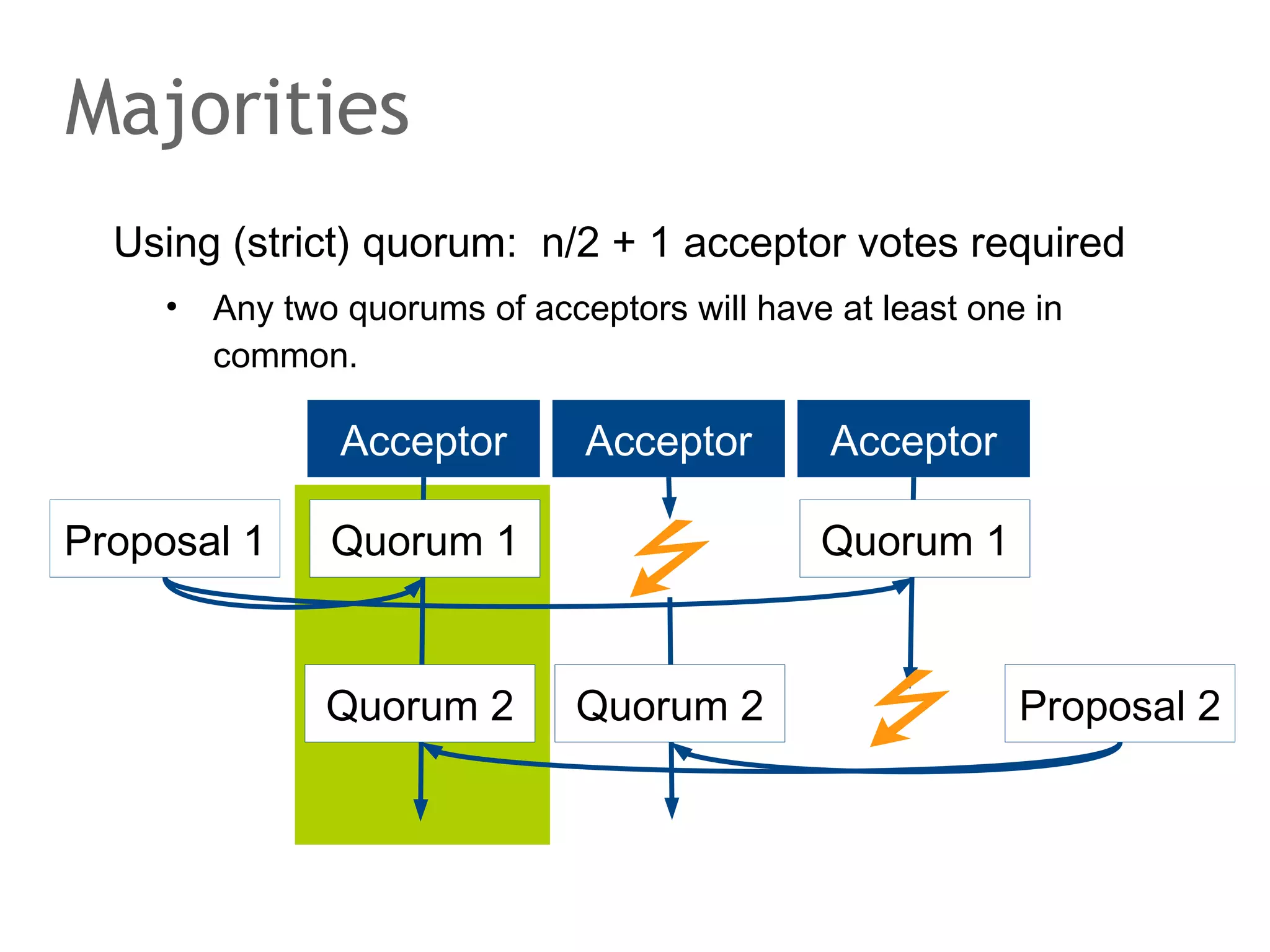
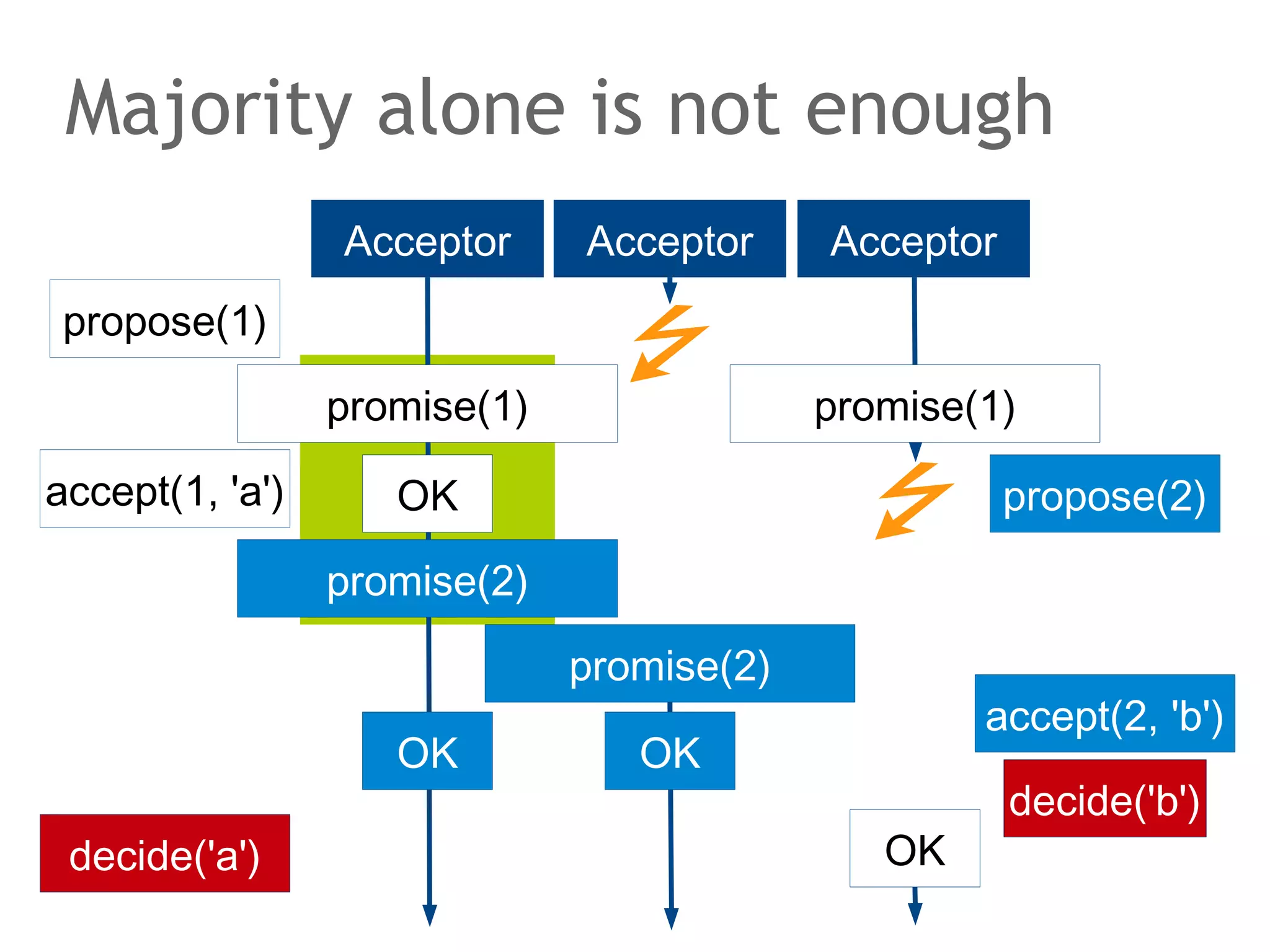
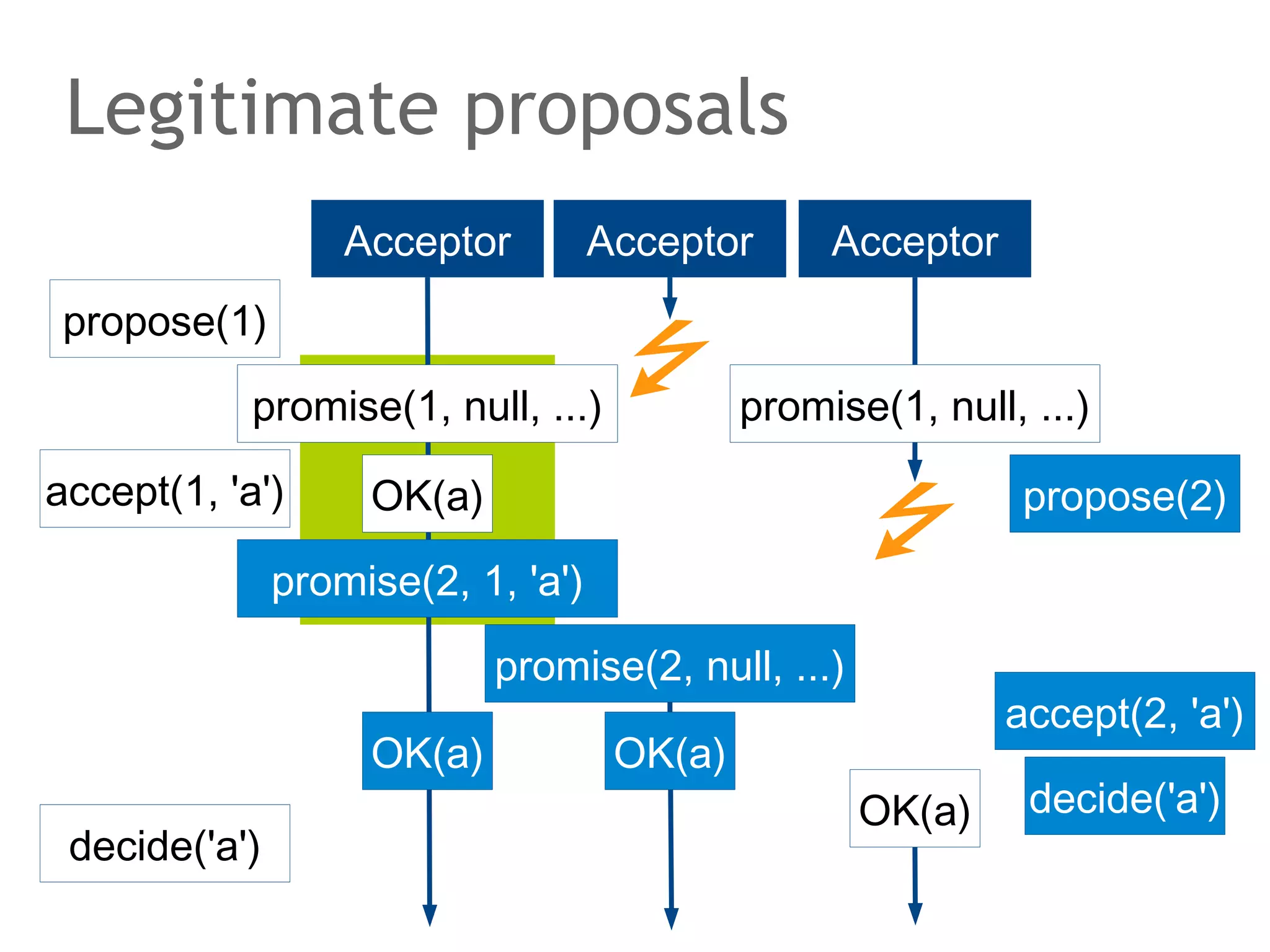
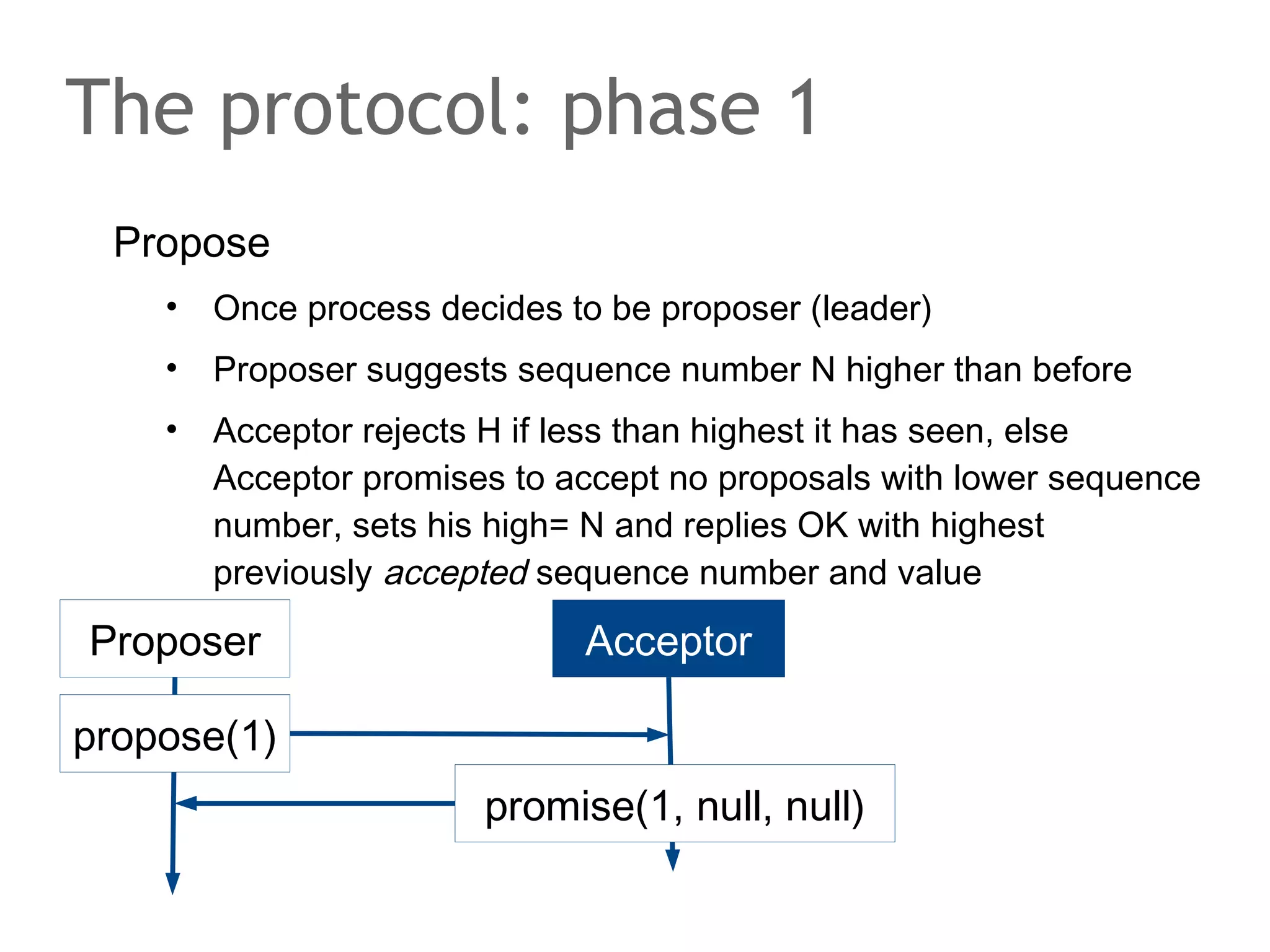
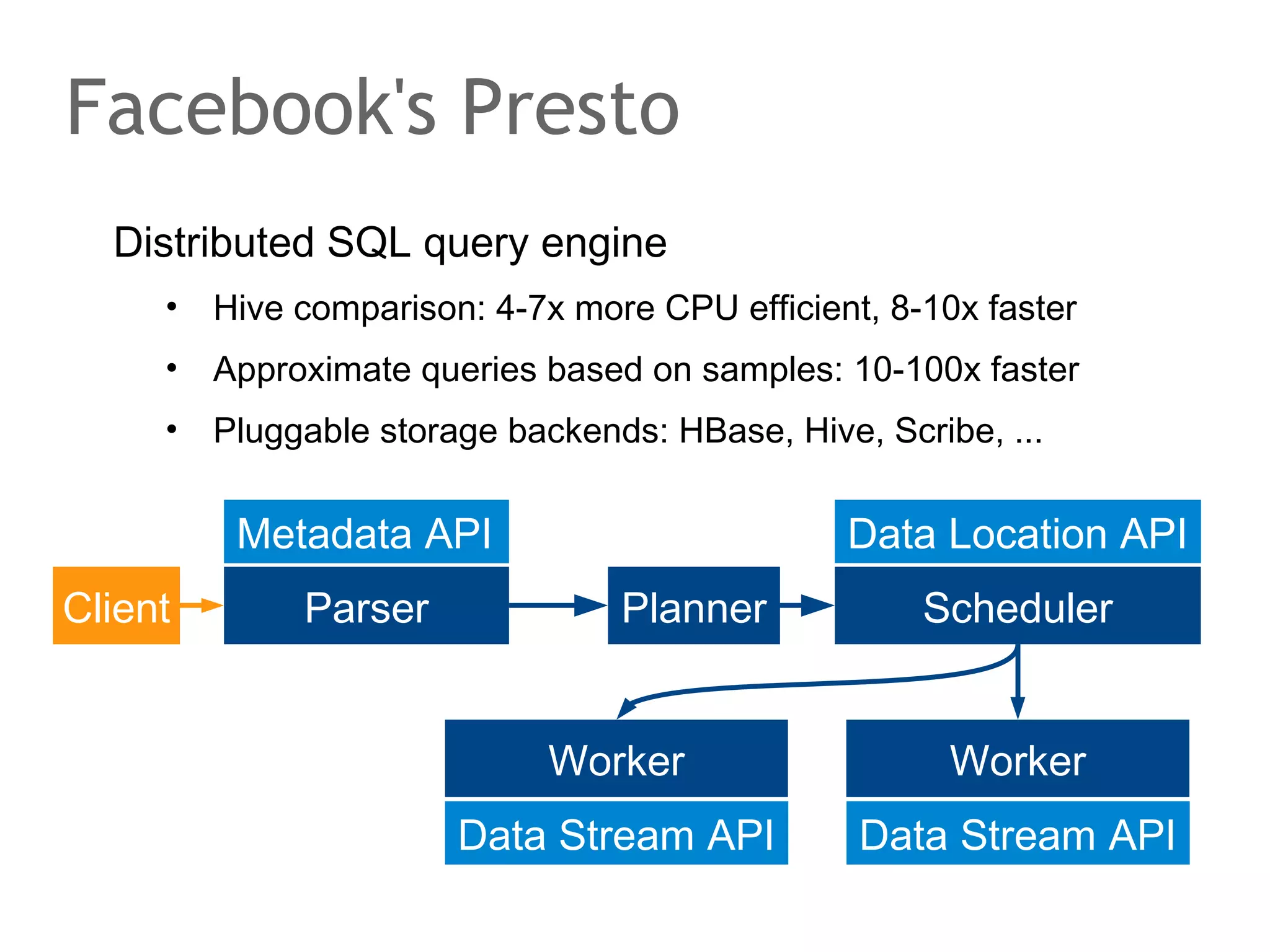
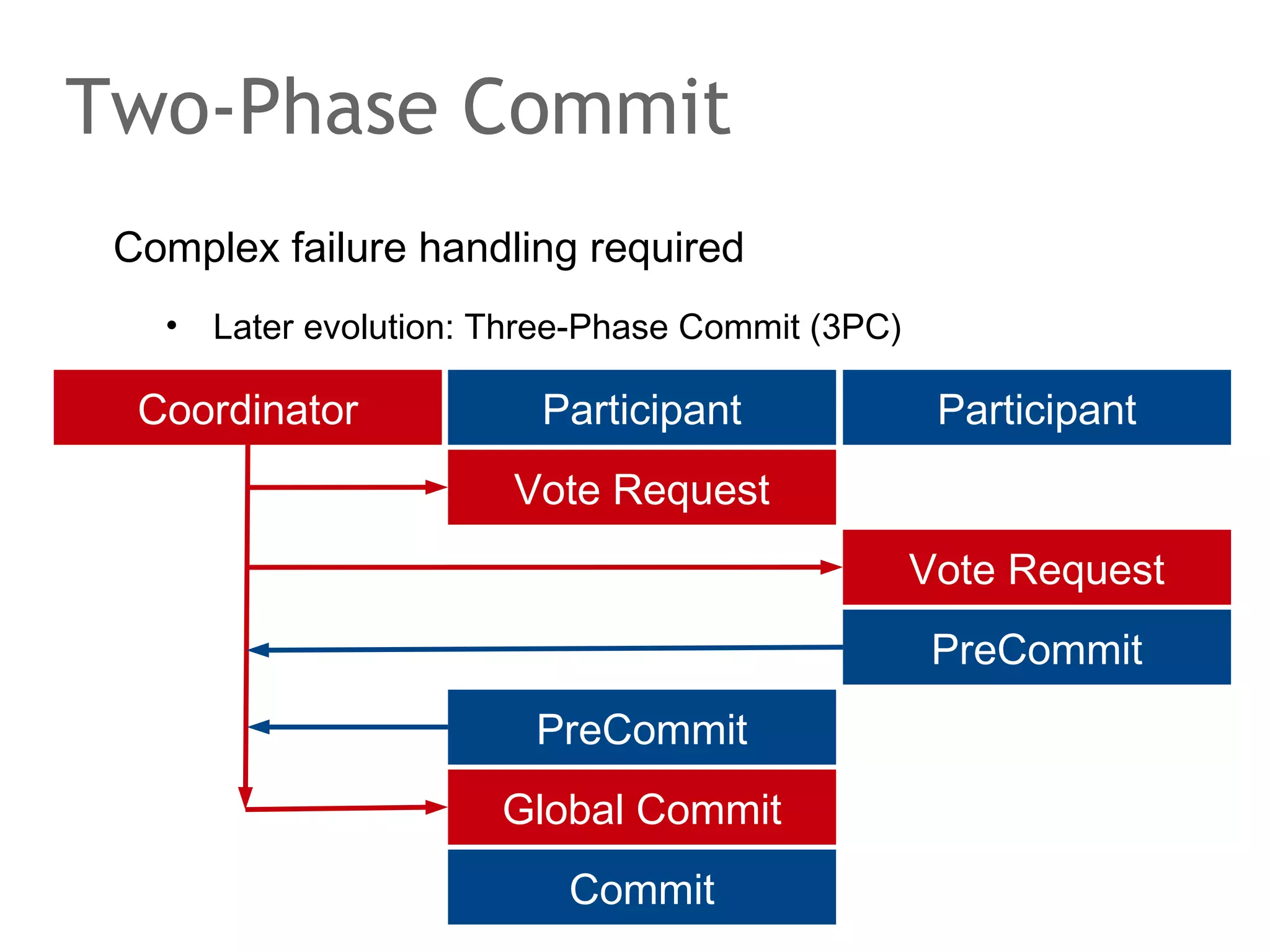
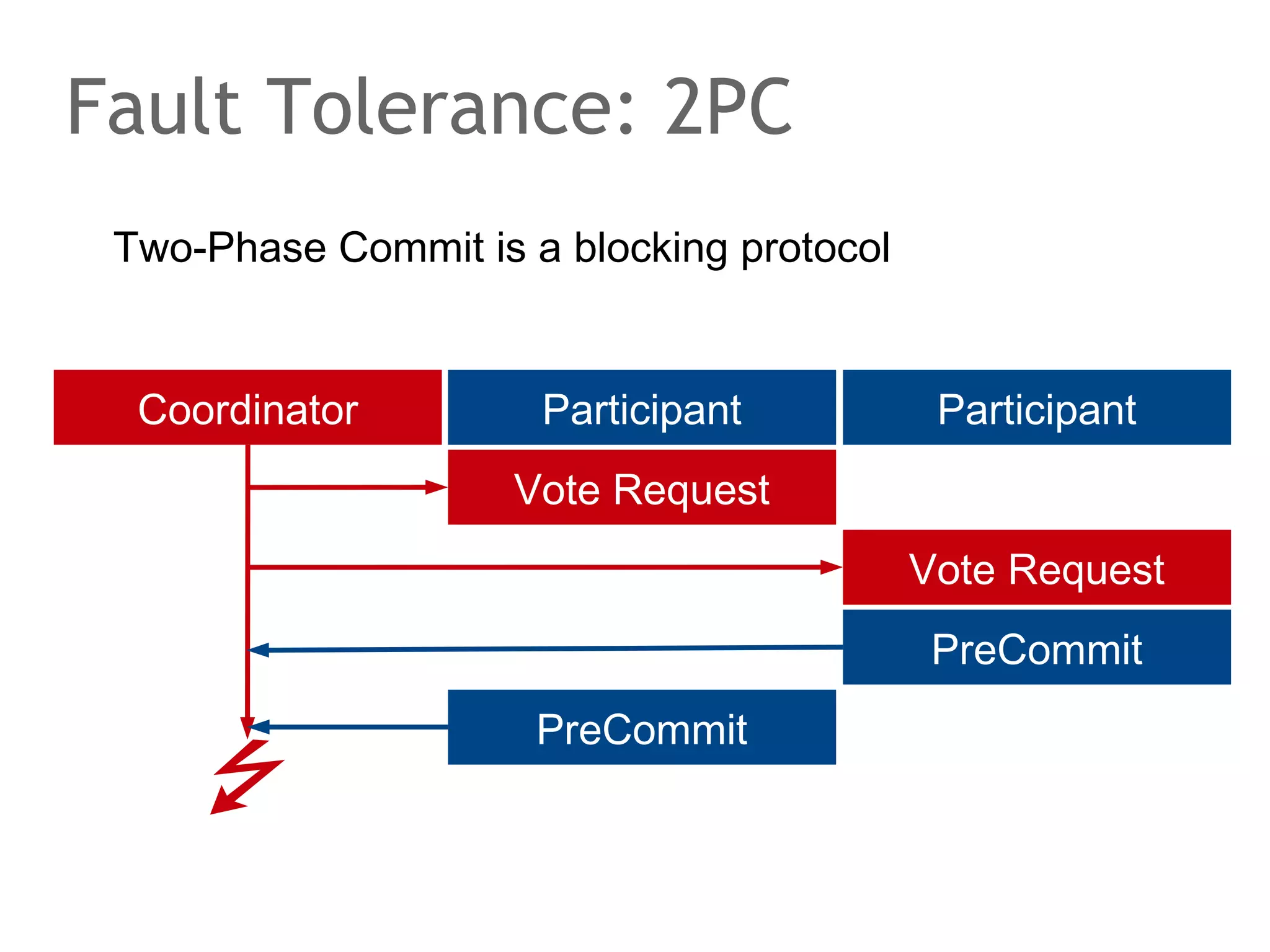
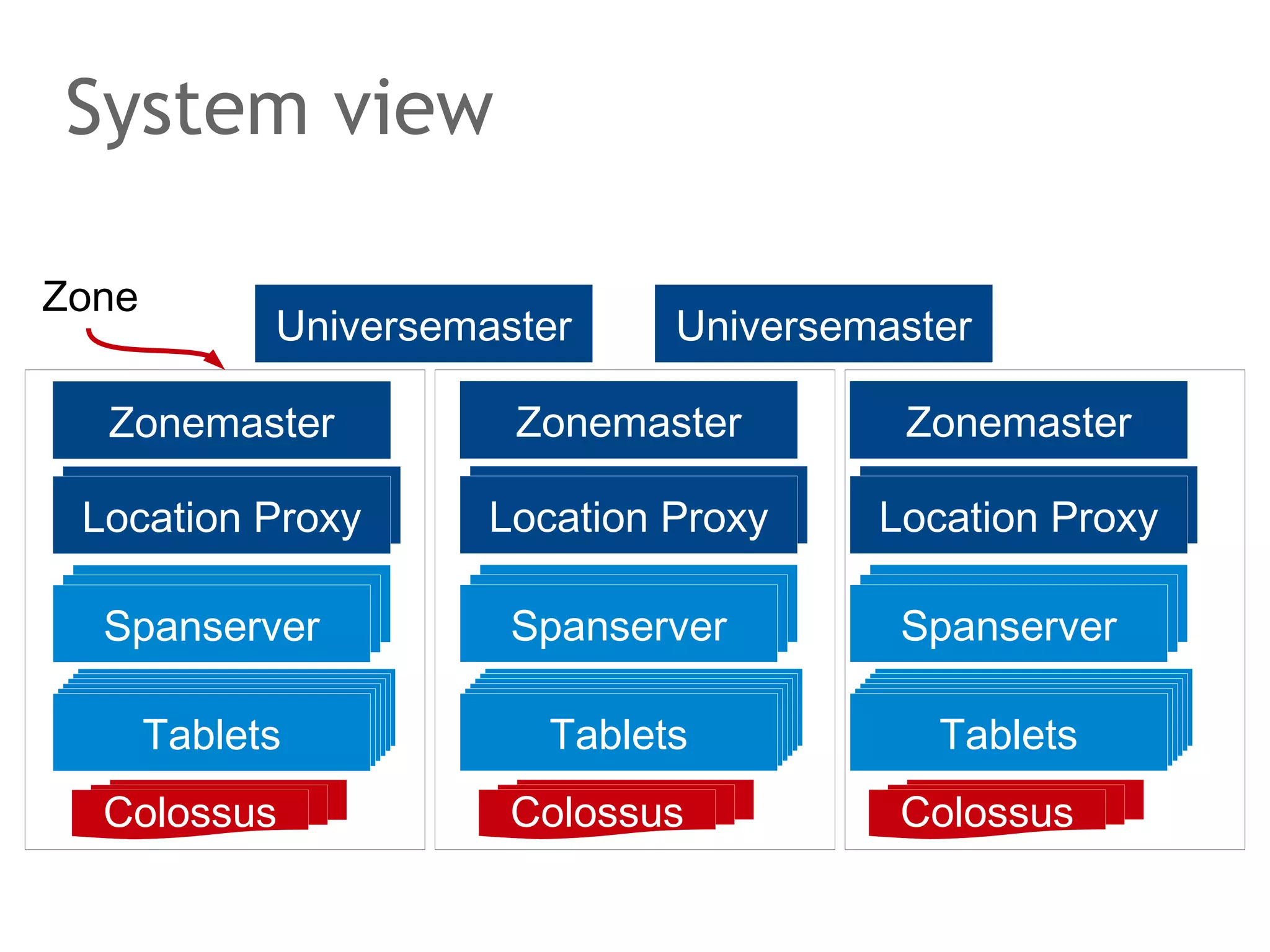
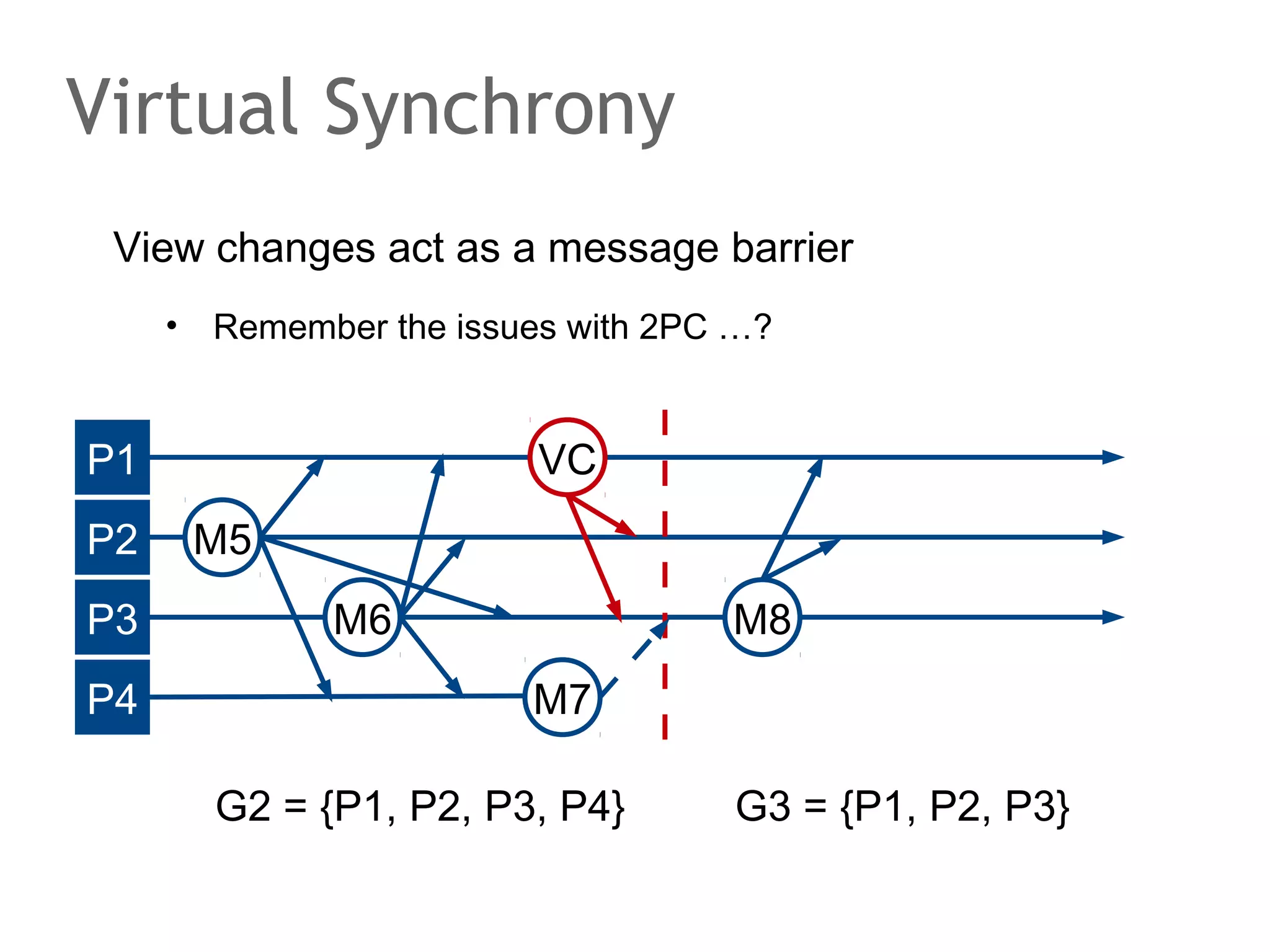
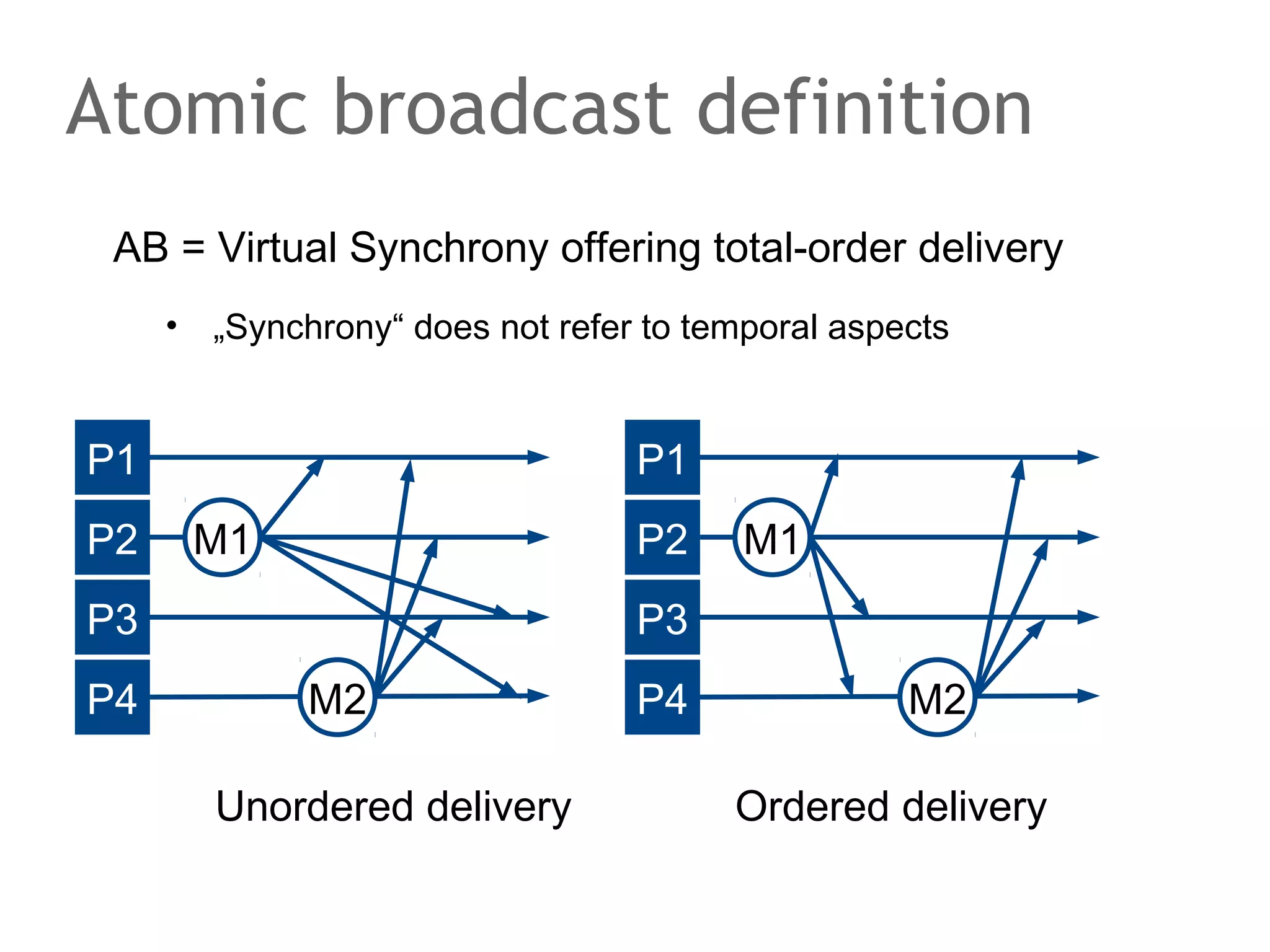
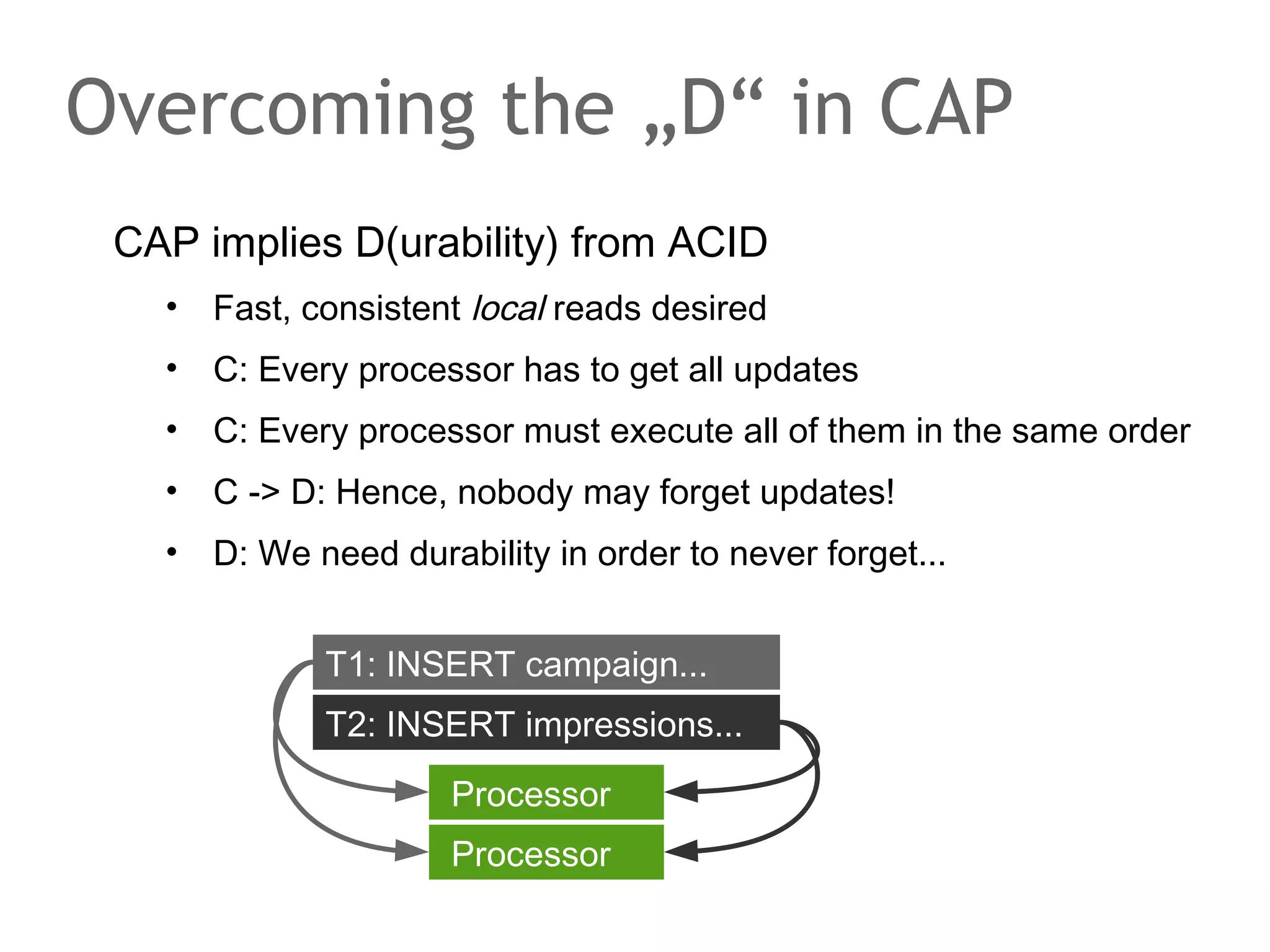
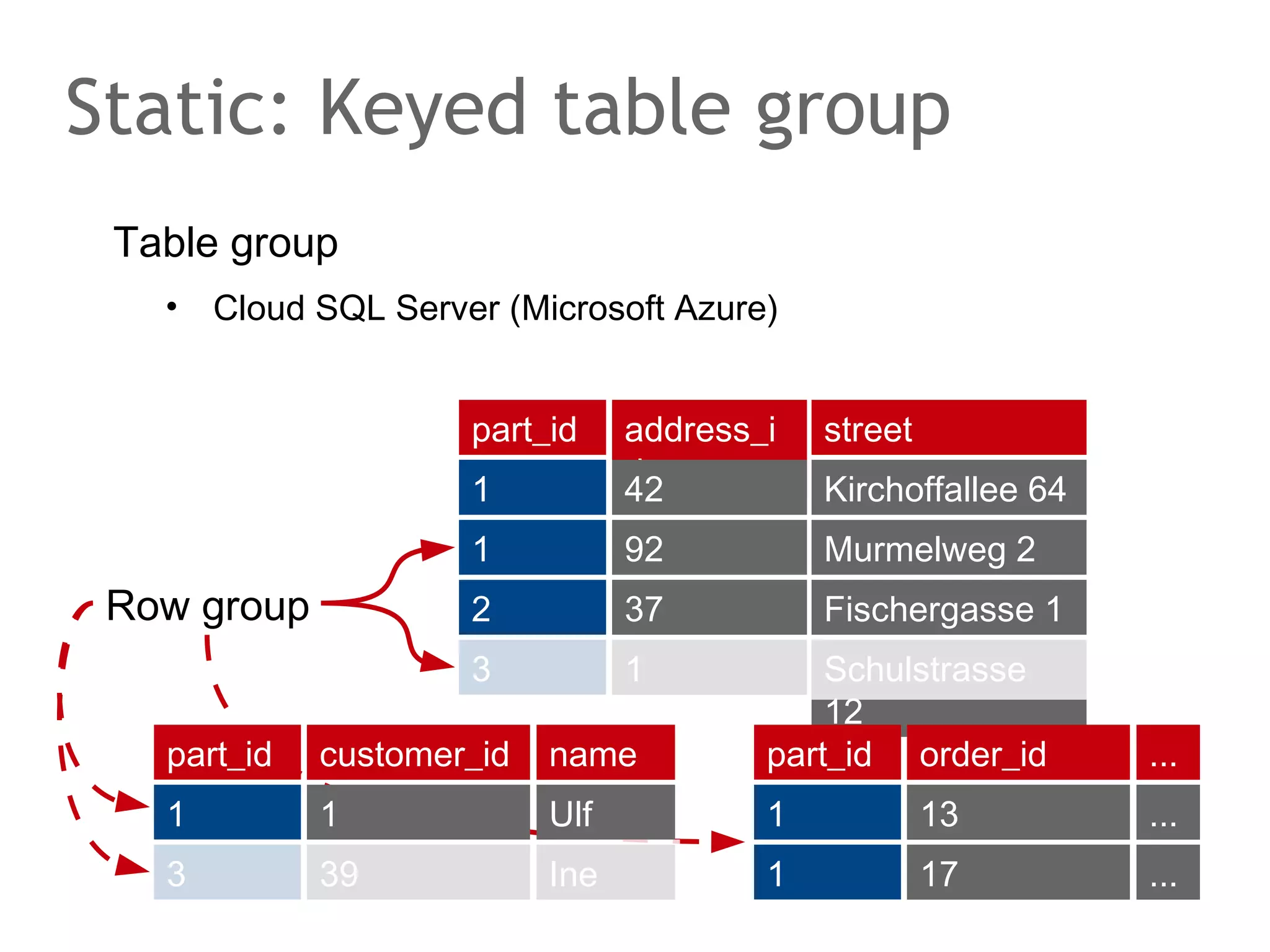
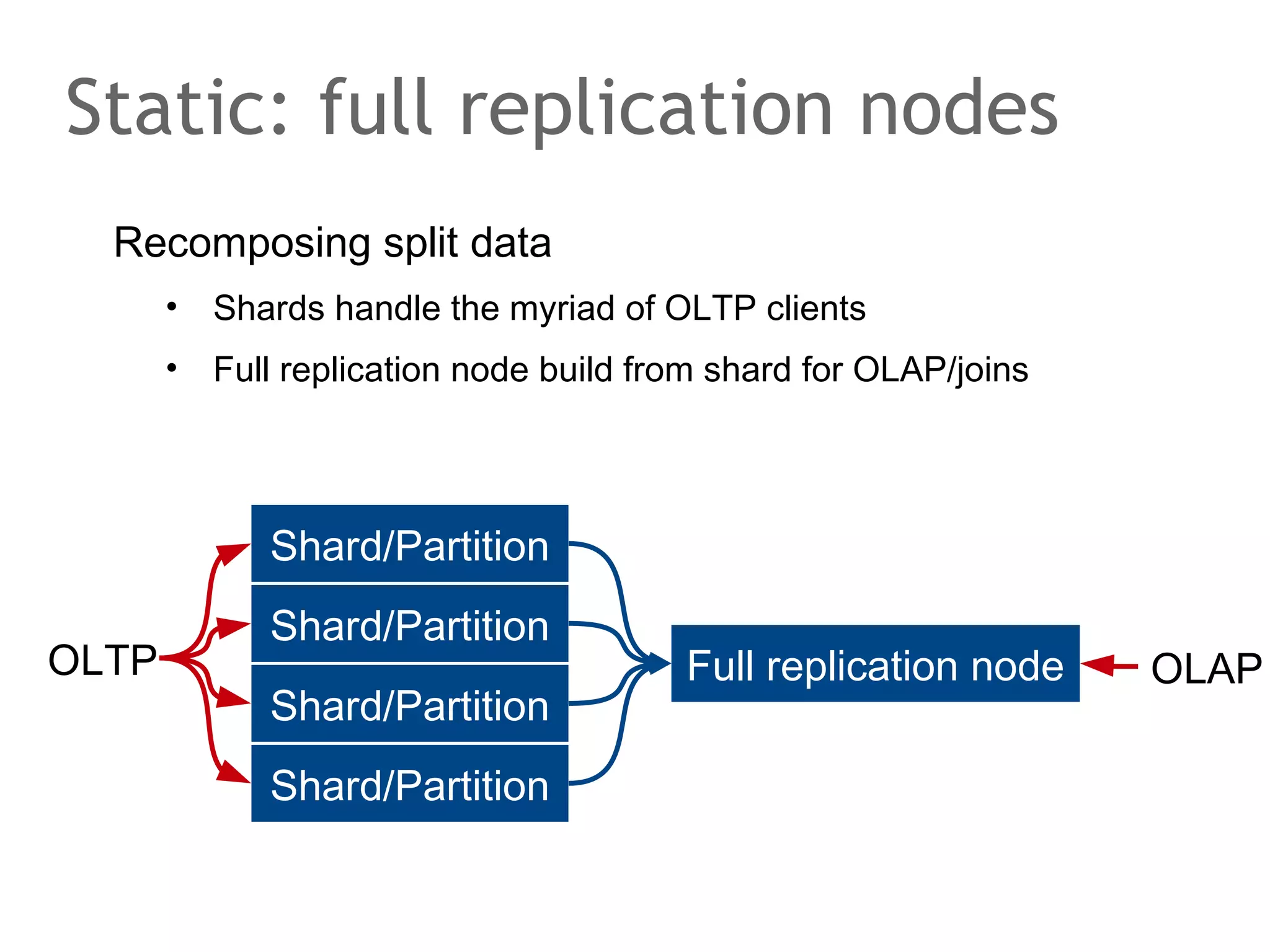
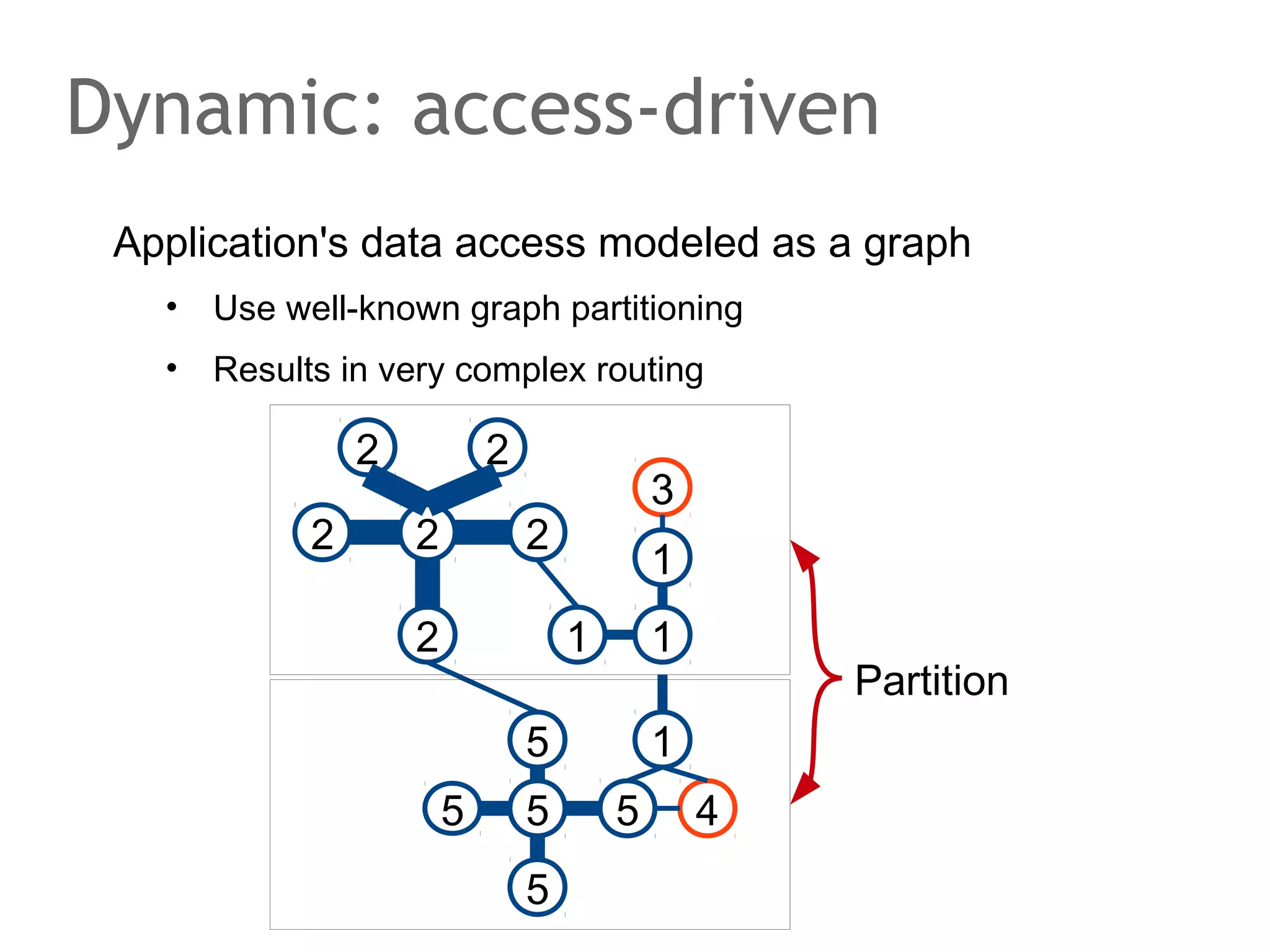
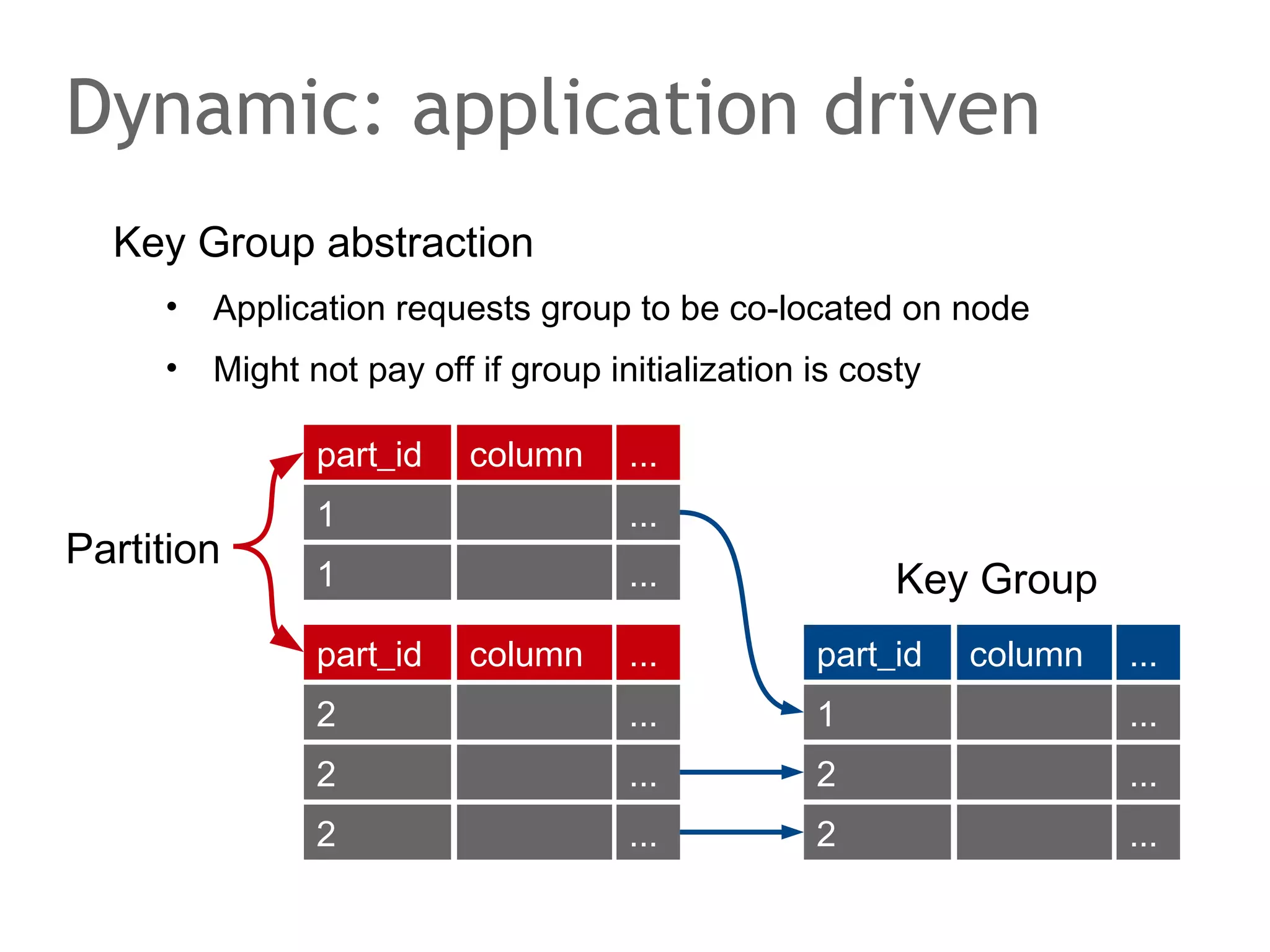
The document discusses the evolution of database systems, from traditional single-machine databases to modern scalable databases, highlighting the diversity of options available today. It covers essential concepts such as data models, schema design, normalization, and ACID transactions, emphasizing the complexities of developing applications that interact with large-scale databases. The presentation also touches on various database types, including relational and NoSQL models, and includes insights into query mechanisms and concurrency control.





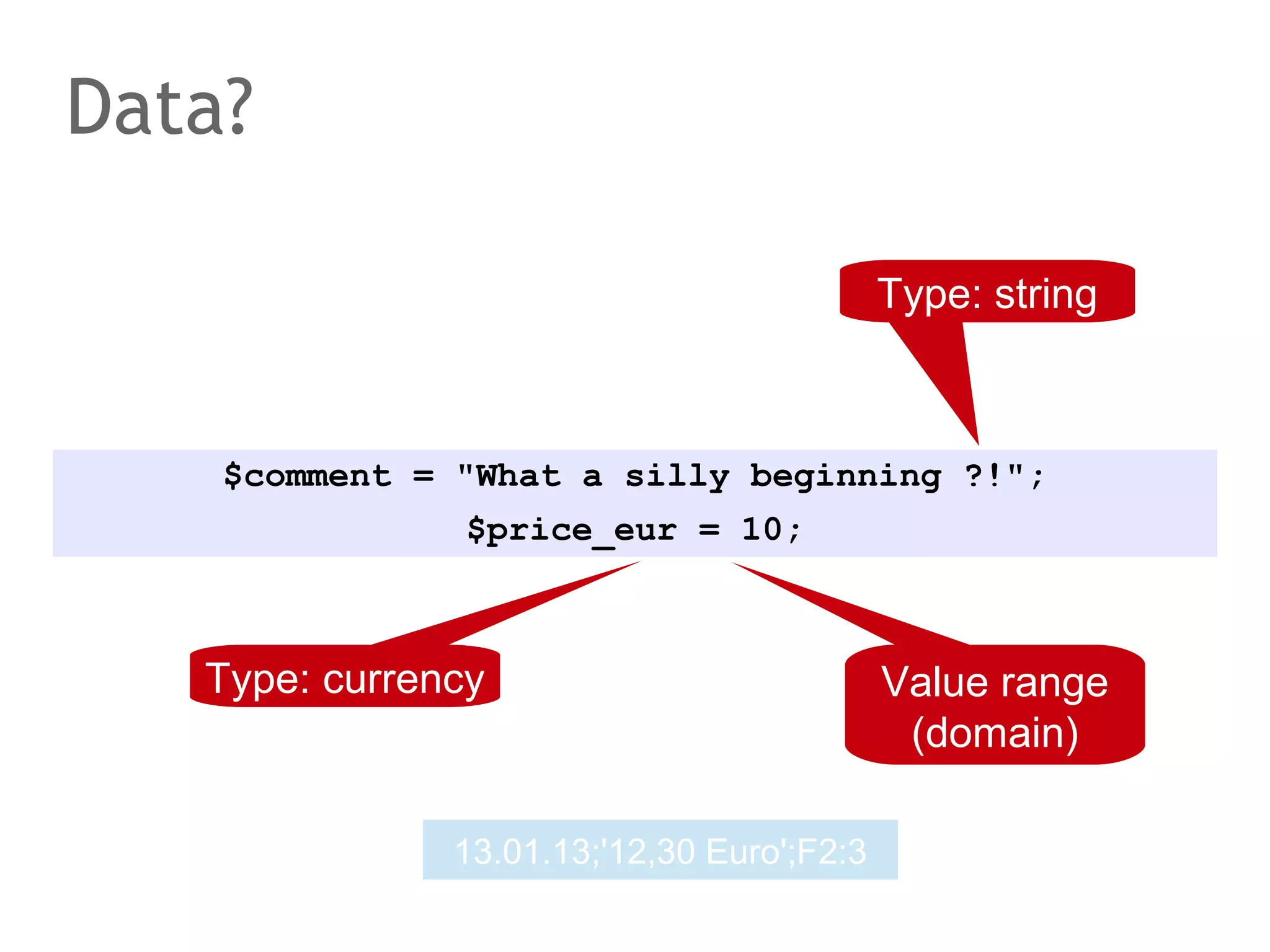
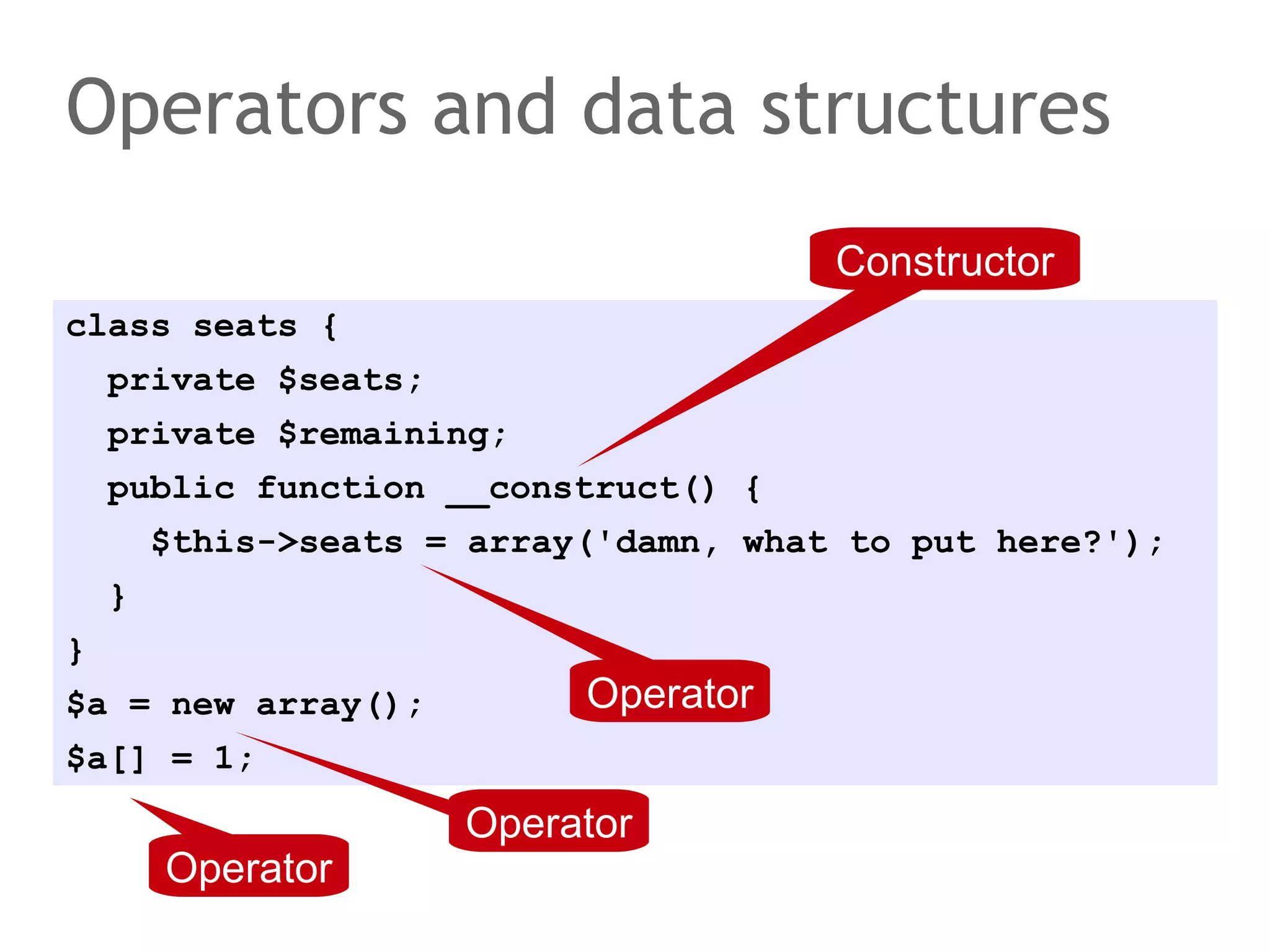



![Operators and data structures
Constructor
class seats {
private $seats;
private $remaining;
public function __construct() {
$this->seats = array('damn, what to put here?');
}
}
$a = new array();
Operator
$a[] = 1;
Operator
Operator](https://image.slidesharecdn.com/scalingdatabasestomillionofnodes-131202134855-phpapp01/75/Data-massage-How-databases-have-been-scaled-from-one-to-one-million-nodes-11-2048.jpg)

![State changes over time
class ticket {
private $seats;
…
public function addSeat(Seat $seat) {
$seats[] = $seat;
State1 at t1
}
}
$t = new ticket();
$t->addSeat(new Seat(1, 1, 9.99));
State2 at t2](https://image.slidesharecdn.com/scalingdatabasestomillionofnodes-131202134855-phpapp01/75/Data-massage-How-databases-have-been-scaled-from-one-to-one-million-nodes-13-2048.jpg)
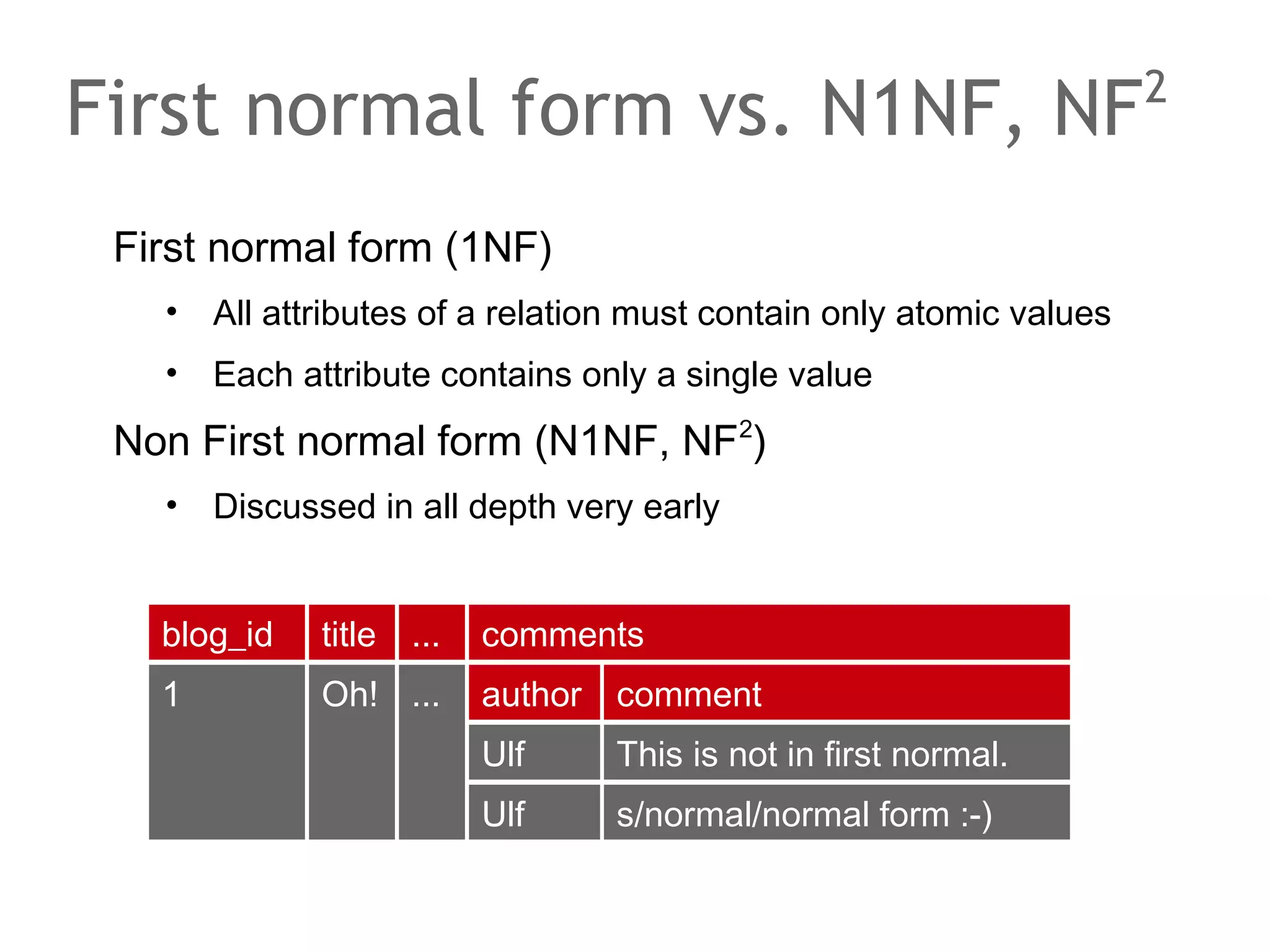




















![Physical level, very briefly
SQL tables, views and indices
•
B[+|*]-tree
•
Search, Insert, Delete: O(log n)
•
Clustered Index
Disk level
•
Pages
•
Caching usually handled by specialized block managers](https://image.slidesharecdn.com/scalingdatabasestomillionofnodes-131202134855-phpapp01/75/Data-massage-How-databases-have-been-scaled-from-one-to-one-million-nodes-39-2048.jpg)








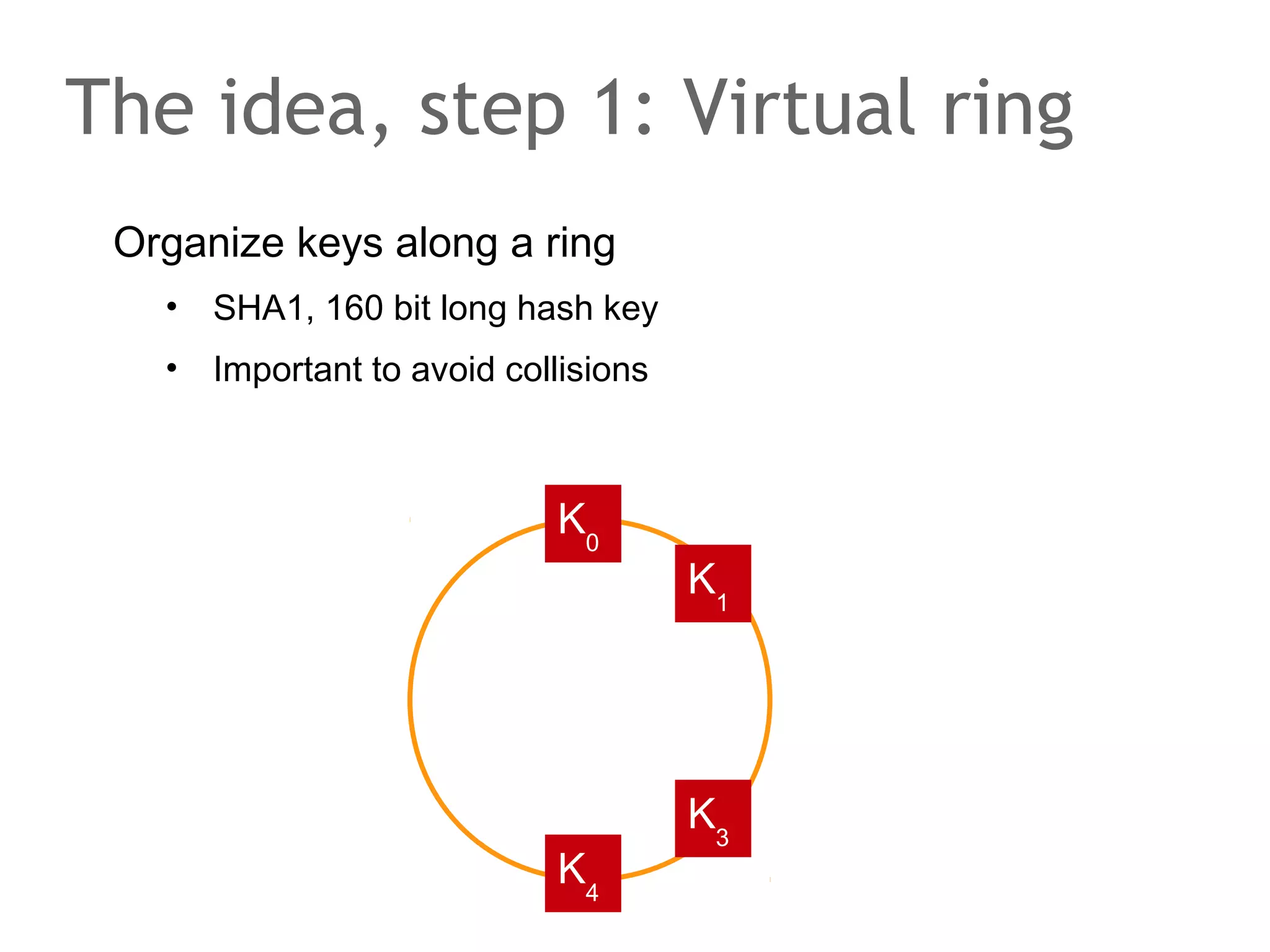
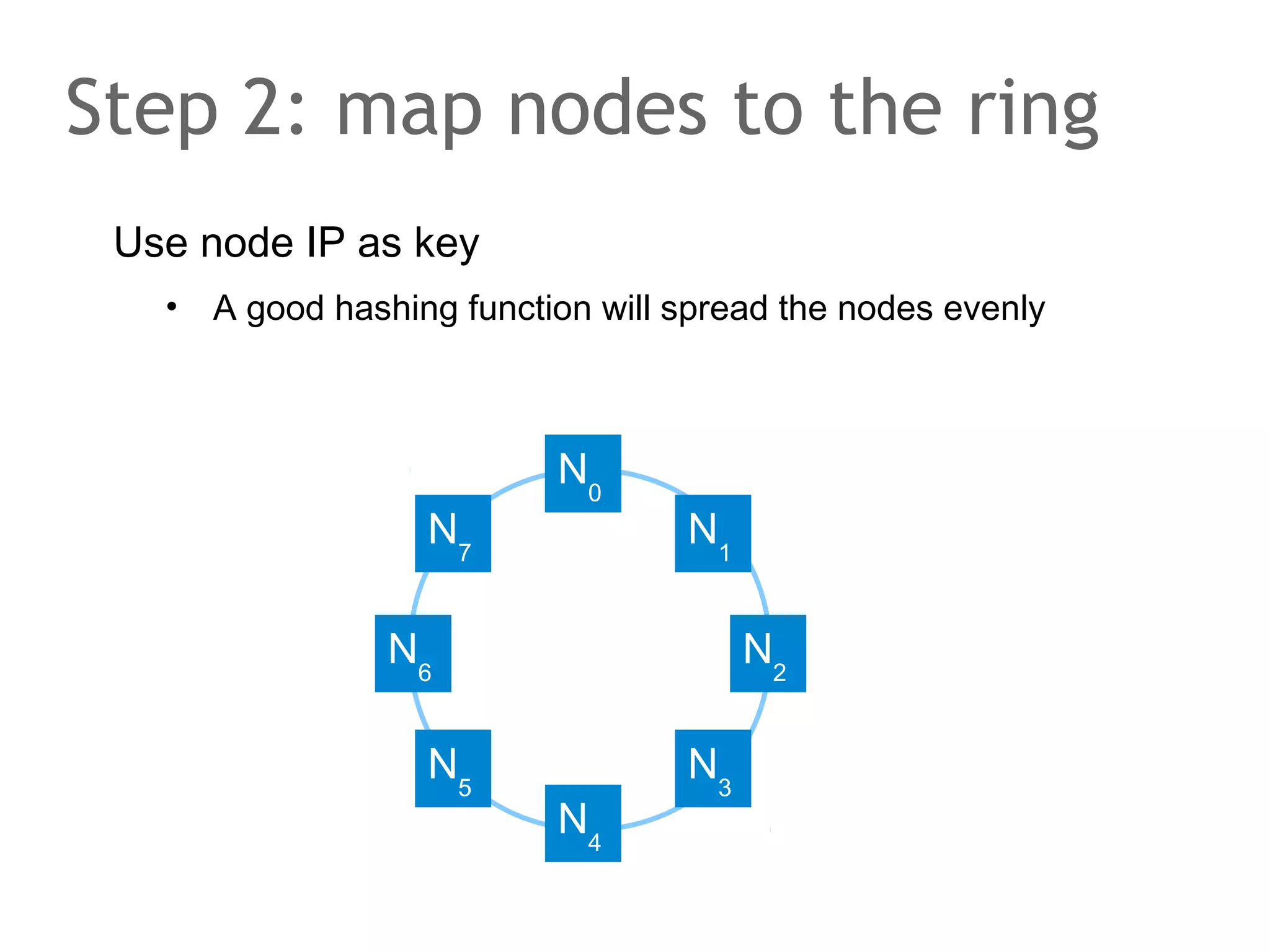
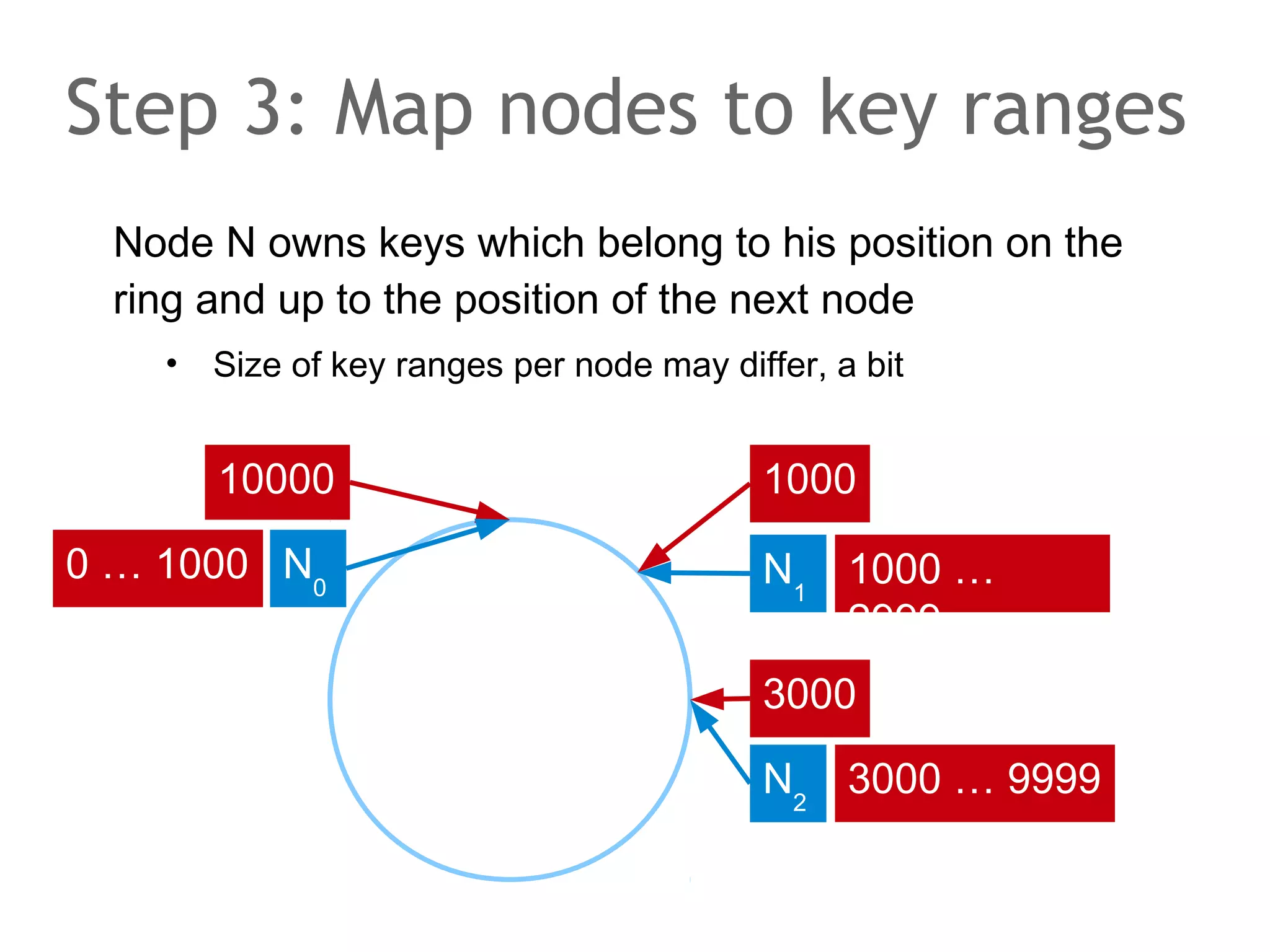

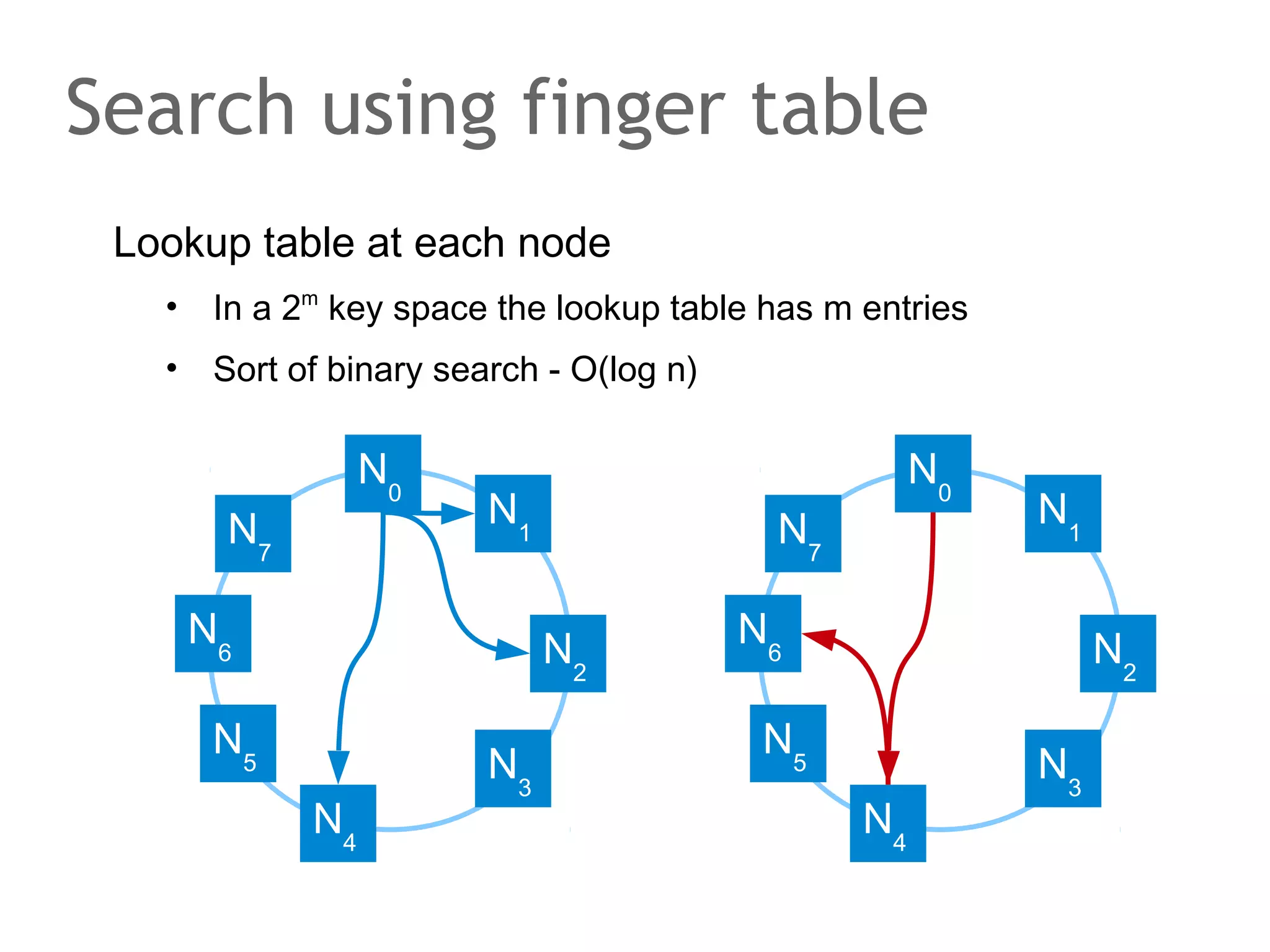

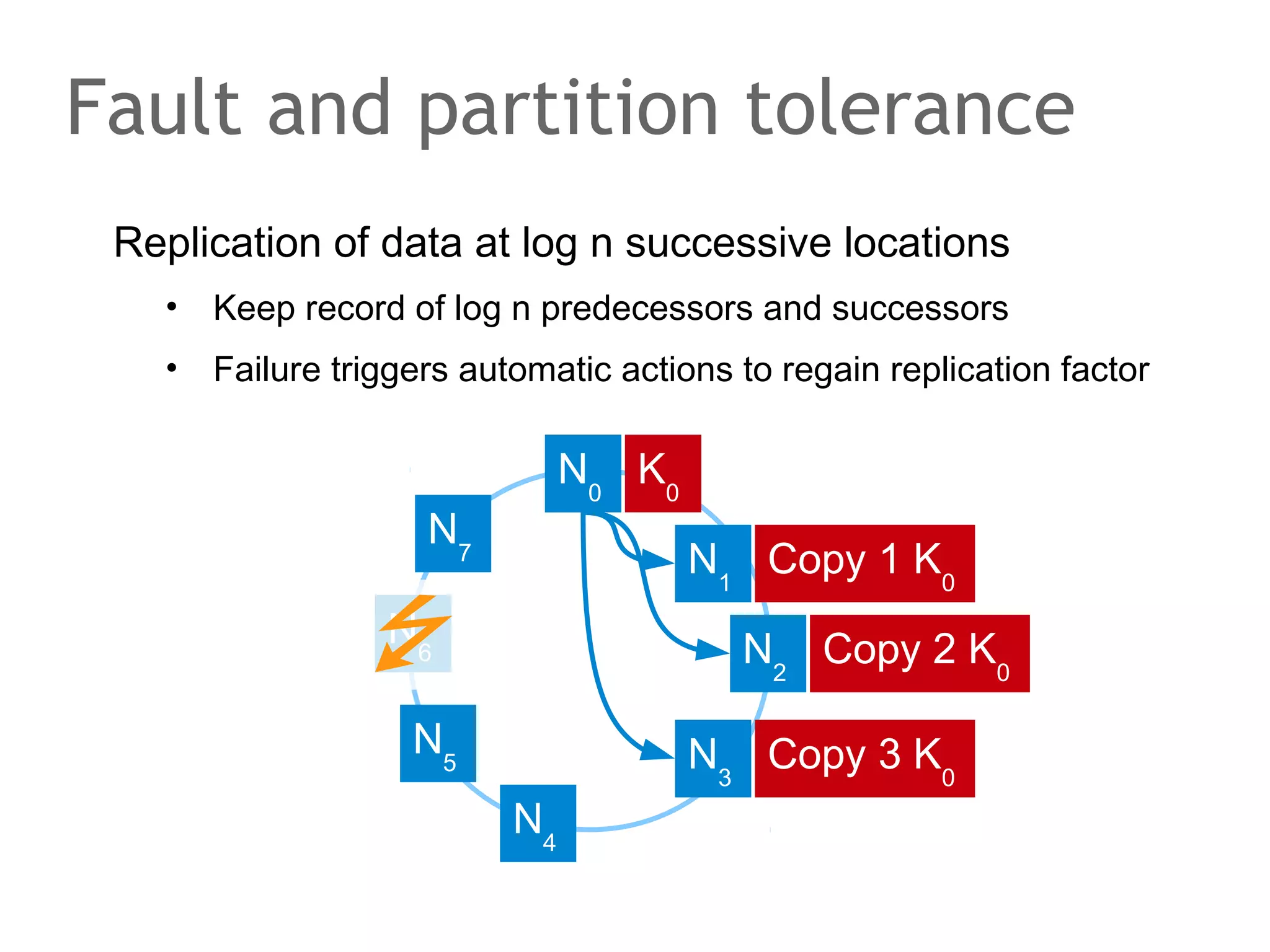
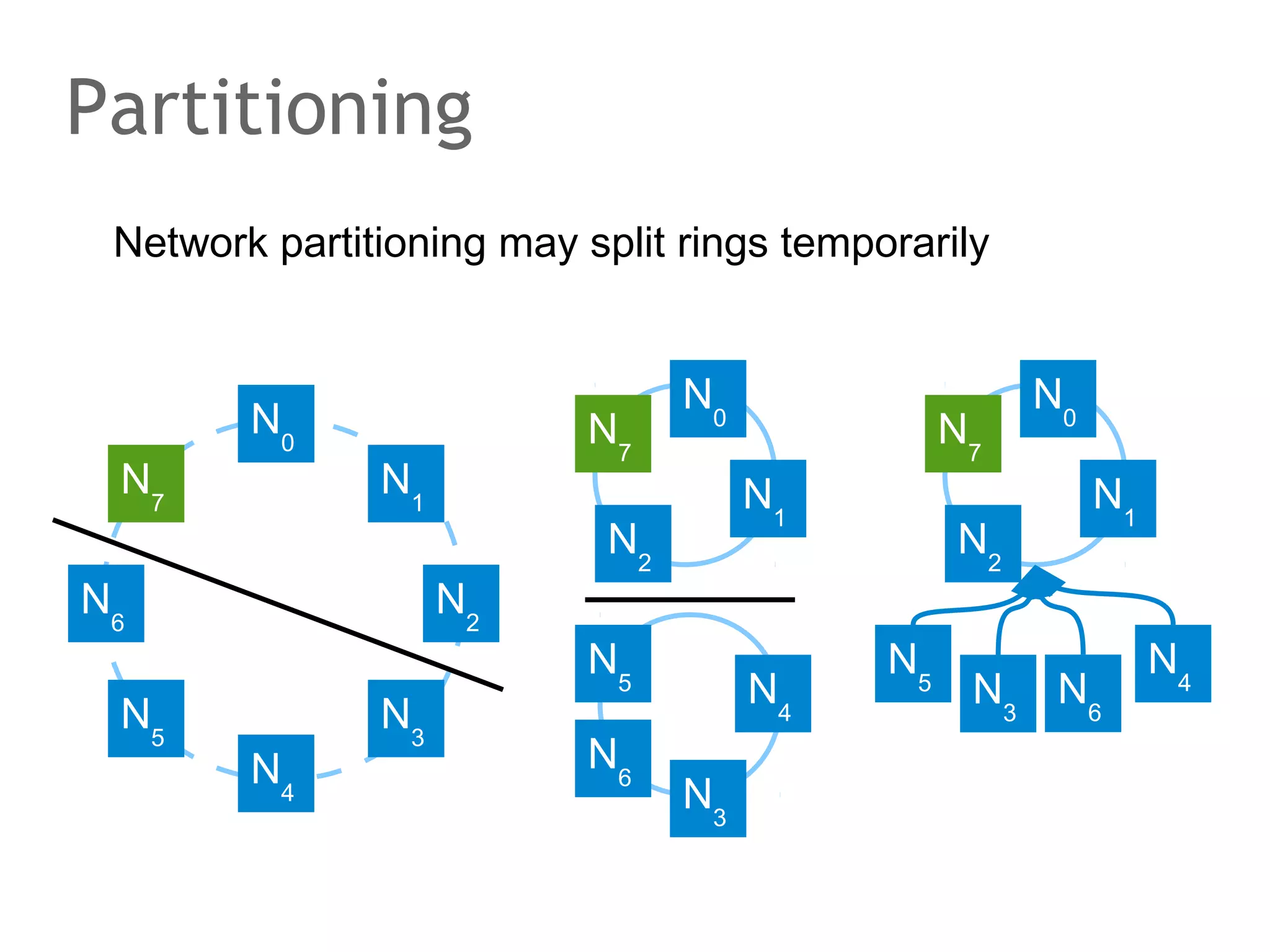
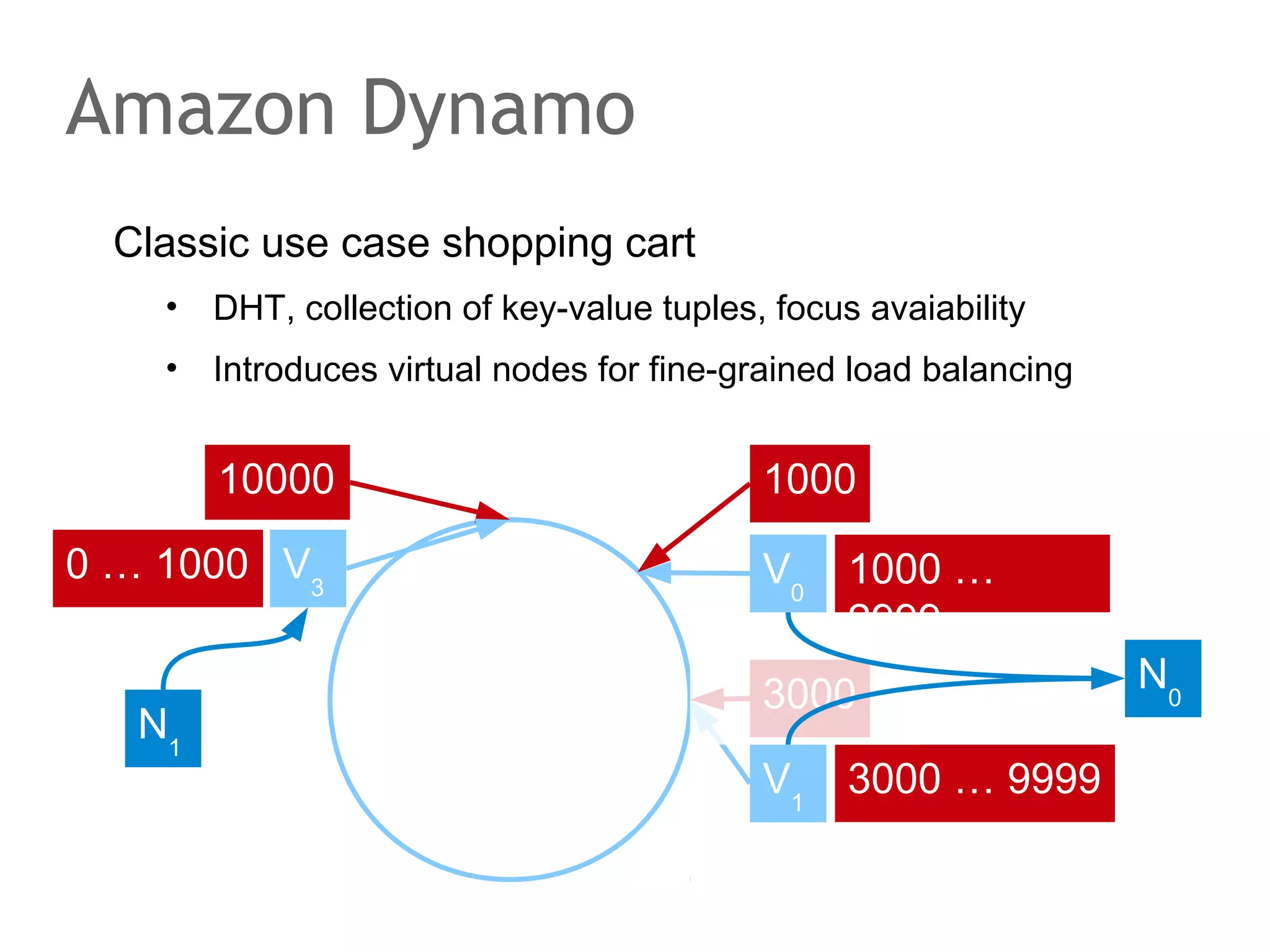
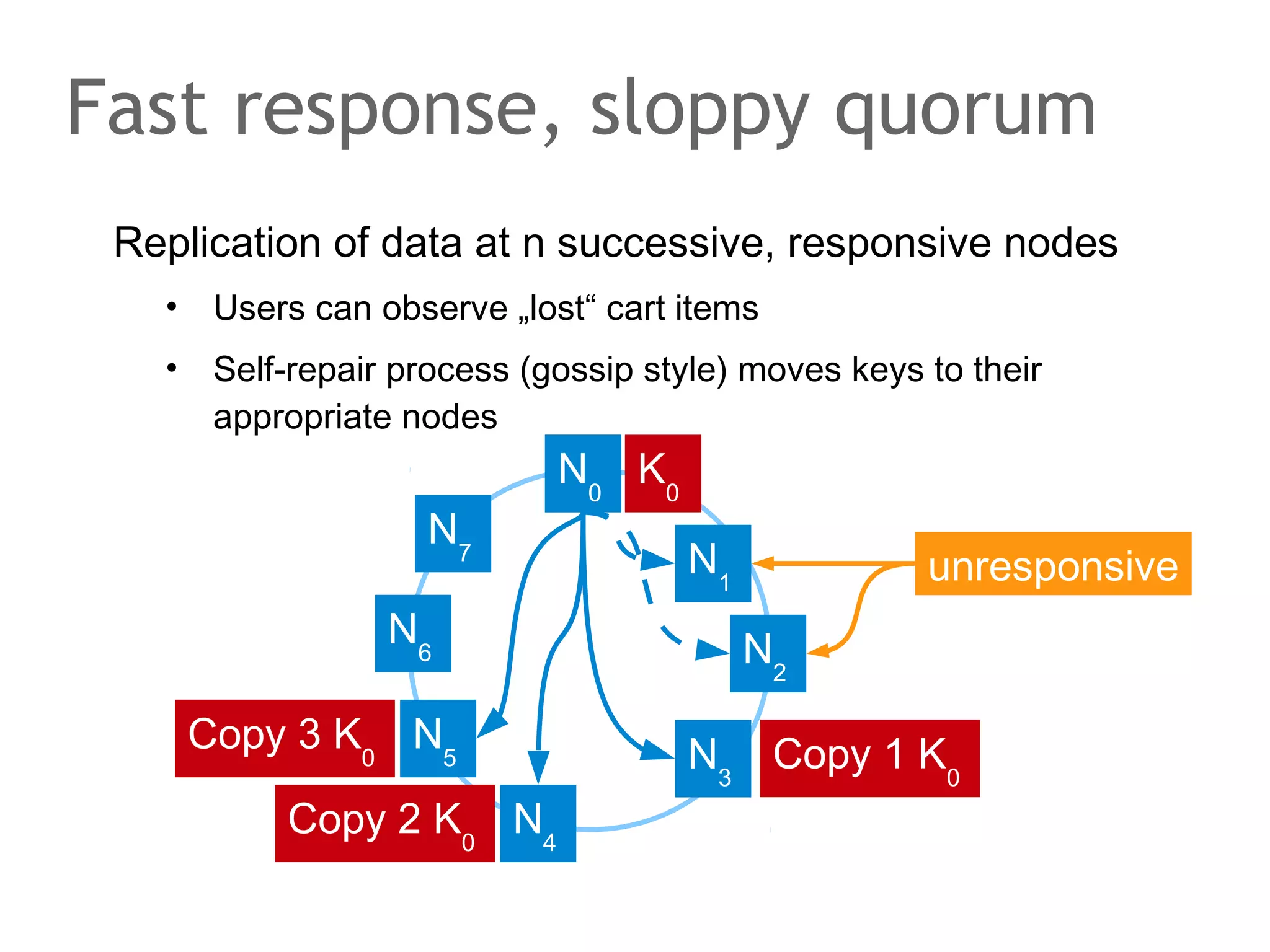
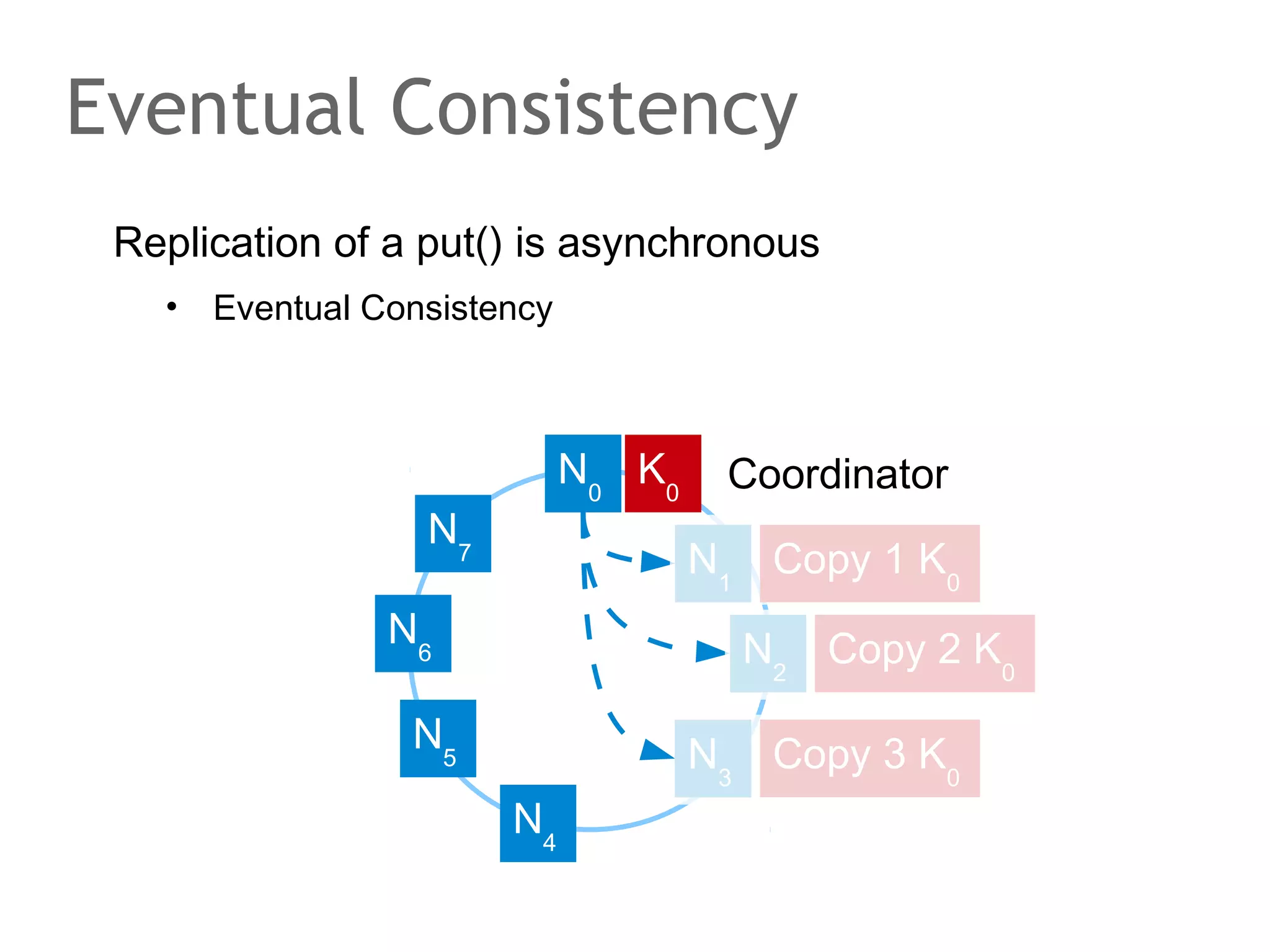

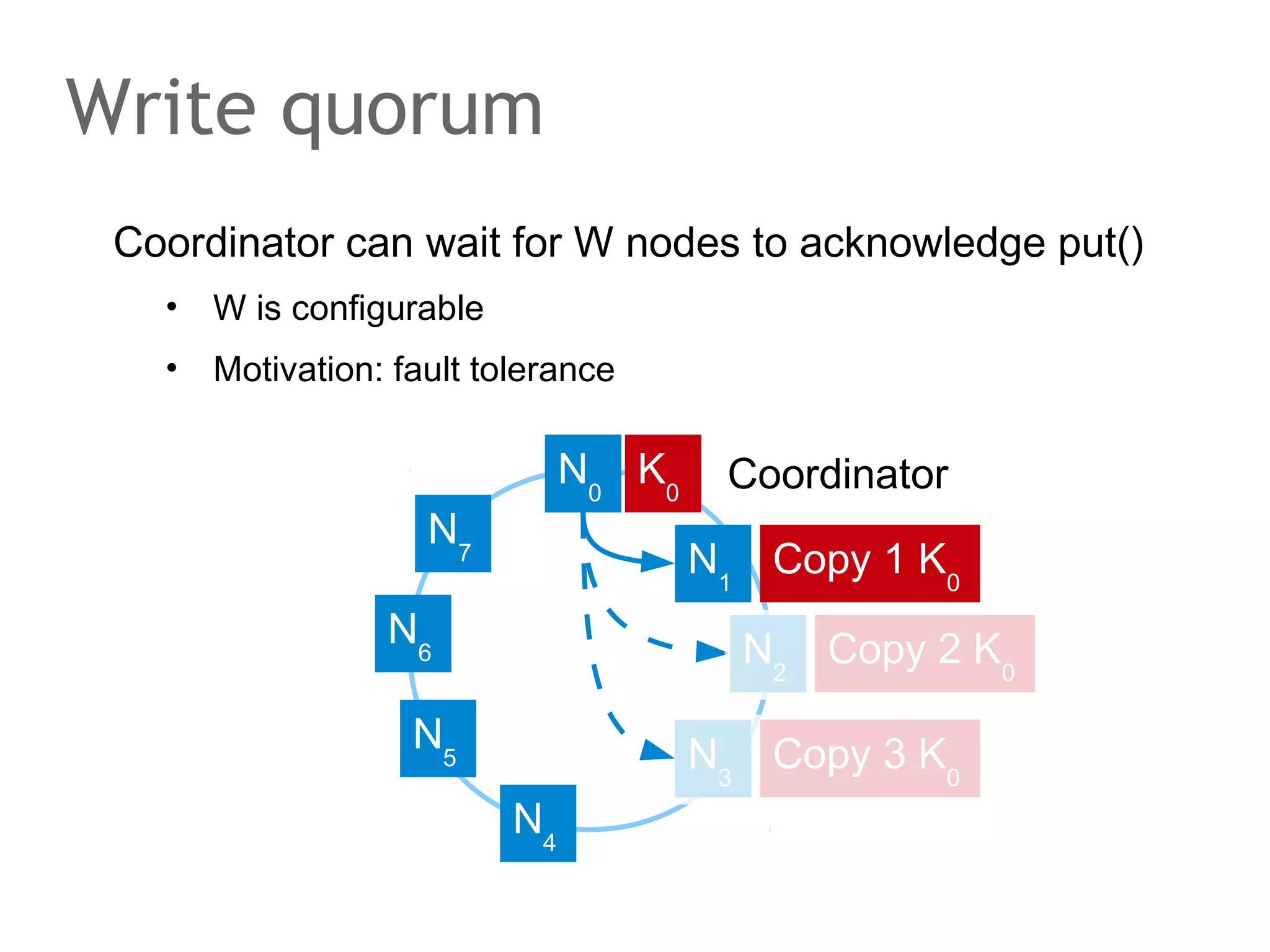
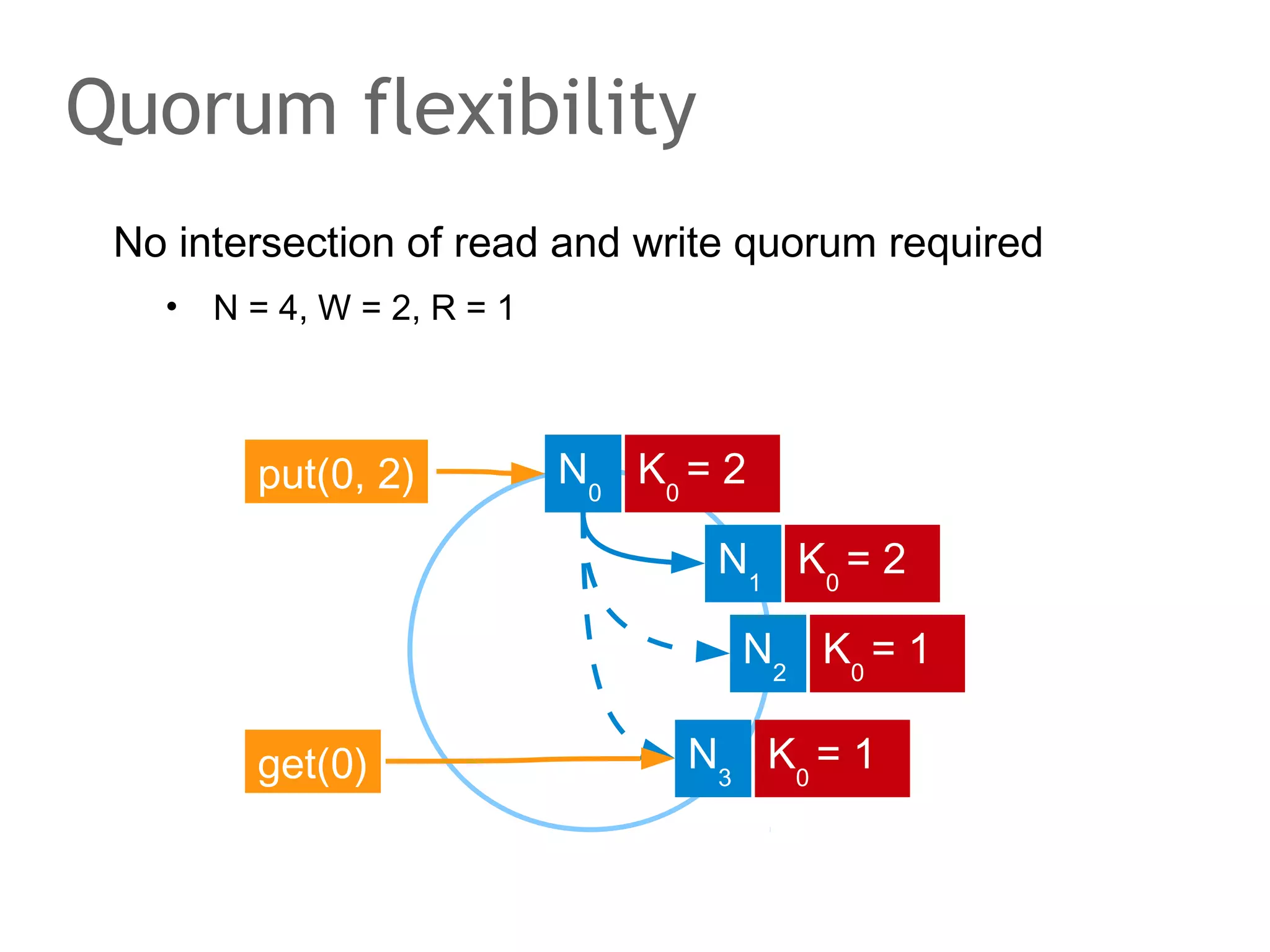

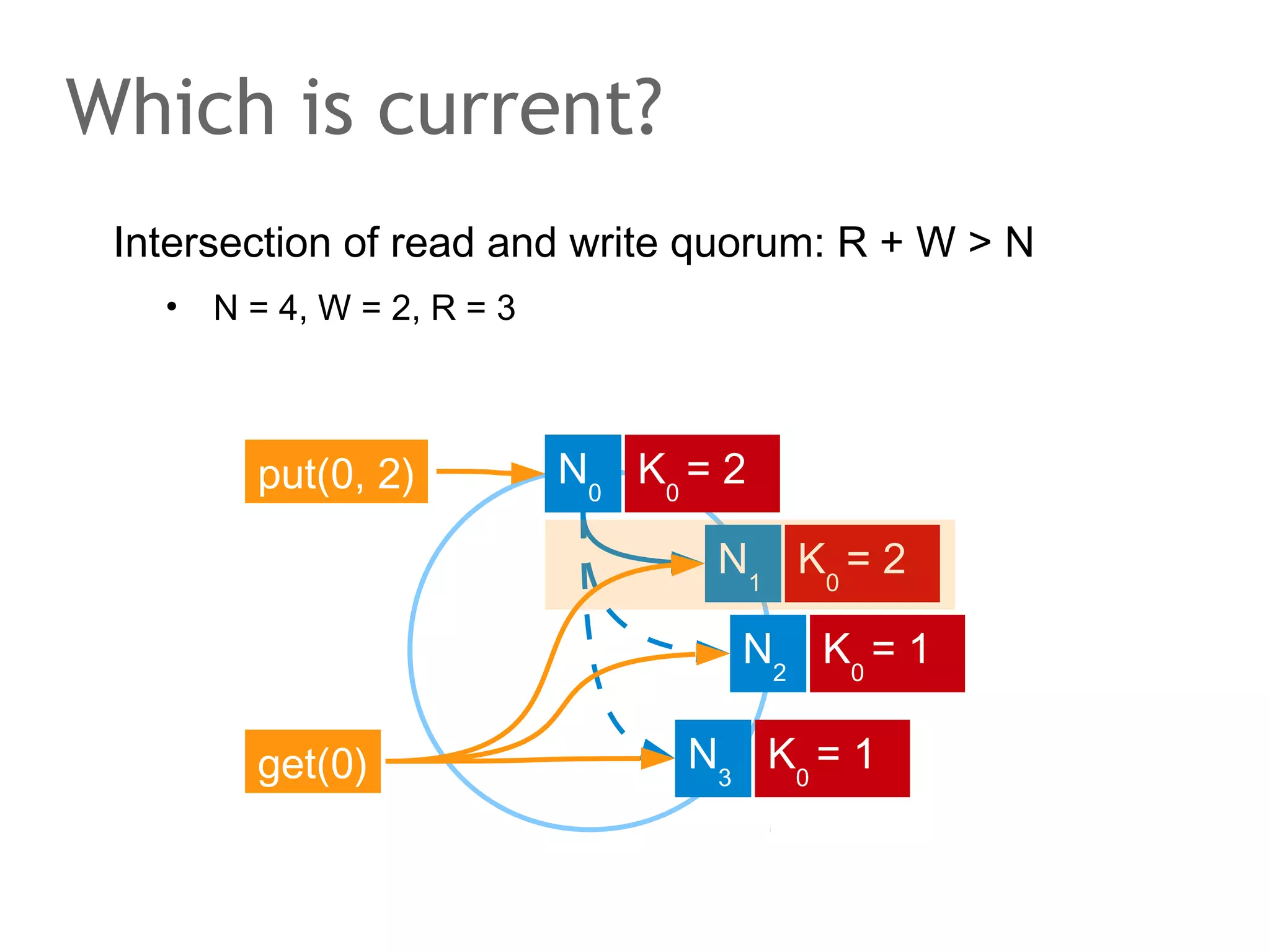


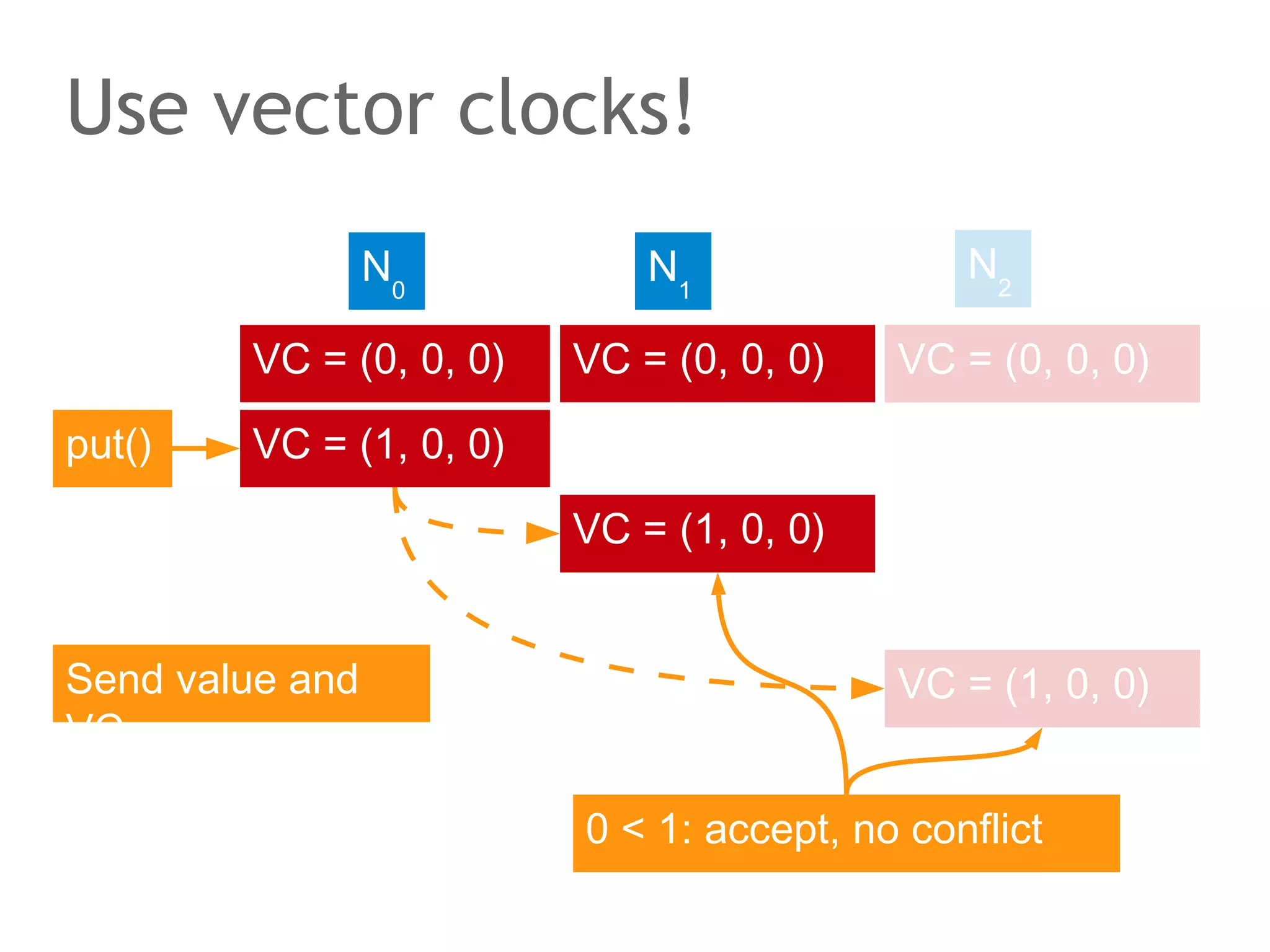
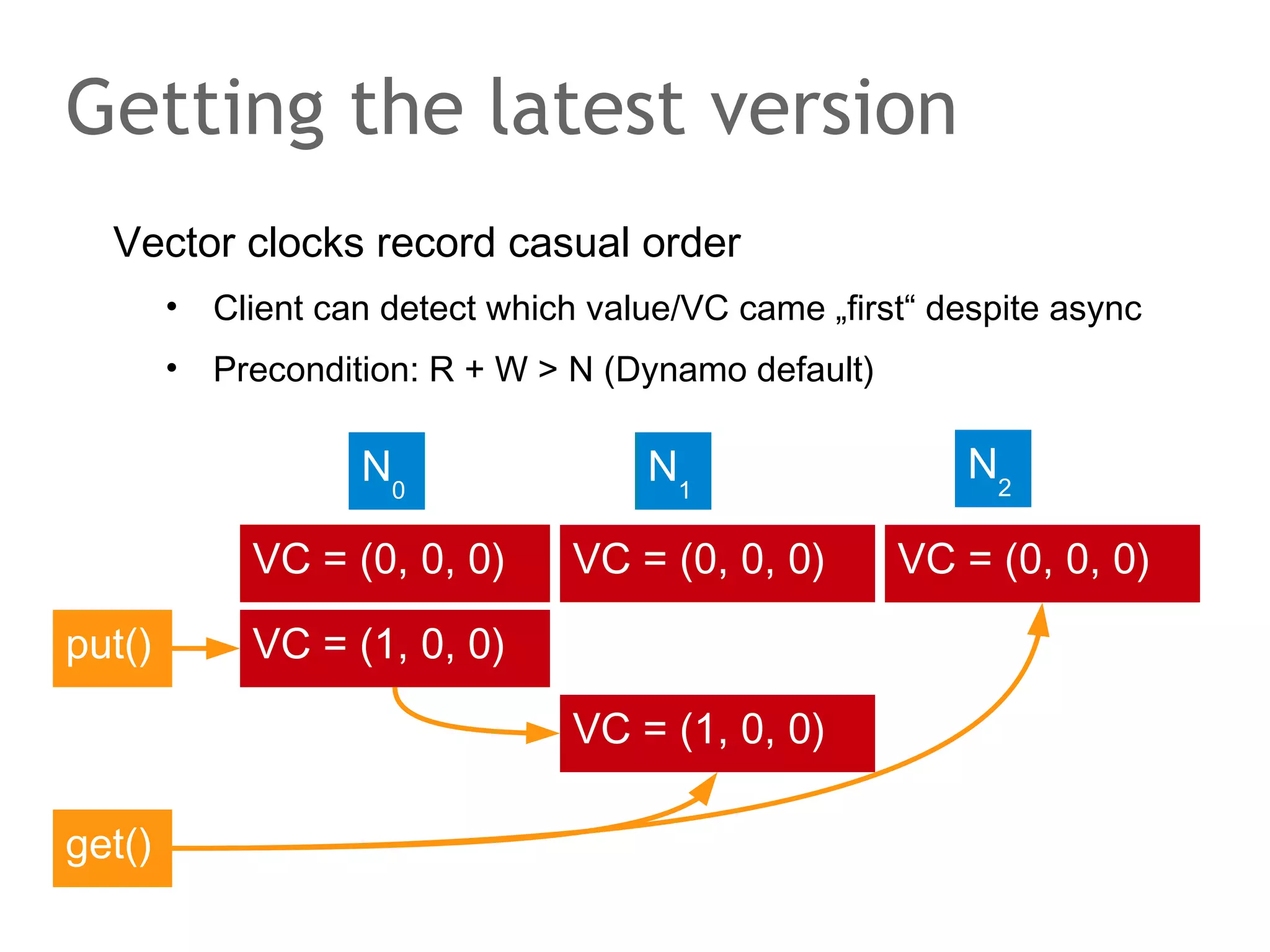
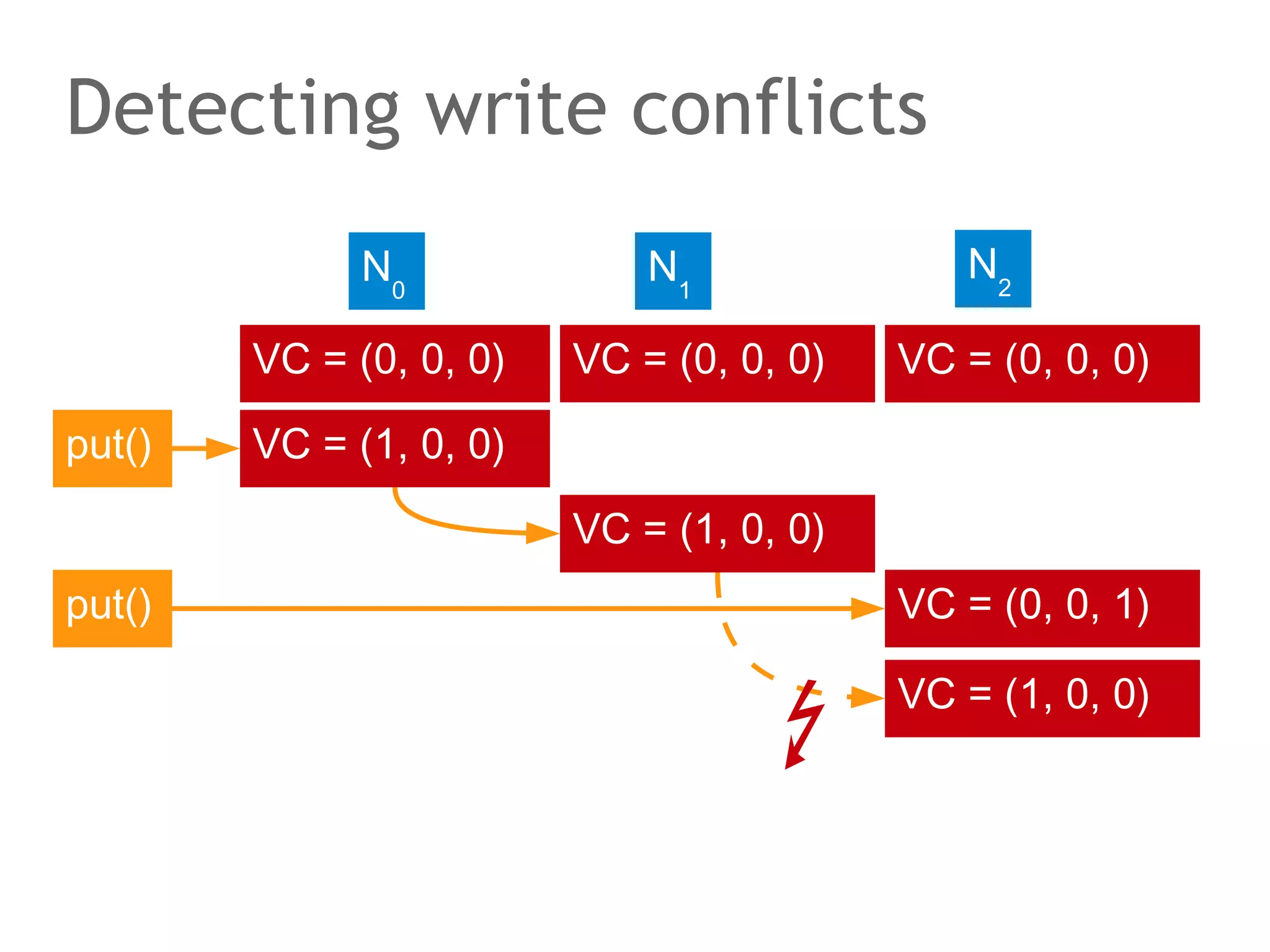
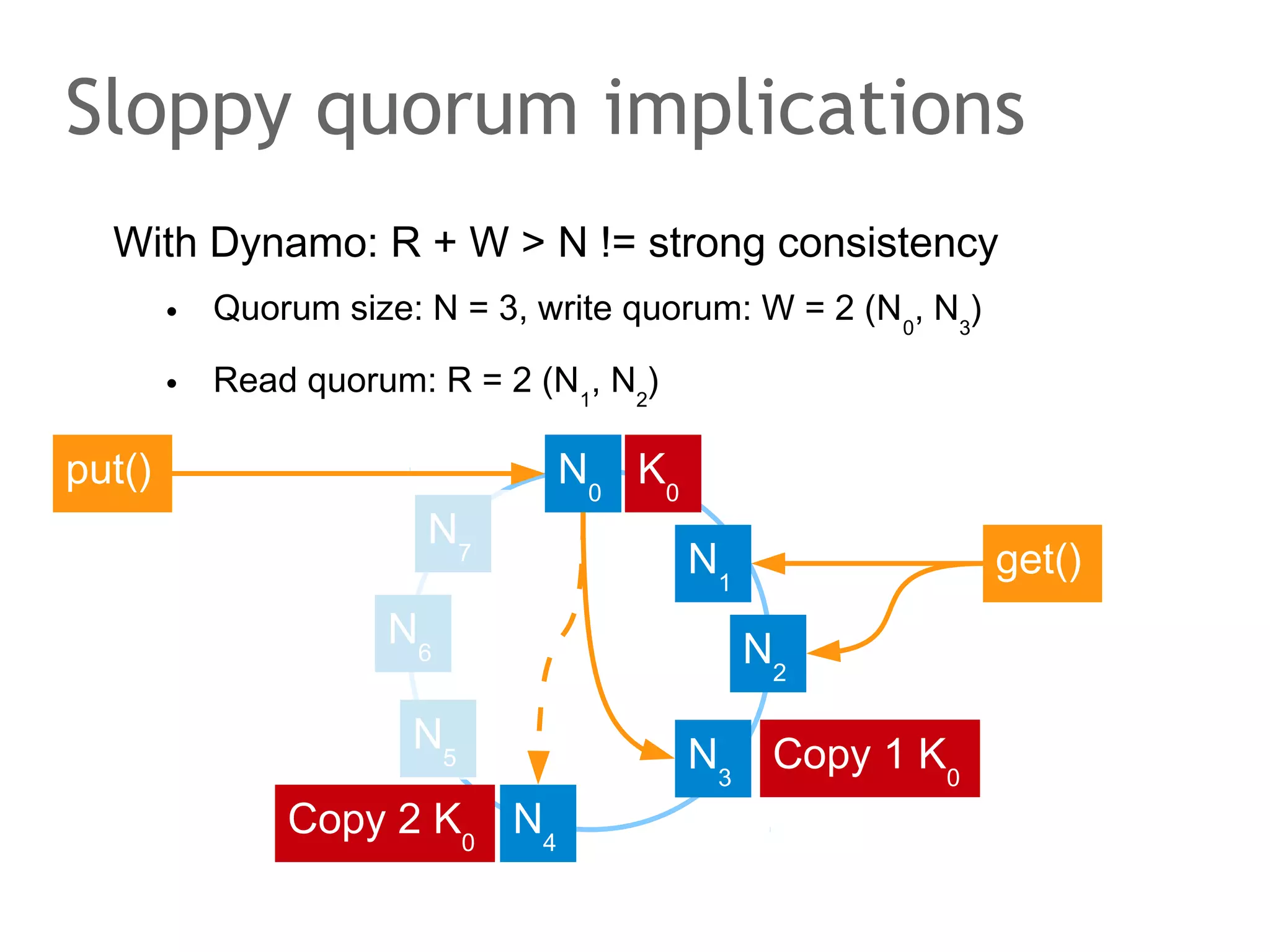


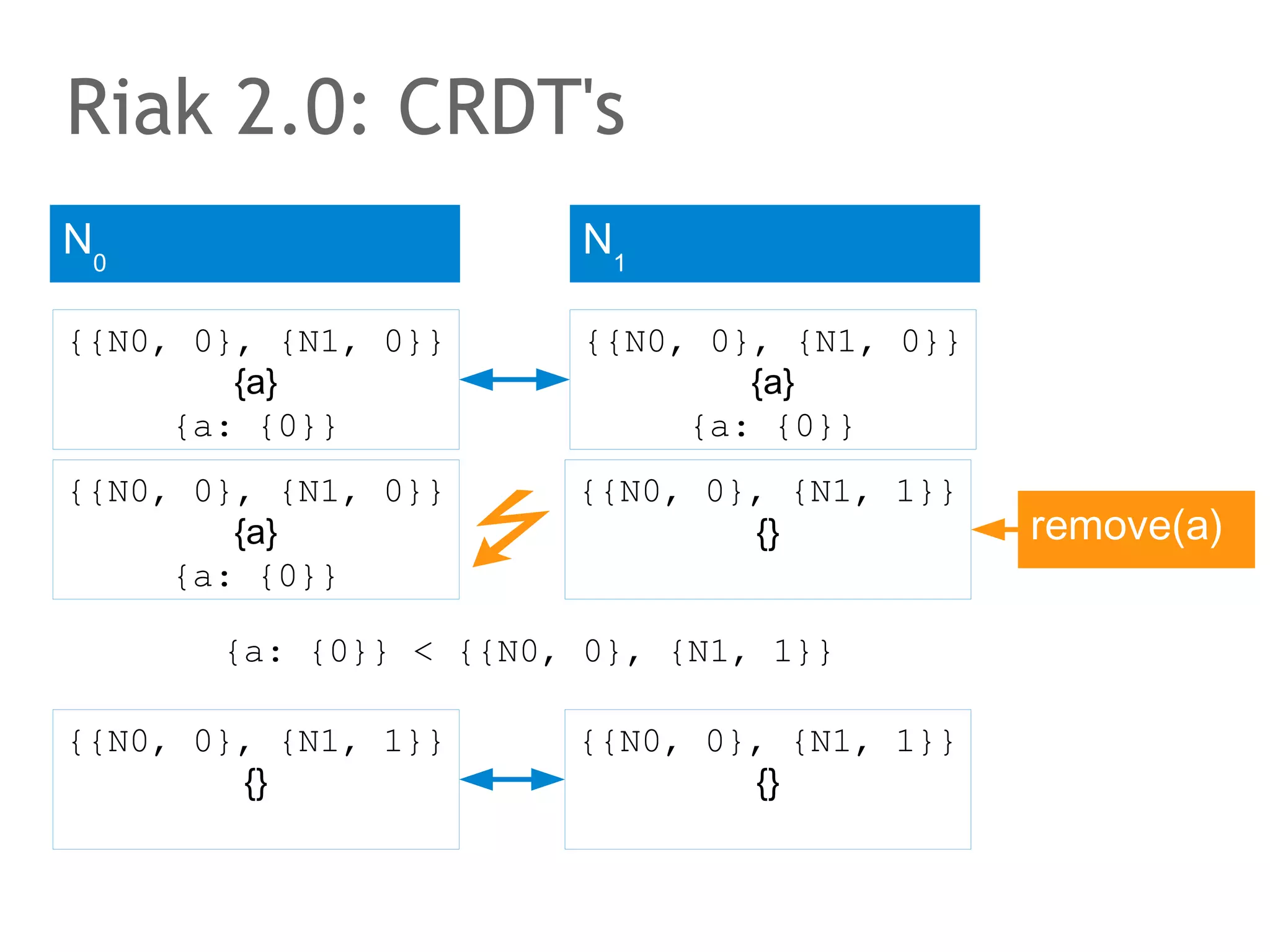

















![The speaker says...
A quorum for which R + W > N is true ensures that the read
and write quorums intersect. Thus, in a classical system,
strong consistency can be achieved without having to wait
for all replicas to apply the latest changes (ROWA[A]).
In the example, the put() and get() operations intersect at
node N1. But how would the client that has issued the get()
know whether the value returned from N1, N2 or N3 is the
current one?](https://image.slidesharecdn.com/scalingdatabasestomillionofnodes-131202134855-phpapp01/75/Data-massage-How-databases-have-been-scaled-from-one-to-one-million-nodes-115-2048.jpg)









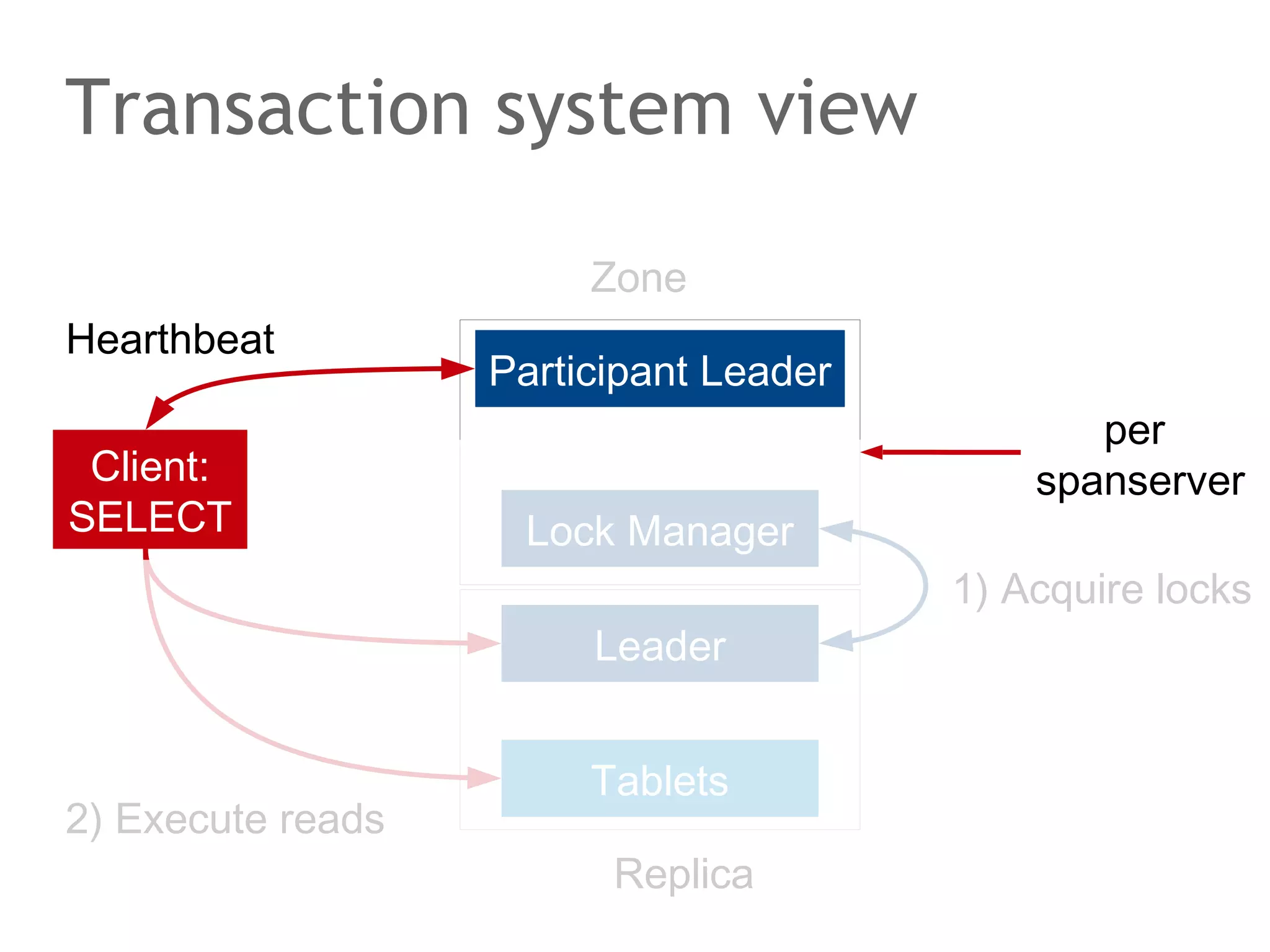
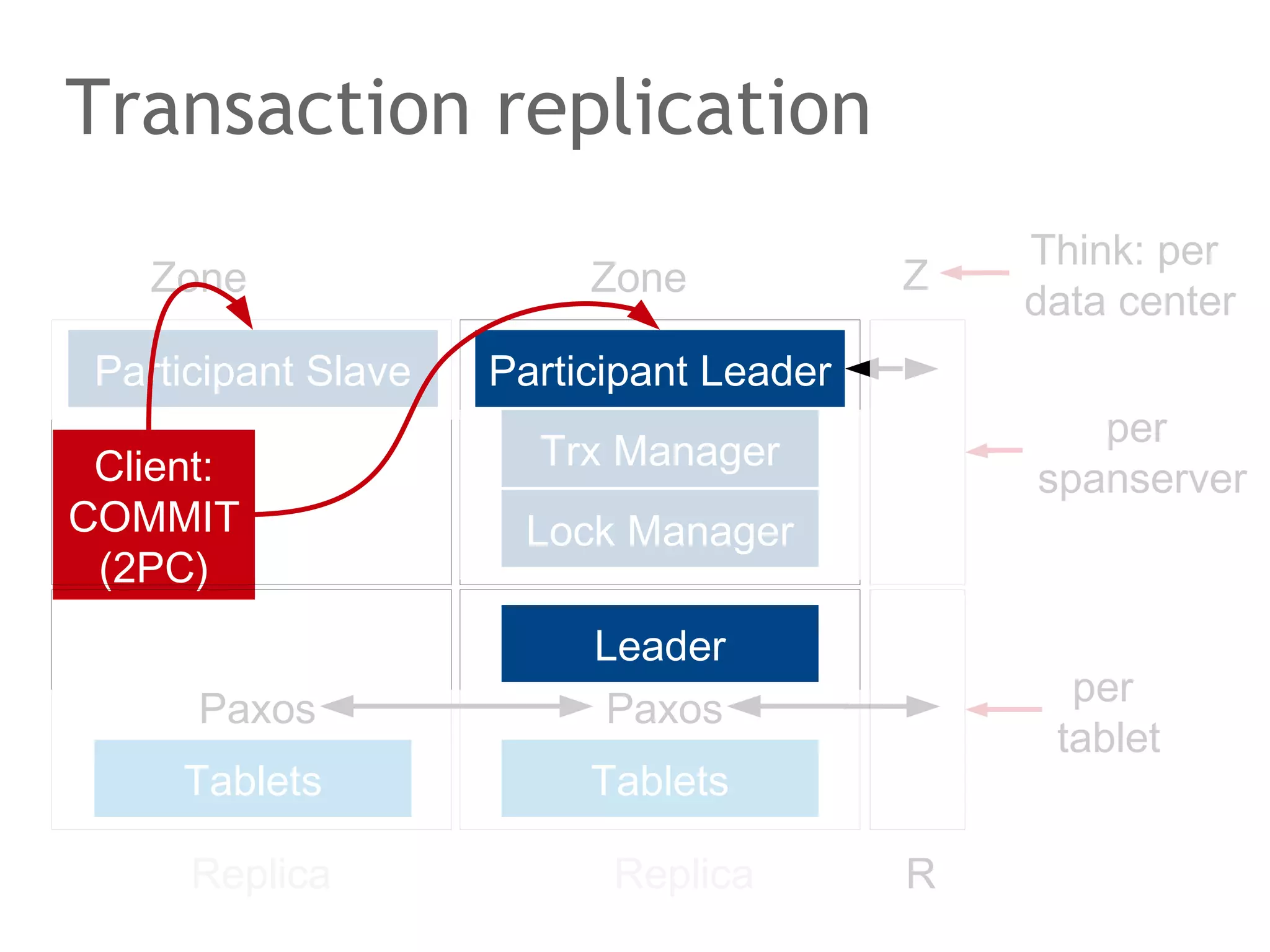
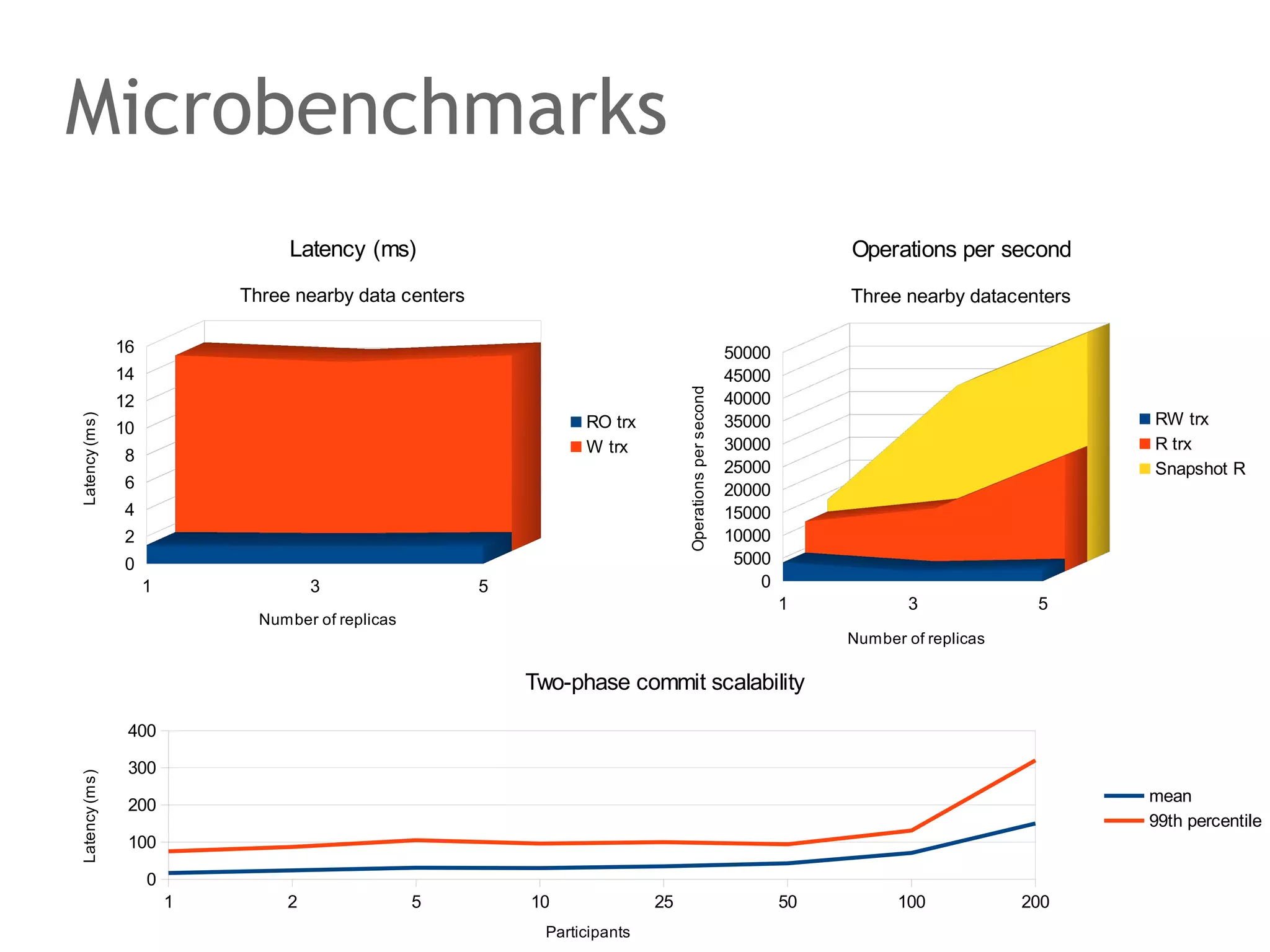







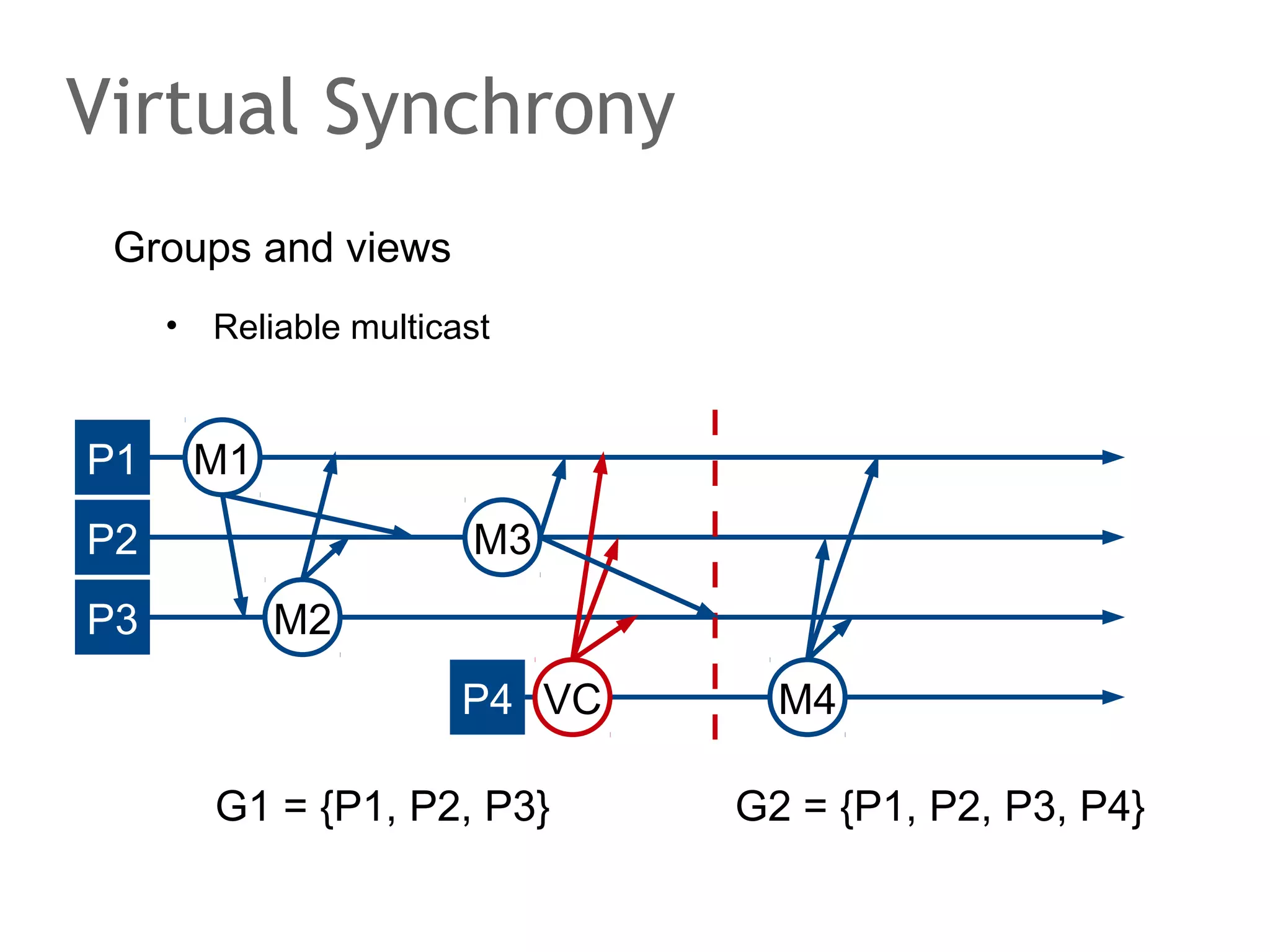










![The Consensus problem
It is impossible for a set of processors in an asynchronous
sytem to agree on a binary value, even if only a single
process is subject to an unannounced failure.
Impossibility of Distributed Consensus with One Faulty
Process, Fischer-Lynch-Paterson, 1985:
„We have shown that a natural and important
problem of fault-tolerant cooperative computing
cannot be solved in a totally asynchronous
model of computation. These results do not show
that such problems cannot be “solved” in
practice;[...]“](https://image.slidesharecdn.com/scalingdatabasestomillionofnodes-131202134855-phpapp01/75/Data-massage-How-databases-have-been-scaled-from-one-to-one-million-nodes-158-2048.jpg)





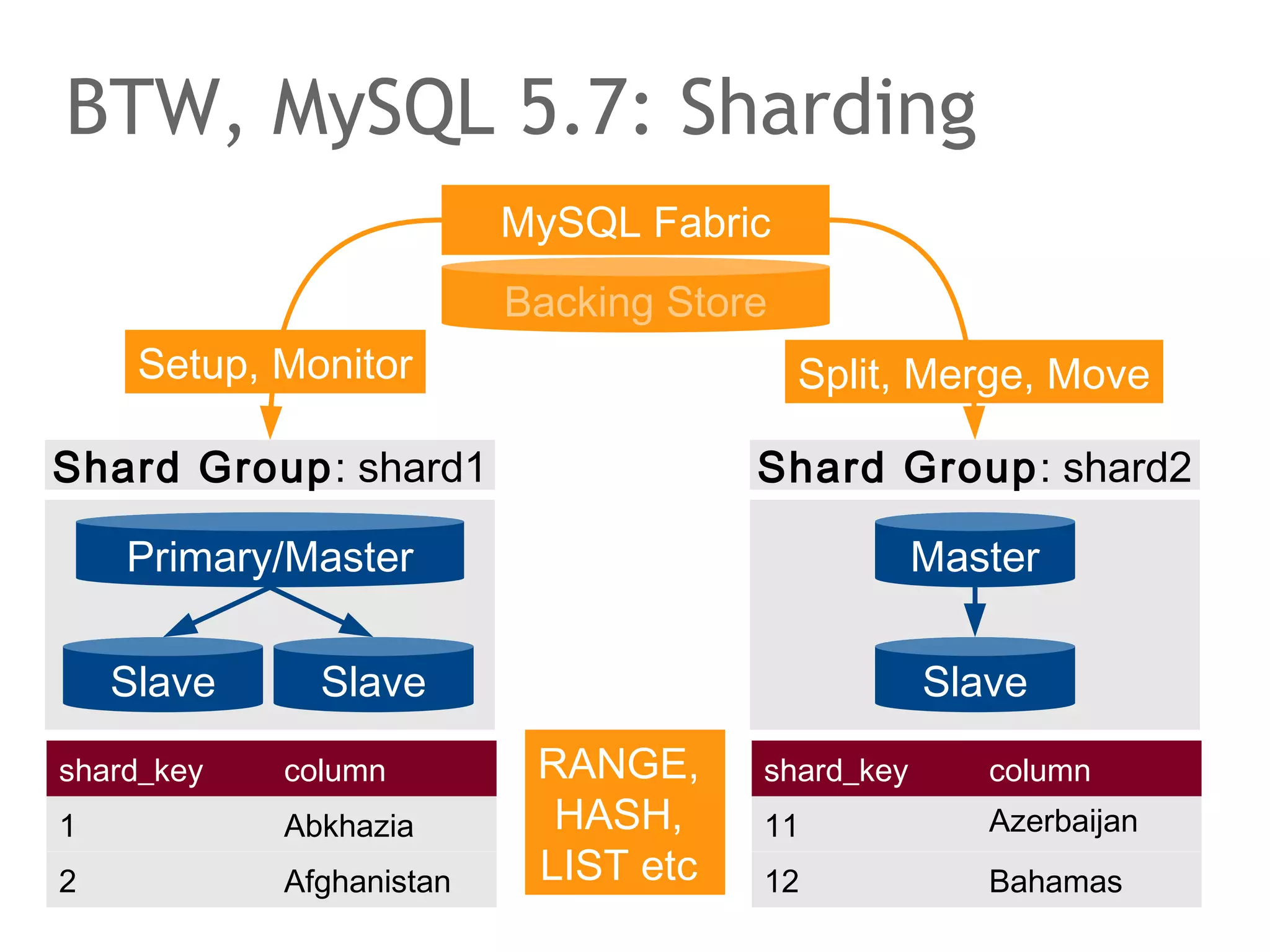
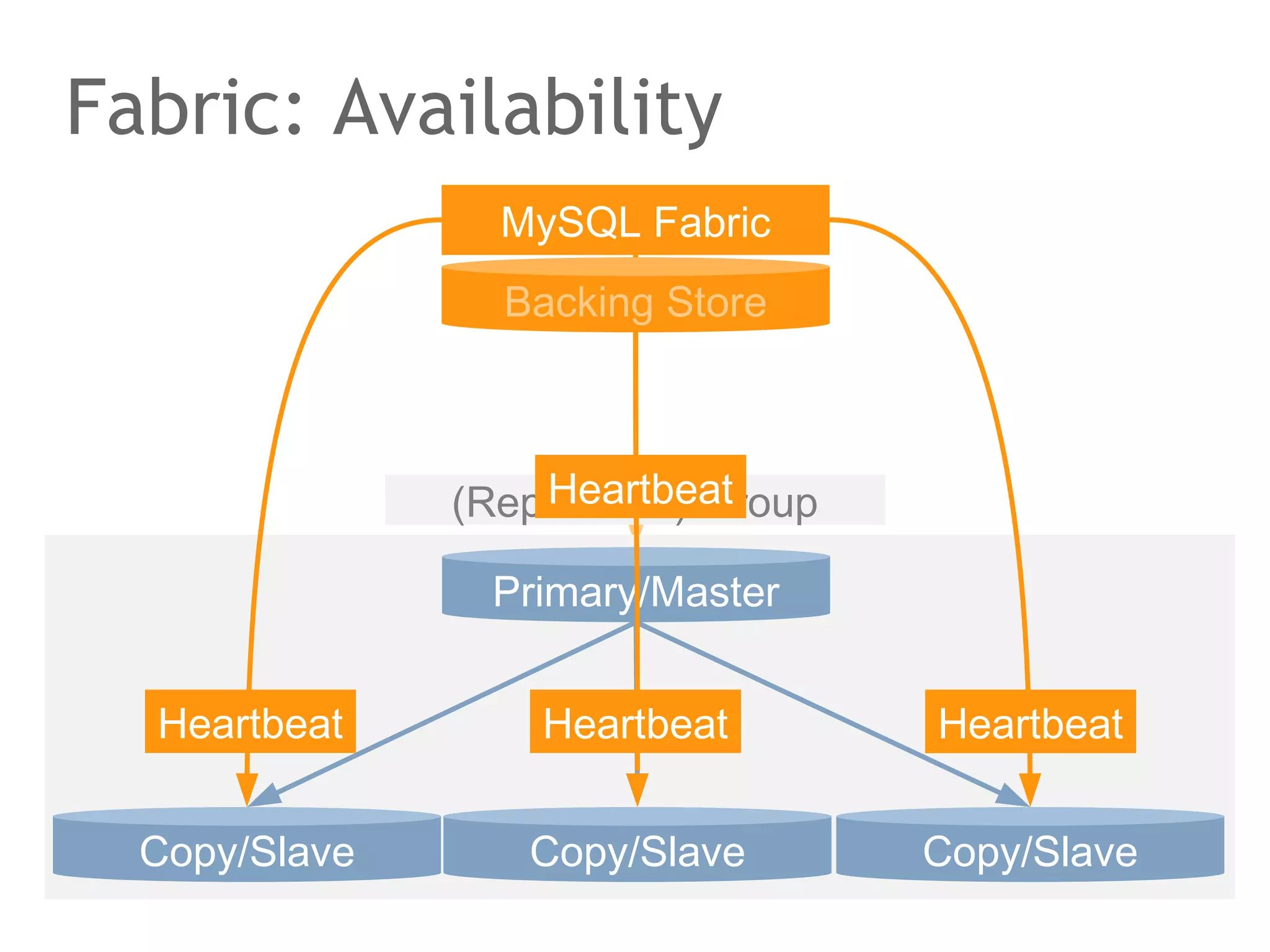
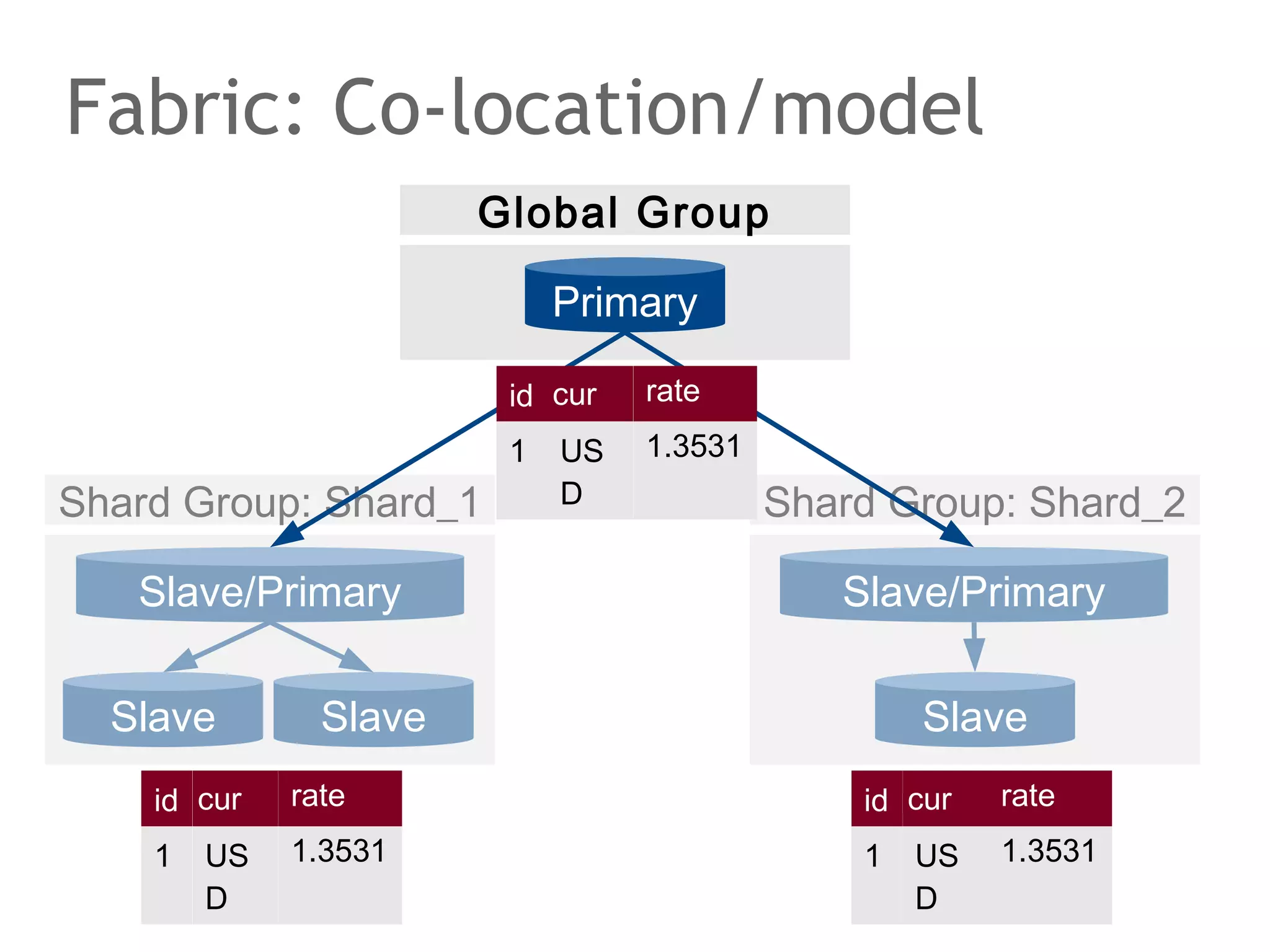
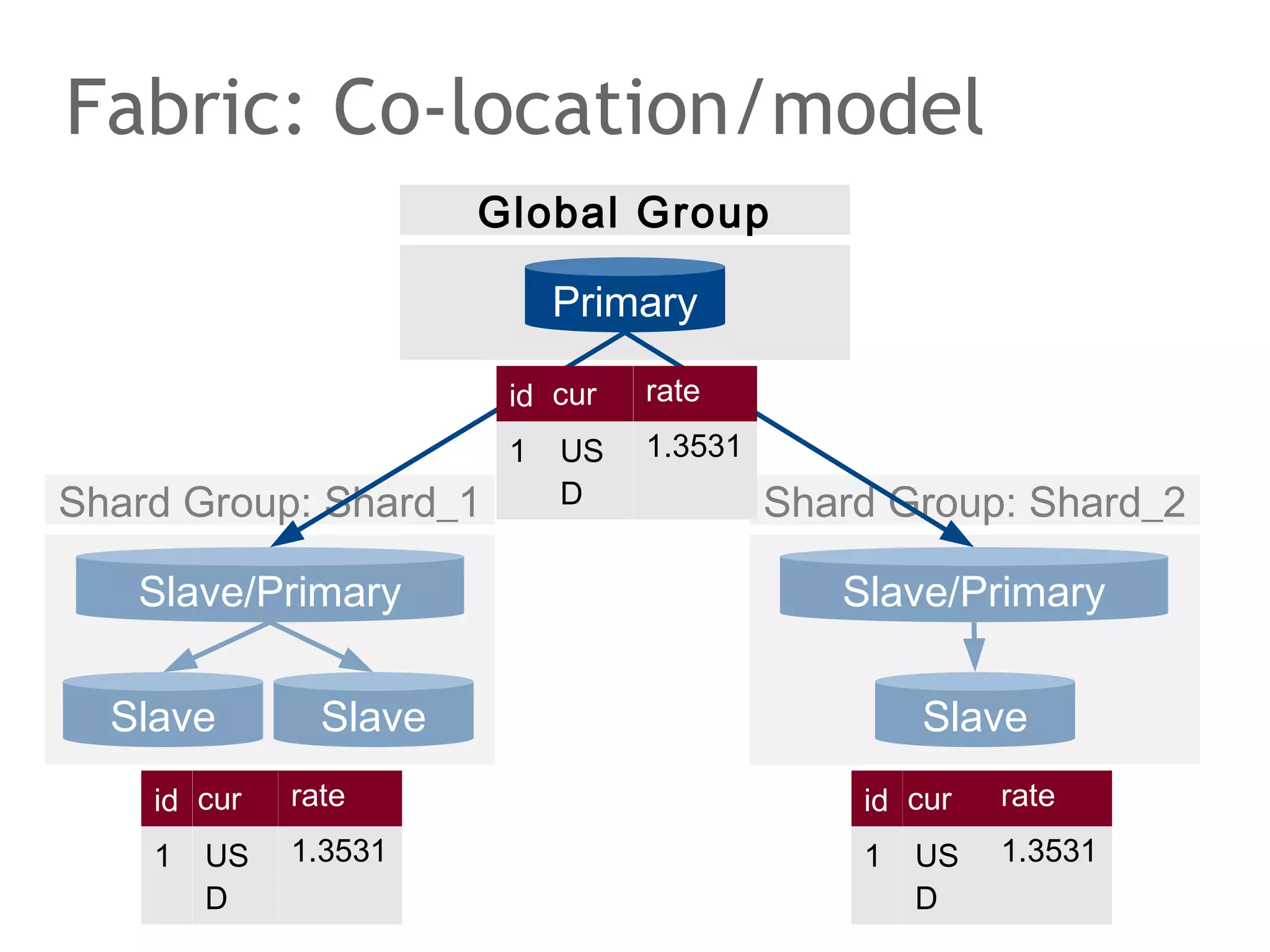

































![Google Spanner
Structured key value store
•
Distributed multi-dimensional map:
(key [, timestamp]) → string
•
F1 advertising backend (goodbye MySQL!), ...
•
Schematized semi-relational tables
•
ACID transactions
•
Declarative SQL-based query language
•
MapReduce
•
Unique TrueTime API
•
Synchronous replication among data centers](https://image.slidesharecdn.com/scalingdatabasestomillionofnodes-131202134855-phpapp01/75/Data-massage-How-databases-have-been-scaled-from-one-to-one-million-nodes-210-2048.jpg)













































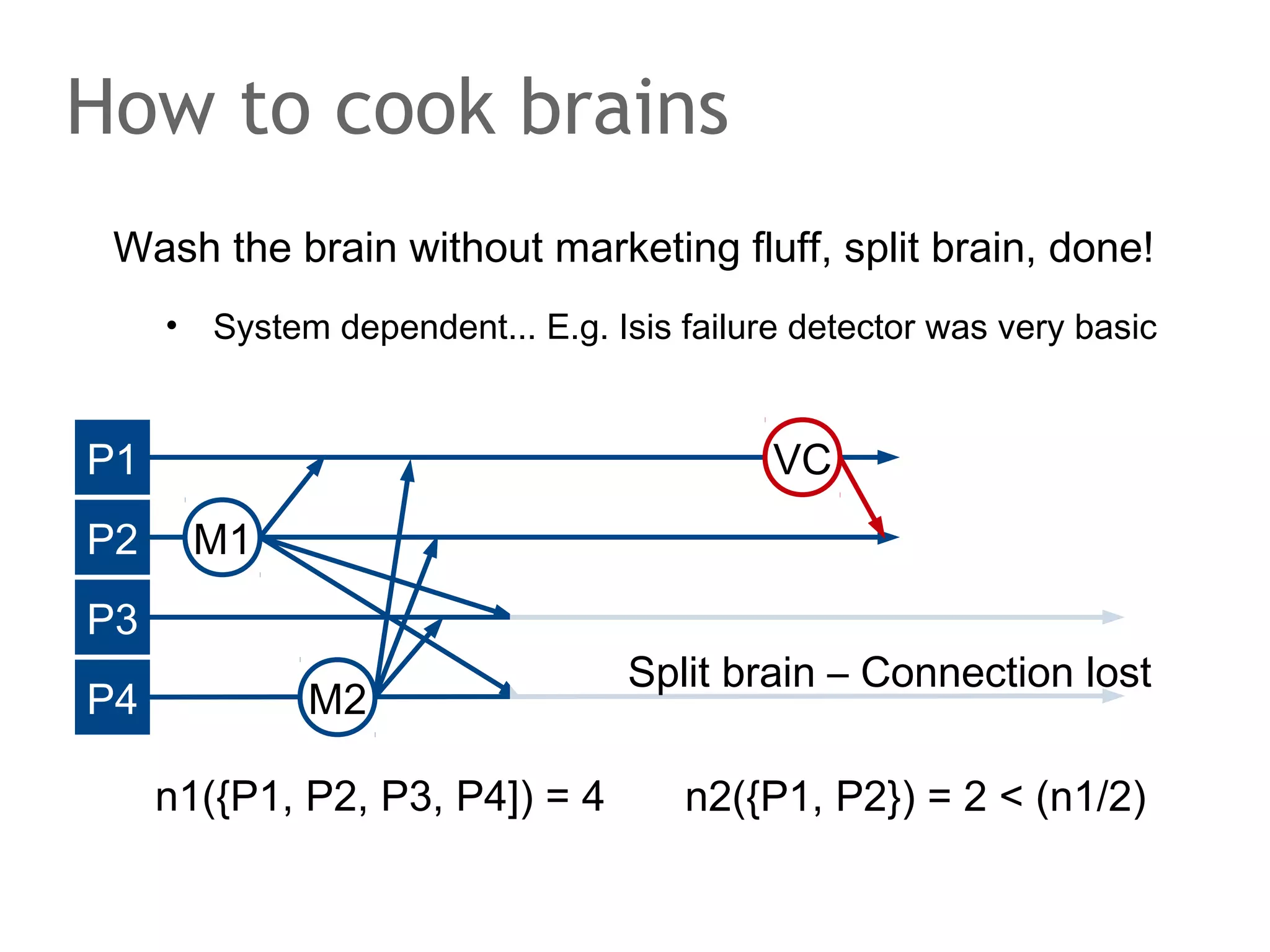
![How to cook brains
Wash the brain without marketing fluff, split brain, done!
•
System dependent... E.g. Isis failure detector was very basic
P1
P2
VC
M1
P3
P4
M2
n1({P1, P2, P3, P4]) = 4
Split brain – Connection lost
n2({P1, P2}) = 2 < (n1/2)](https://image.slidesharecdn.com/scalingdatabasestomillionofnodes-131202134855-phpapp01/75/Data-massage-How-databases-have-been-scaled-from-one-to-one-million-nodes-256-2048.jpg)

















![Famous words...
[…] In the decase since its introduction, designers and researchers
have used (and sometimes abused) the CAP theorem as a reason to
explore a wide variety of novel distributed systems. The NoSQL
movement also has applied as an argument against
traditional databases […] The „2 of 3“ formulation was always
misleading because it tended to oversimplify the tensions among
properties. Now such nuances matter. CAP prohibits only a tiny
part of the design space: perfect availability and
consistency in the presence of partitions, which are rare.
[…] Because partitions are rare, CAP should allow perfect
C and A most of the time, but when partitions are present
or perceived, a strategy that detects partitions and
explicitly accounts for them is in order. Thus strategy should
have three steps: detect partitions, enter an explicit partition mode
that can limit some operations, and initiate a recovery process to](https://image.slidesharecdn.com/scalingdatabasestomillionofnodes-131202134855-phpapp01/75/Data-massage-How-databases-have-been-scaled-from-one-to-one-million-nodes-274-2048.jpg)















































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















