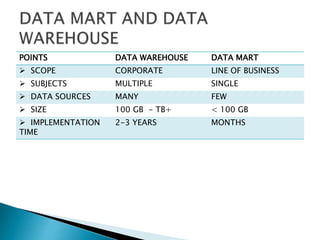
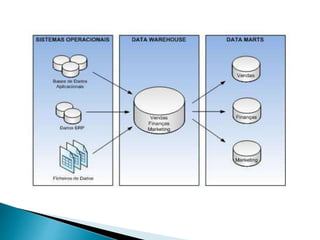
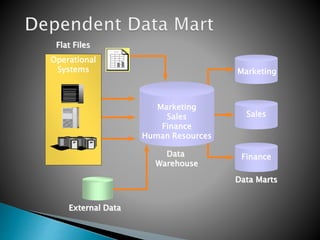
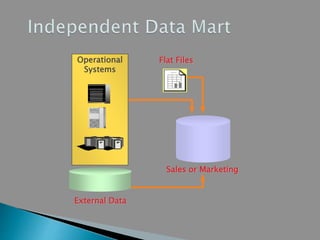
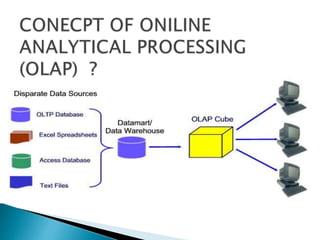
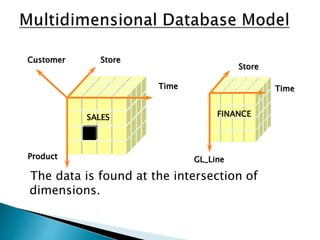
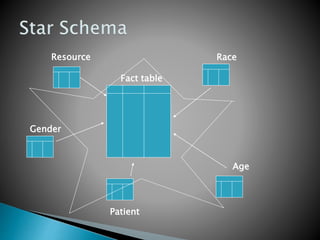
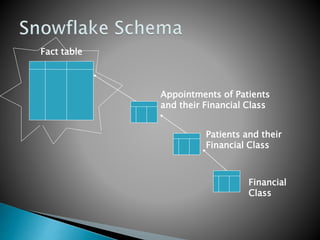
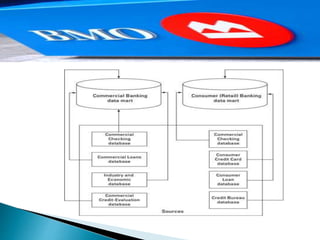
This document discusses data mart approaches to architecture. It defines a data mart as a subset of a data warehouse that supports the requirements of a particular department. It notes that data marts are often built and controlled by a single department. The document outlines the key differences between data warehouses and data marts such as scope, subjects covered, data sources, size and implementation time. It also discusses the types of data marts and why organizations implement them to improve response times, decision making and match user views. Dimensional modeling concepts are introduced along with examples from healthcare and banking organizations.