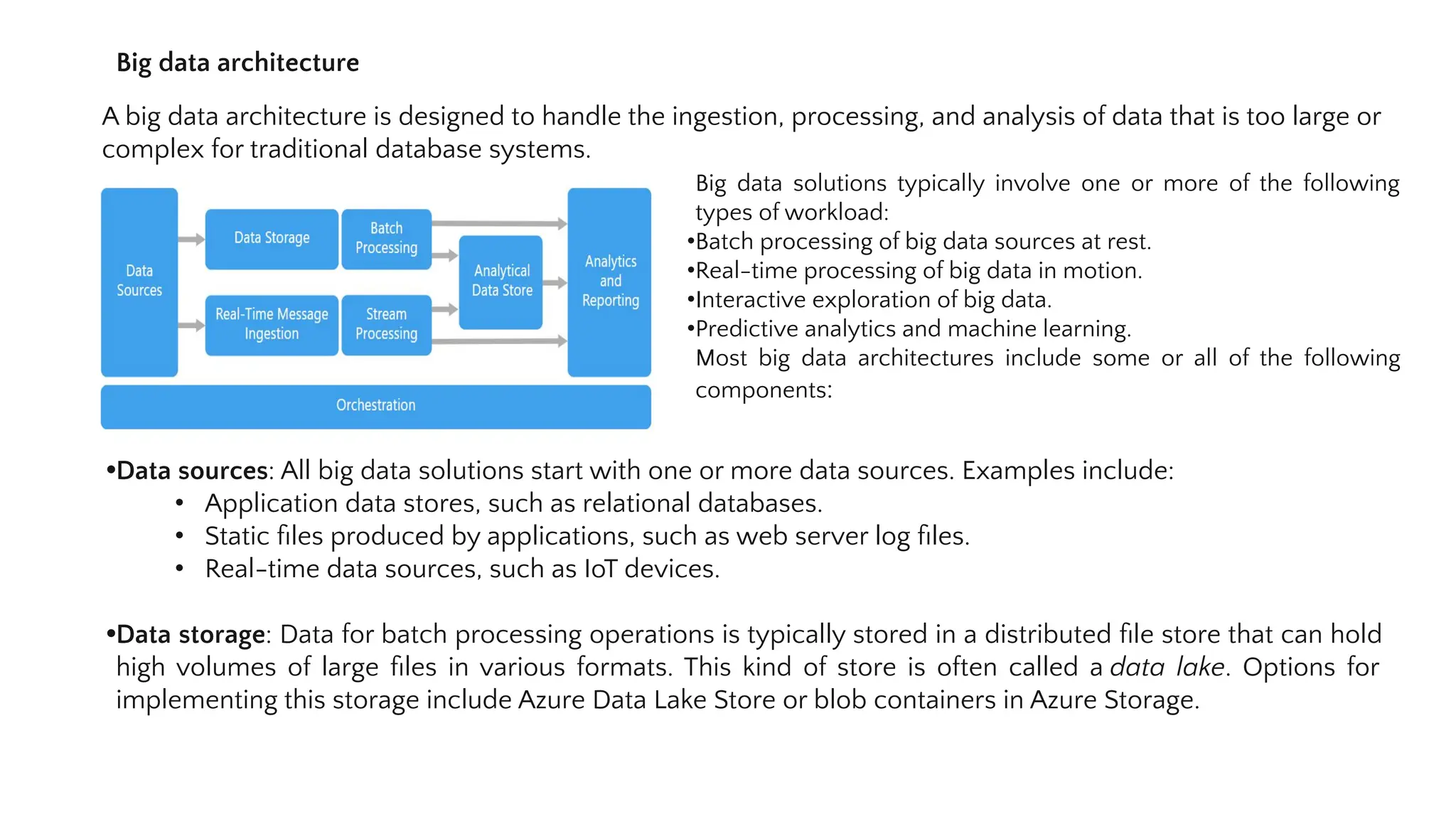
A big data architecture handles large and complex data through batch processing, real-time processing, interactive exploration, and predictive analytics. It includes data sources, storage, batch and stream processing, an analytical data store, and analysis/reporting tools. Orchestration tools automate workflows that transform data between components. Consider this architecture for large volumes of data, real-time data streams, and machine learning/AI applications. It provides scalability, performance, and integration with existing solutions, though complexity, security, and specialized skills are challenges.





























![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)

























