Downloaded 32 times




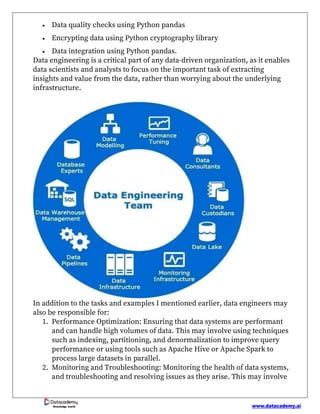




Data engineering involves designing, building, and maintaining systems and infrastructure for storing, processing, and analyzing large datasets. Data engineers collaborate with various teams to ensure systems are scalable, efficient, and secure, while also focusing on data quality and integration. Becoming a data engineer requires knowledge of programming, data storage solutions, big data technologies, and continuous skill enhancement in a rapidly evolving field.



















































































