Download to read offline








![8
S
I
L
I
C
O
N
USES OF DATA
COMPRESSION
More and more data is being stored electronically. DigitalMore and more data is being stored electronically. Digital
video libraries, for example, contain vast amounts of data,video libraries, for example, contain vast amounts of data,
and compression allows cost-effective storage of the data.and compression allows cost-effective storage of the data.
New technology has allowed the possibility of interactiveNew technology has allowed the possibility of interactive
digital television and the demand is for high-qualitydigital television and the demand is for high-quality
transmissions, a wide selection of programs to choose fromtransmissions, a wide selection of programs to choose from
and inexpensive hardware. But for digital television to be aand inexpensive hardware. But for digital television to be a
success, it must use data compression [Saxton, 1996].success, it must use data compression [Saxton, 1996]. DataData
compression reduces the number of bits required tocompression reduces the number of bits required to
represent or transmit information.represent or transmit information.](https://image.slidesharecdn.com/datacompretion-150218121044-conversion-gate01/85/Data-compretion-8-320.jpg)














![23
S
I
L
I
C
O
N
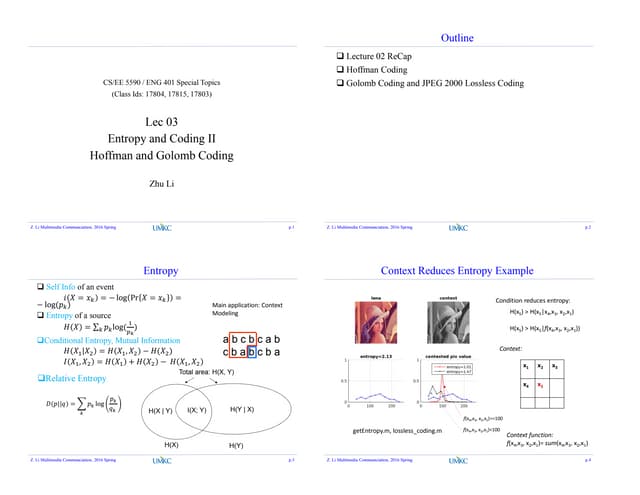
HUFFMAN CODING
ExampleExample
n = 5n = 5,, w[0:4] = [2, 5, 4, 7, 9].w[0:4] = [2, 5, 4, 7, 9].
92 5 4 7 9](https://image.slidesharecdn.com/datacompretion-150218121044-conversion-gate01/85/Data-compretion-23-320.jpg)
![24
S
I
L
I
C
O
N
HUFFMAN CODING
ExampleExample
95 75 7 9
2
n = 5n = 5,, w[0:4] = [2, 5, 4, 7, 9].w[0:4] = [2, 5, 4, 7, 9].
4
6](https://image.slidesharecdn.com/datacompretion-150218121044-conversion-gate01/85/Data-compretion-24-320.jpg)
![25
S
I
L
I
C
O
N
HUFFMAN CODING
EXAMPLEEXAMPLE
5
n = 5n = 5,, w[0:4] = [2, 5, 4, 7, 9].w[0:4] = [2, 5, 4, 7, 9].
2 4
6
11
7 9
16](https://image.slidesharecdn.com/datacompretion-150218121044-conversion-gate01/85/Data-compretion-25-320.jpg)
![26
S
I
L
I
C
O
N
HUFFMAN CODING
ExampleExample
5
n = 5n = 5,, w[0:4] = [2, 5, 4, 7, 9].w[0:4] = [2, 5, 4, 7, 9].
2=0102=010
5=005=00
4=0114=011
7=107=10
9=119=11 2 4
6
11
7 9
16
27
00
0
0
0
1
1
1 1](https://image.slidesharecdn.com/datacompretion-150218121044-conversion-gate01/85/Data-compretion-26-320.jpg)







![34
S
I
L
I
C
O
N
Irreversible Compression
Irreversible CompressionIrreversible Compression is based on the assumptionis based on the assumption
that some information can be sacrificed. [Irreversiblethat some information can be sacrificed. [Irreversible
compression is also calledcompression is also called Entropy ReductionEntropy Reduction].].
Example: Shrinking a raster image from 400-by-400Example: Shrinking a raster image from 400-by-400
pixels to 100-by-100 pixels. The new image containspixels to 100-by-100 pixels. The new image contains
1 pixel for every 16 pixels in the original image.1 pixel for every 16 pixels in the original image.
There is usually no way to determine what theThere is usually no way to determine what the
original pixels were from the one new pixel.original pixels were from the one new pixel.
In data files, irreversible compression is seldom used.In data files, irreversible compression is seldom used.
However, it is used in image and speech processing.However, it is used in image and speech processing.](https://image.slidesharecdn.com/datacompretion-150218121044-conversion-gate01/85/Data-compretion-34-320.jpg)






This document discusses data compression techniques. It begins with an introduction to data compression, explaining that it reduces file sizes by identifying repetitive patterns in data. It then discusses some common questions around data compression, its major steps, types including lossless and lossy compression, and some examples like Huffman coding and LZ-77 encoding. The document provides details on these techniques through examples and diagrams.