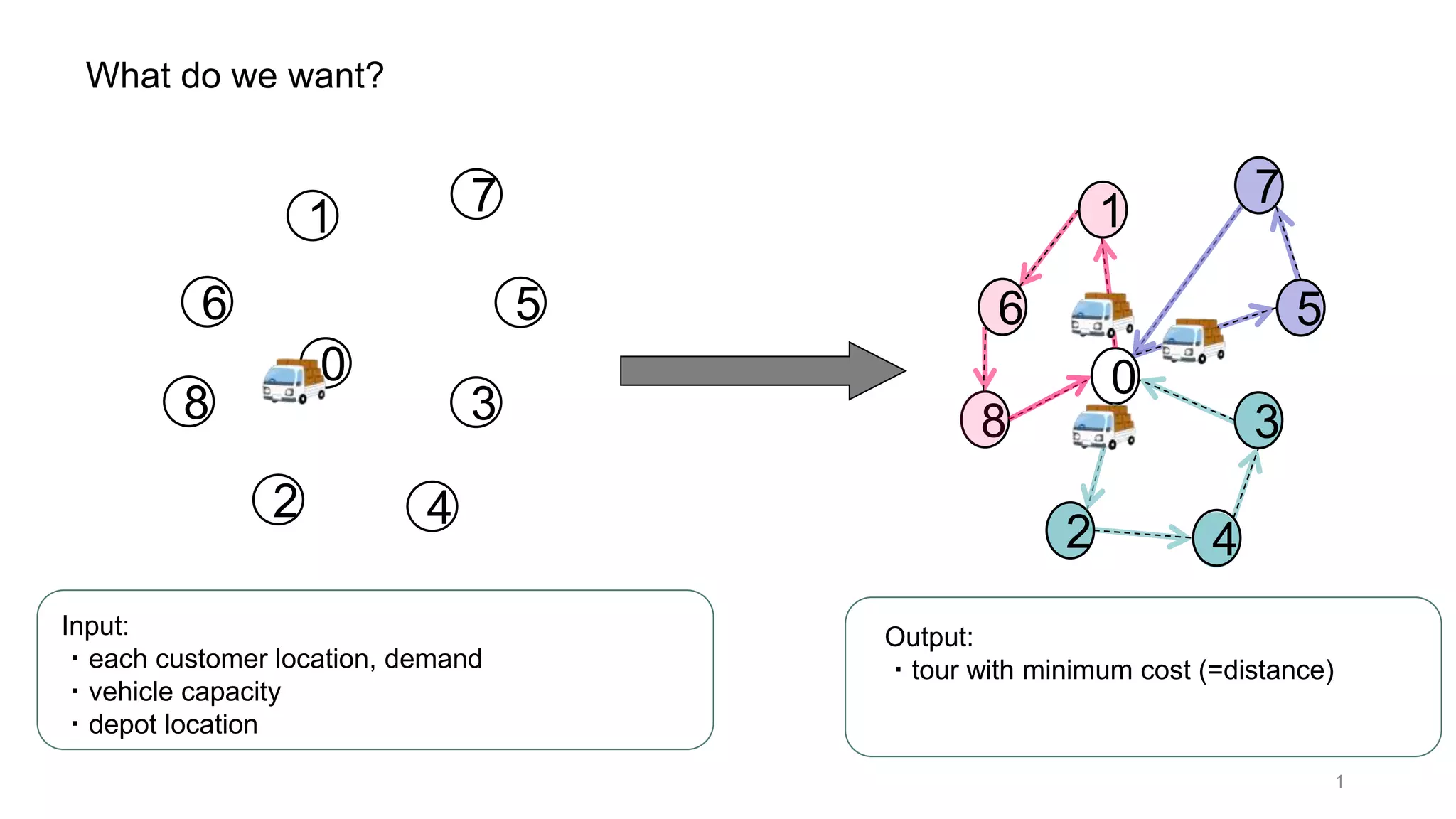
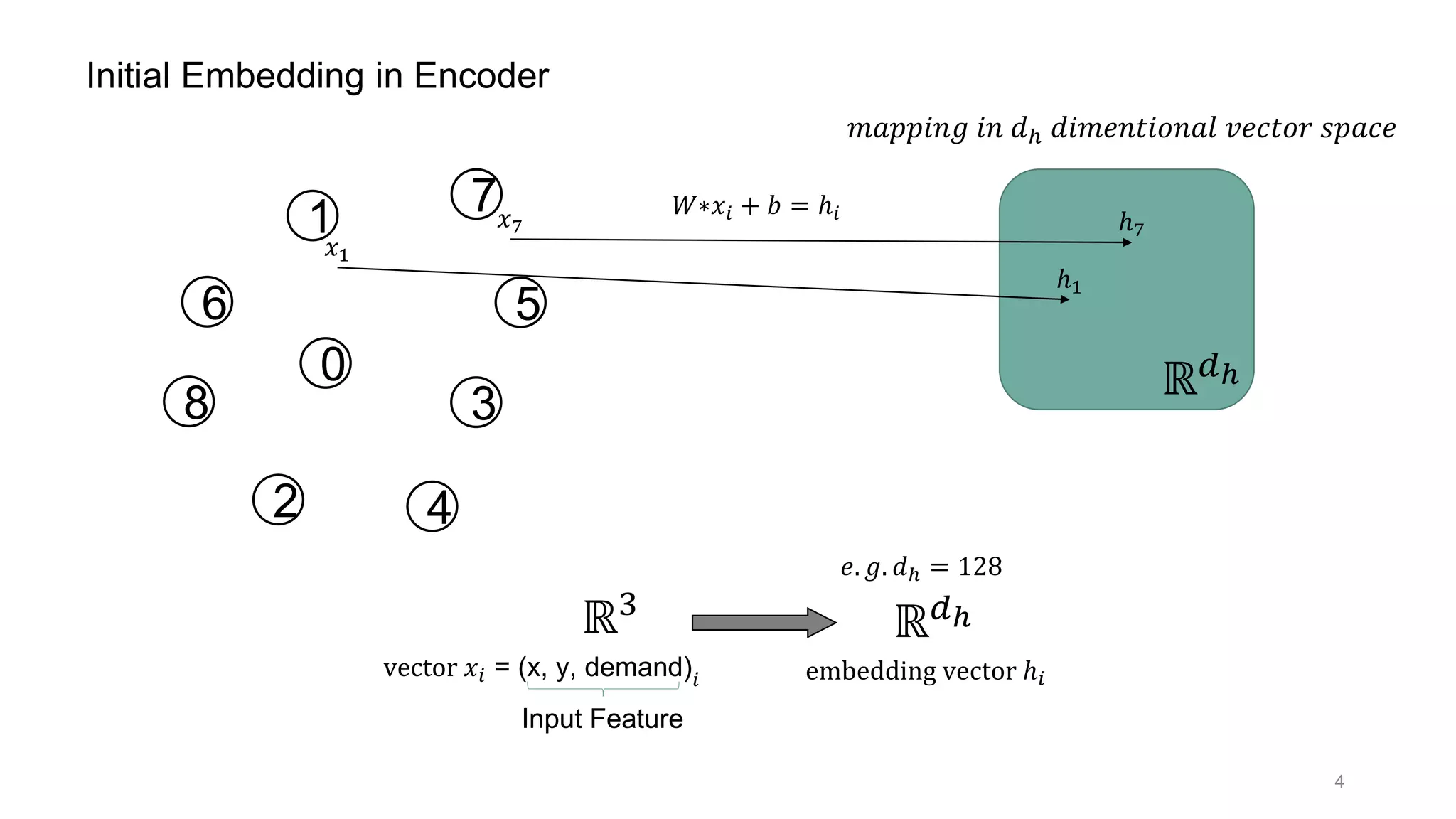
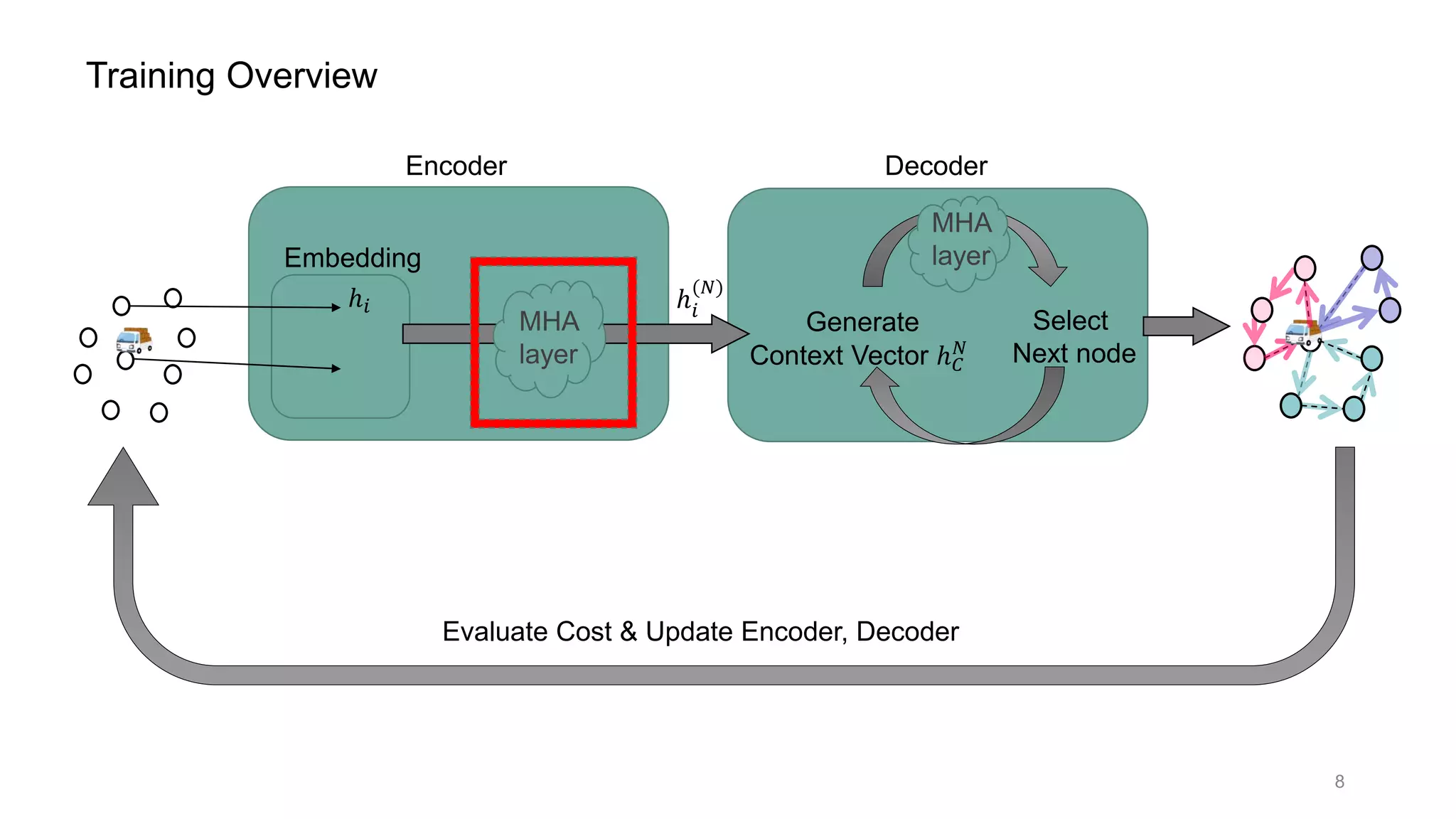
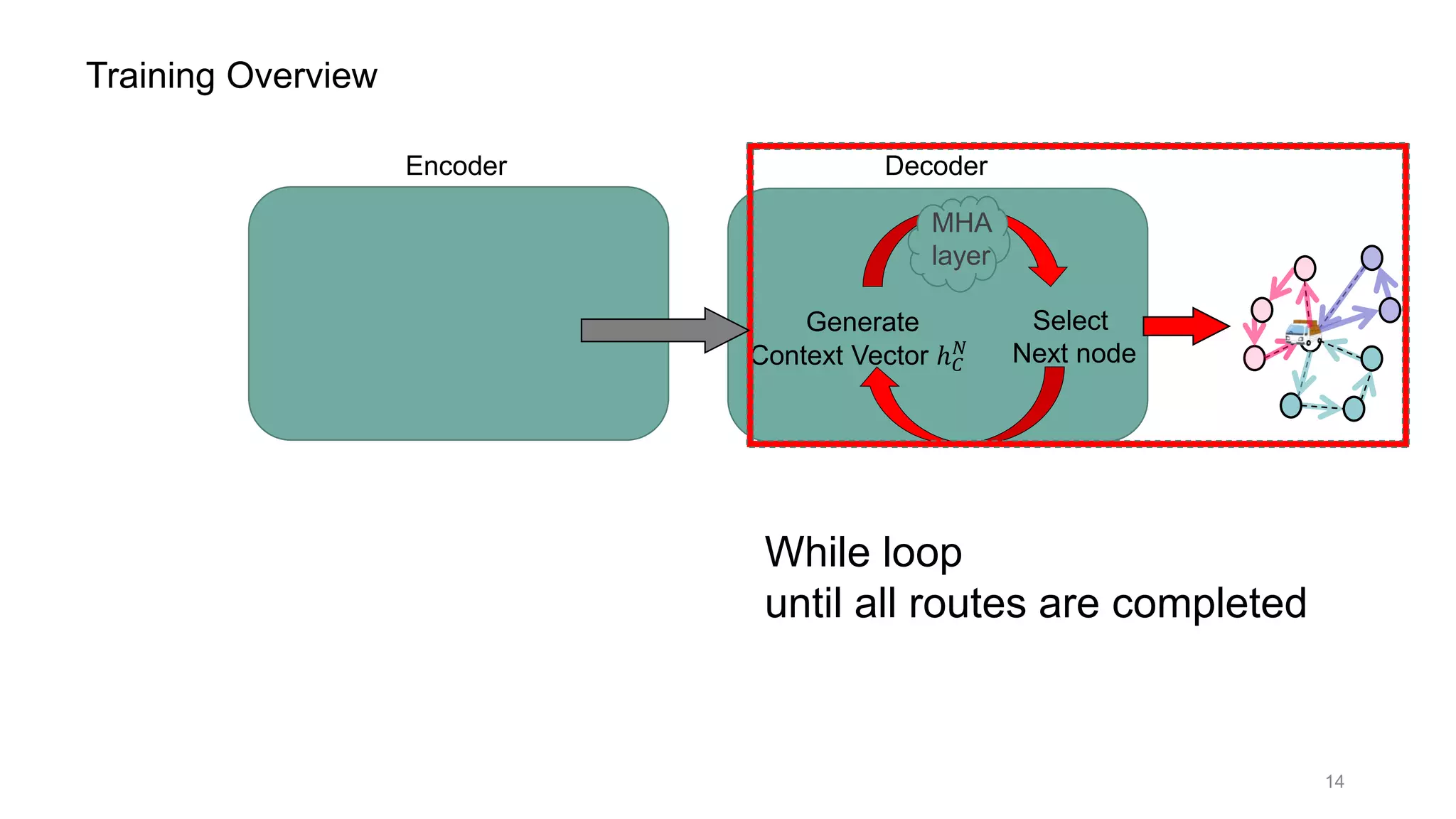
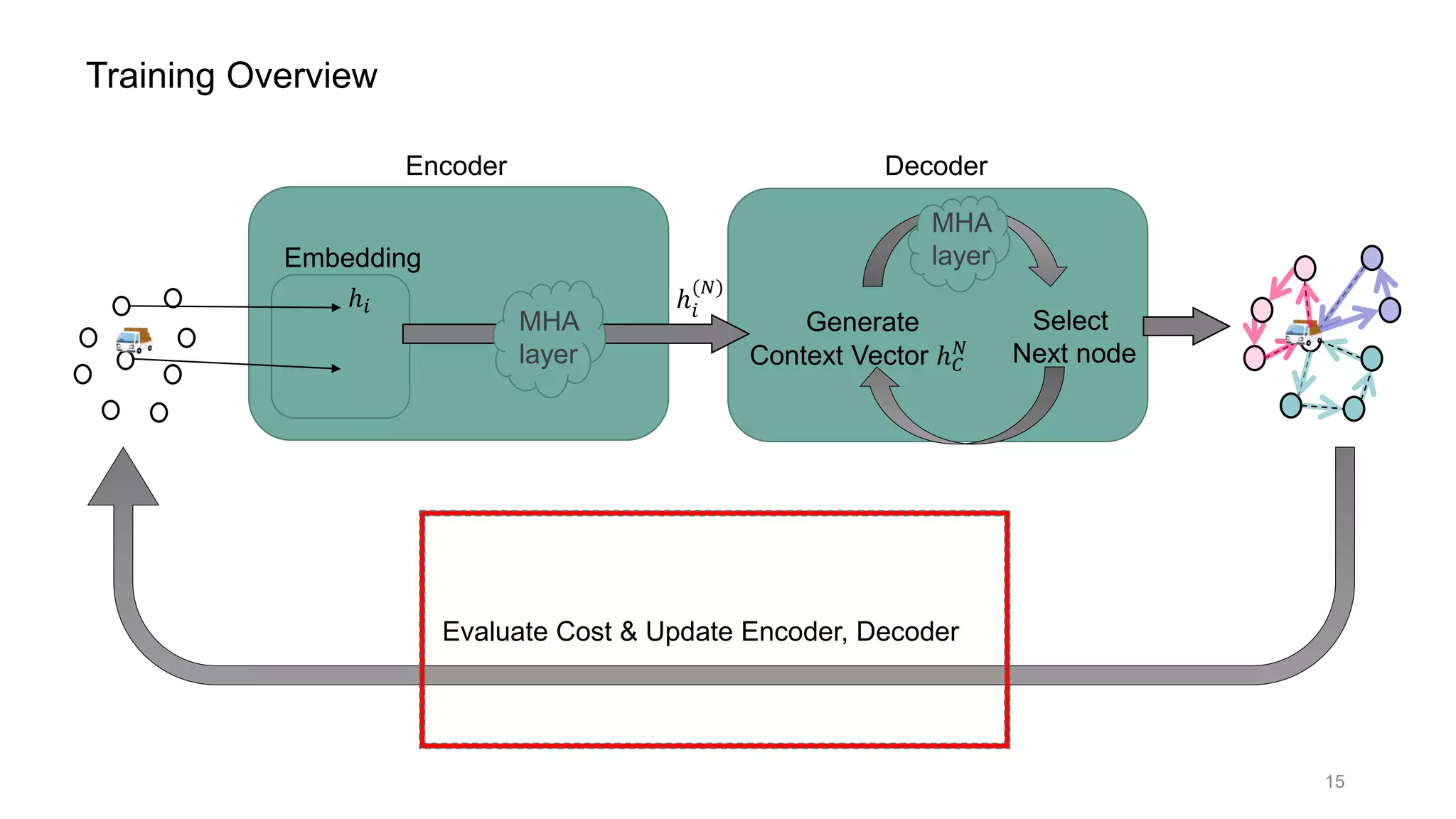
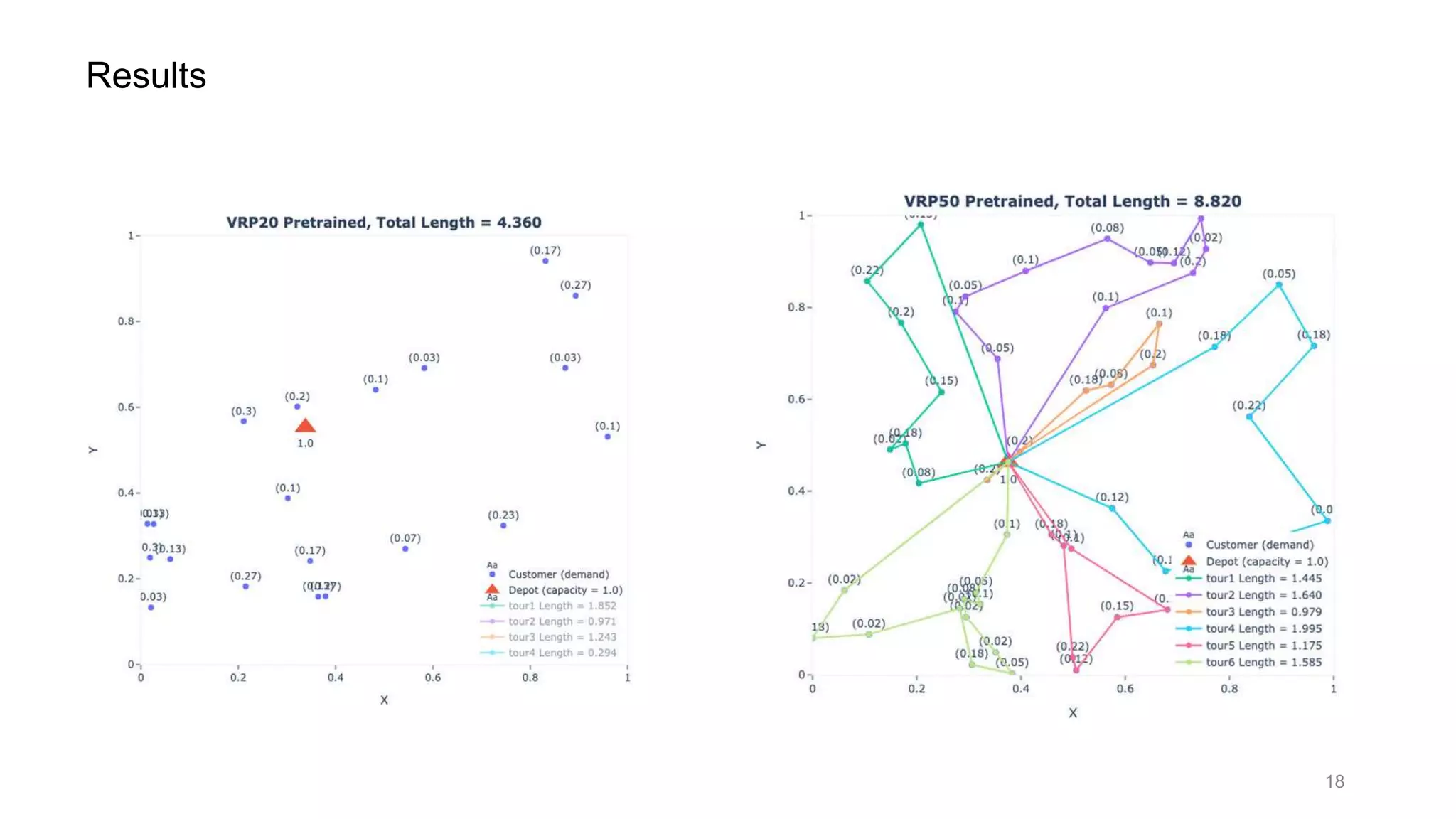
This document discusses using a multi-head attention mechanism to solve vehicle routing problems. It proposes an encoder-decoder model where customer locations are embedded in vectors and passed through an encoder with multi-head attention layers. A decoder then selects the next node in a route using a context vector containing embedding and capacity information, with the goal of minimizing total route distance. The model is trained using a policy gradient method to approximate the gradient and update the encoder and decoder.

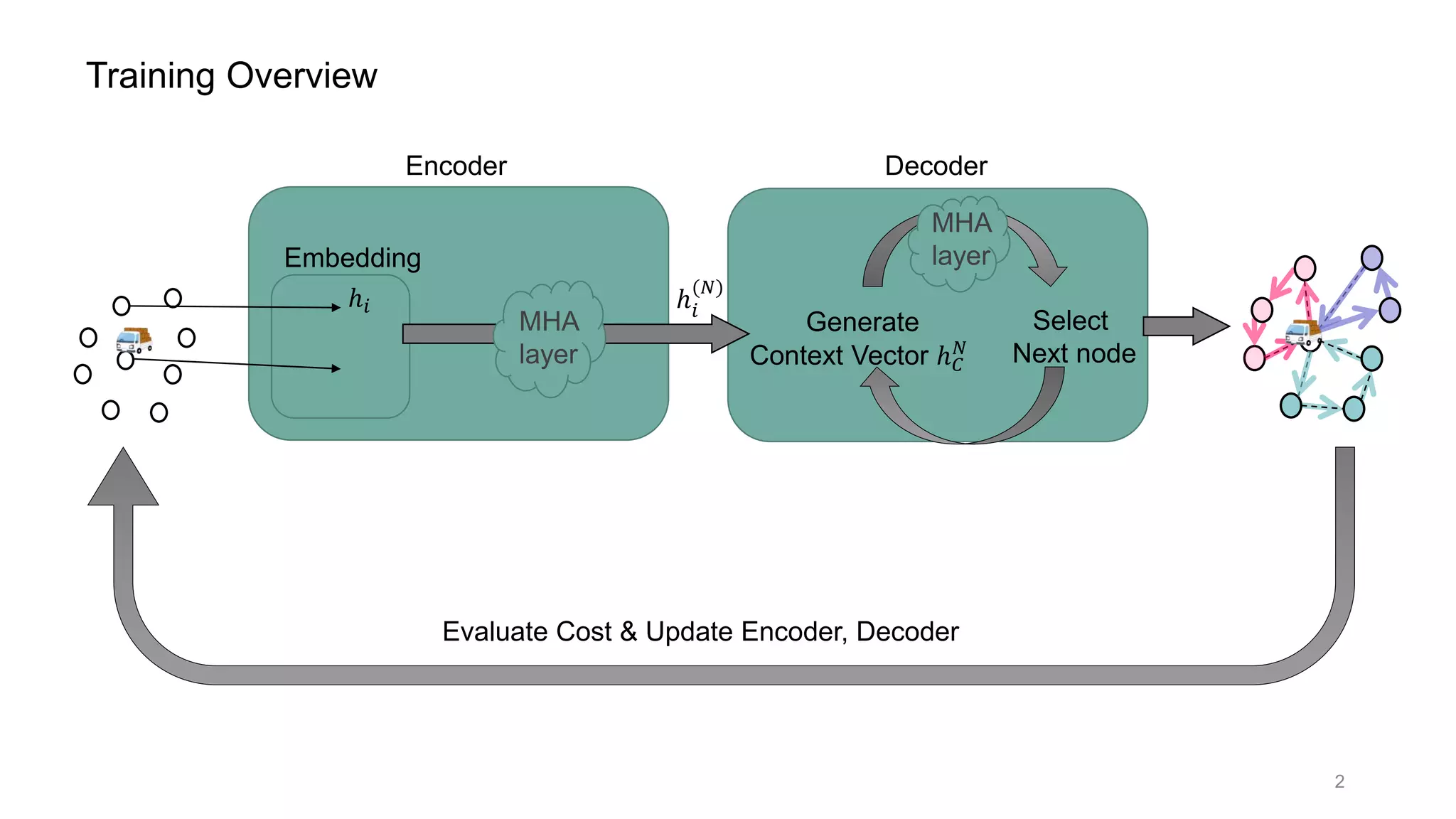
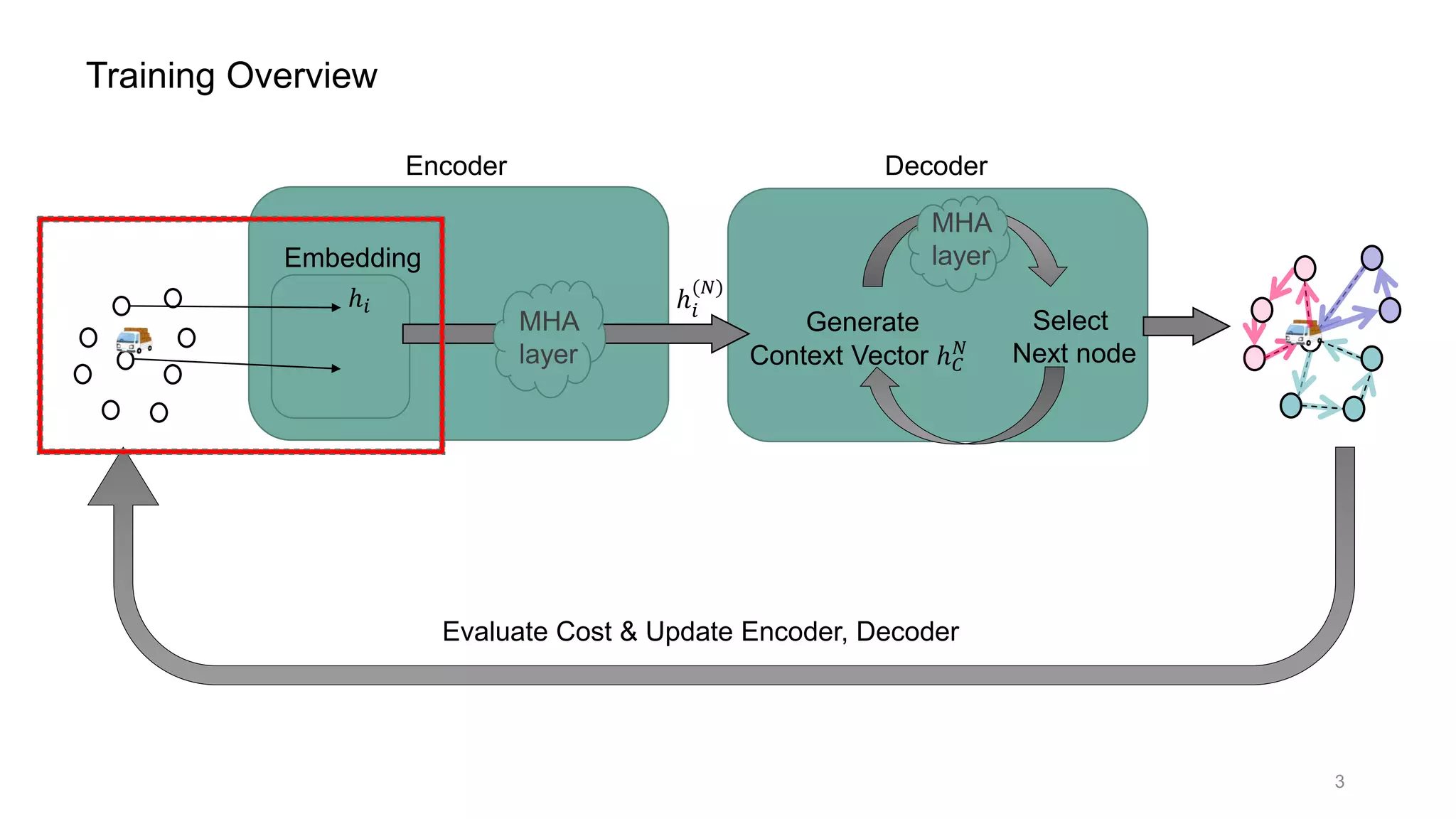
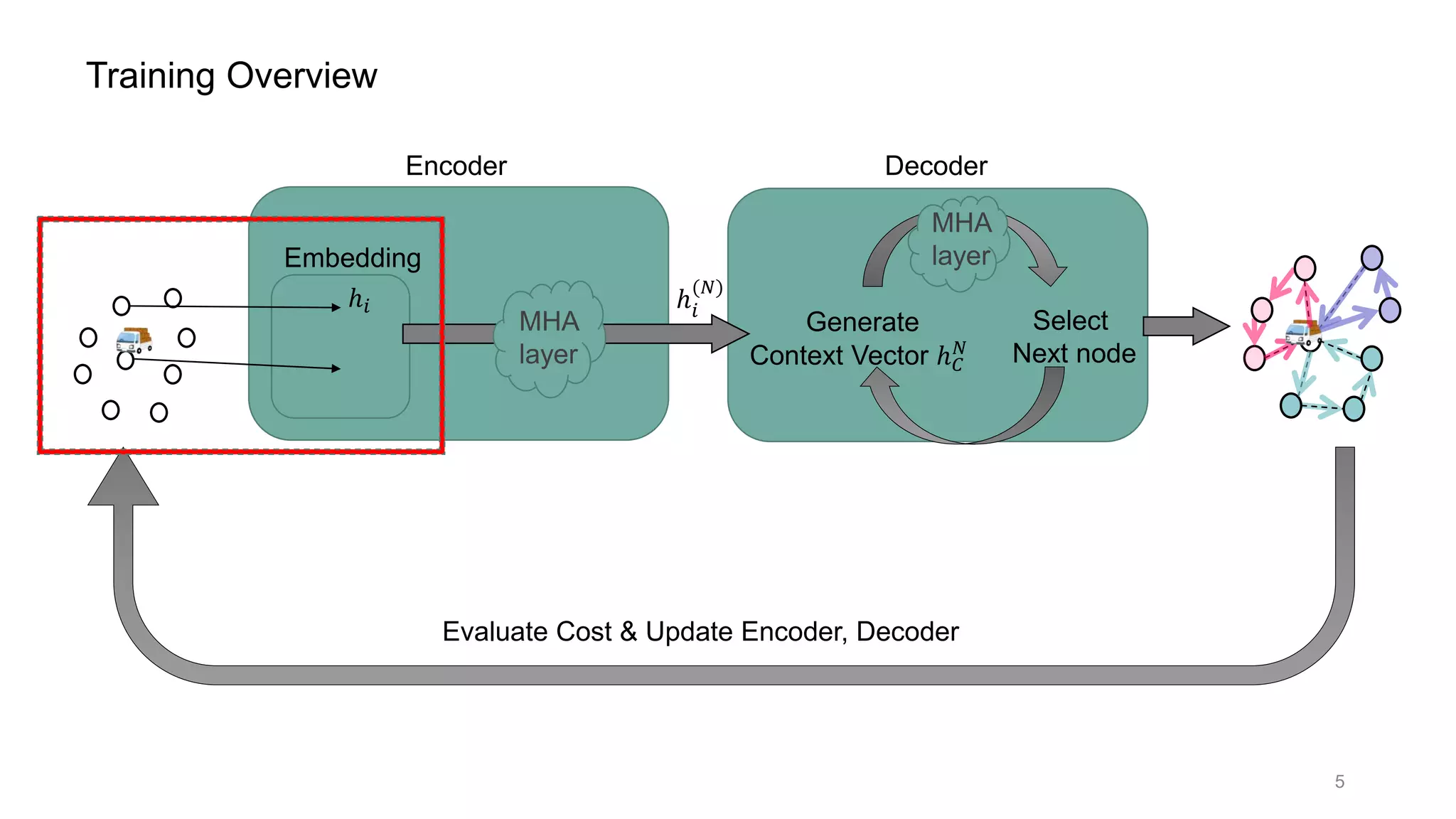
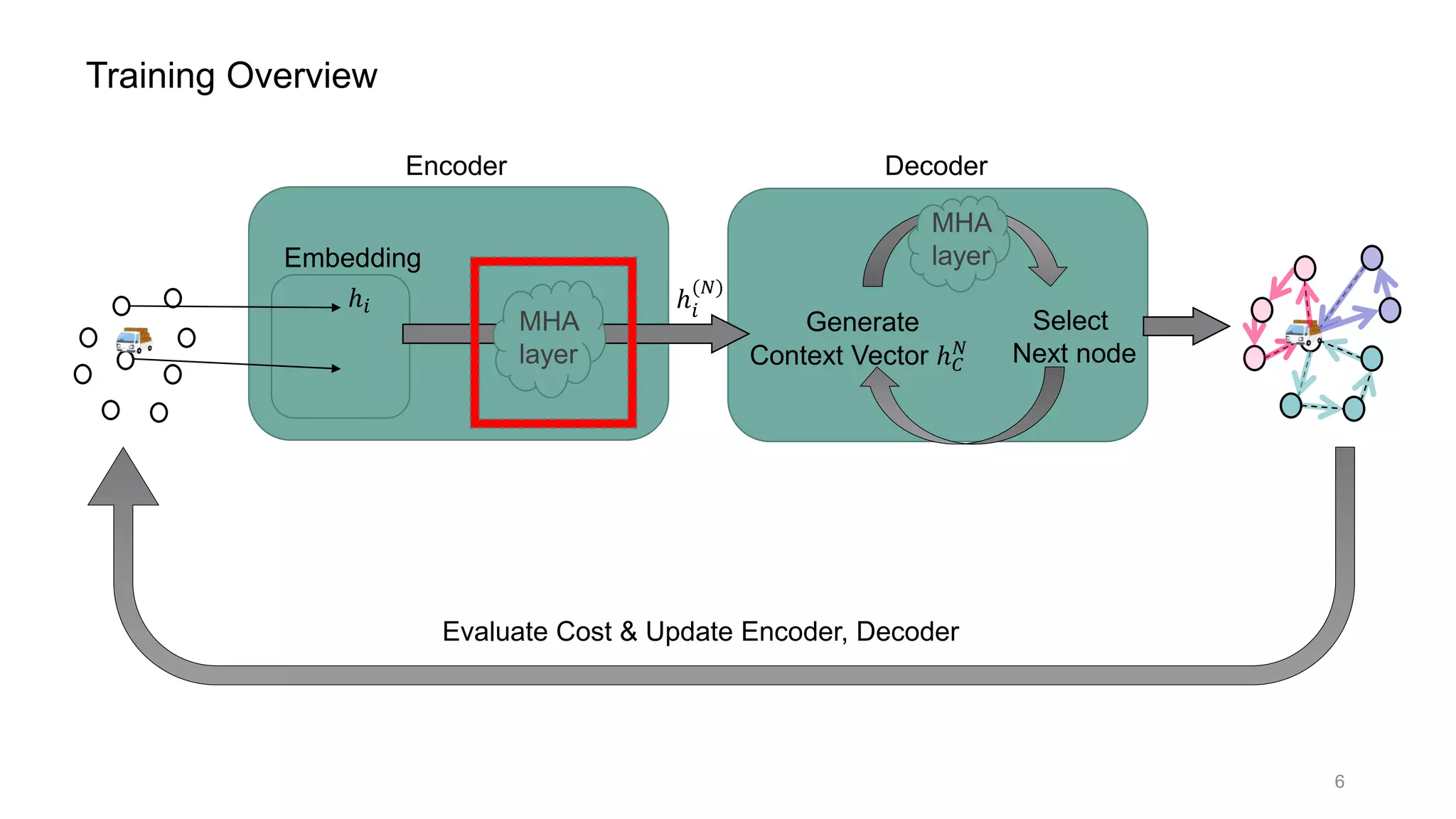
![Multi-Head Attention layer (= MHA layer) [2]
7](https://image.slidesharecdn.com/presenvrp-200731125803/75/CVRP-solver-with-Multi-Head-Attention-8-2048.jpg)
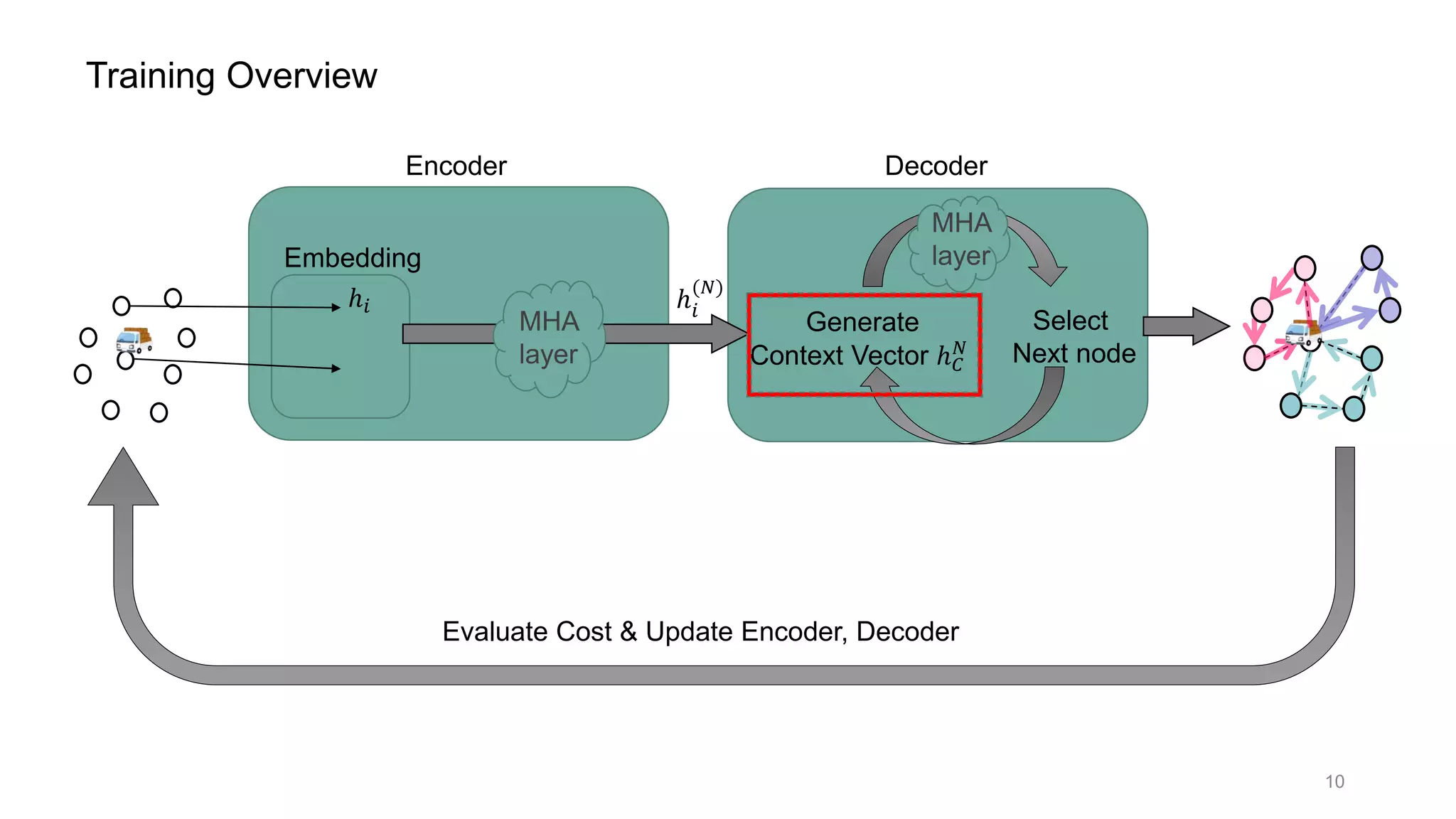
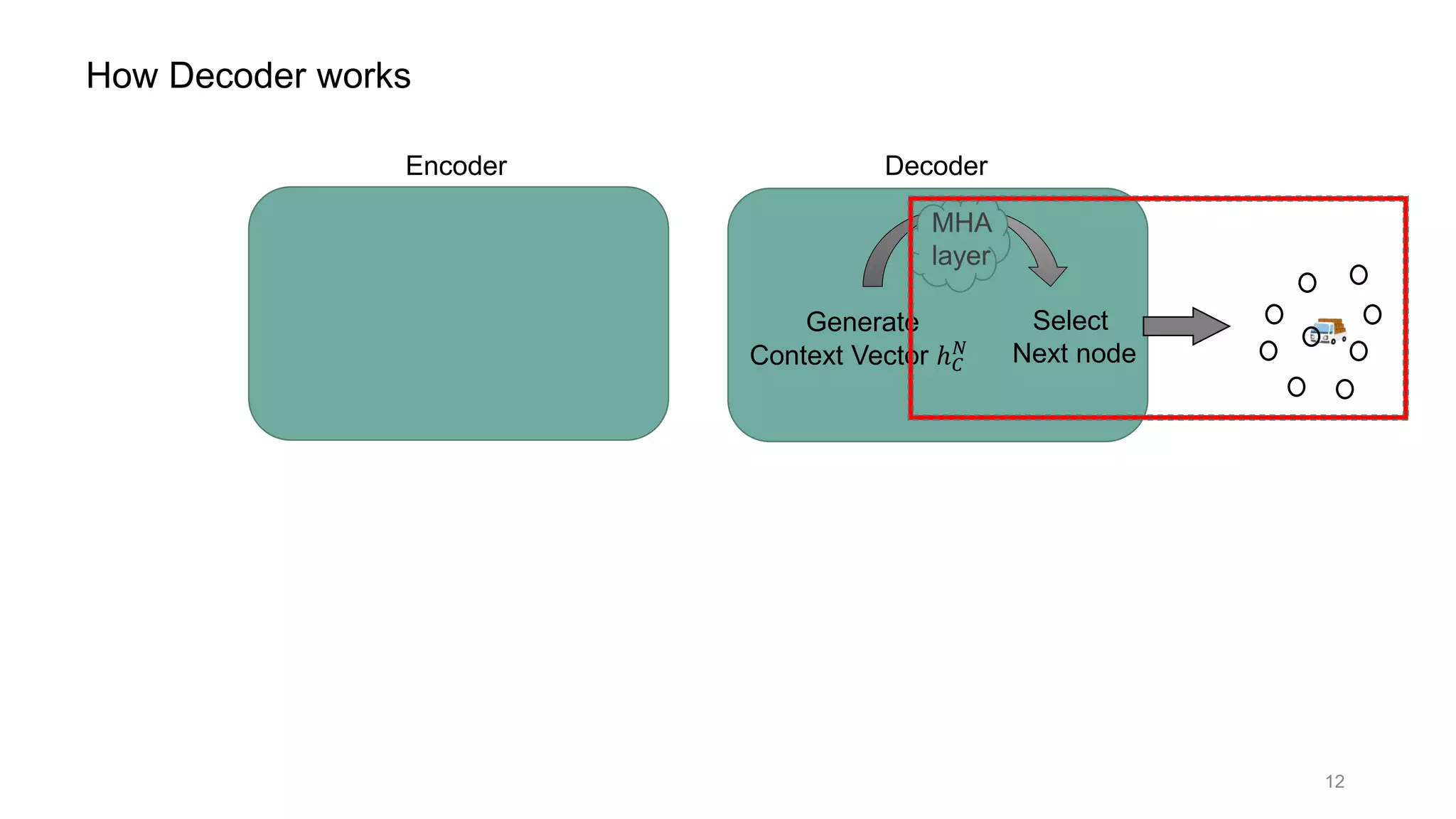
![Encoder Decoder
ℎ 𝑁
Select
Next node
Generate
Context Vector ℎ 𝐶
𝑁
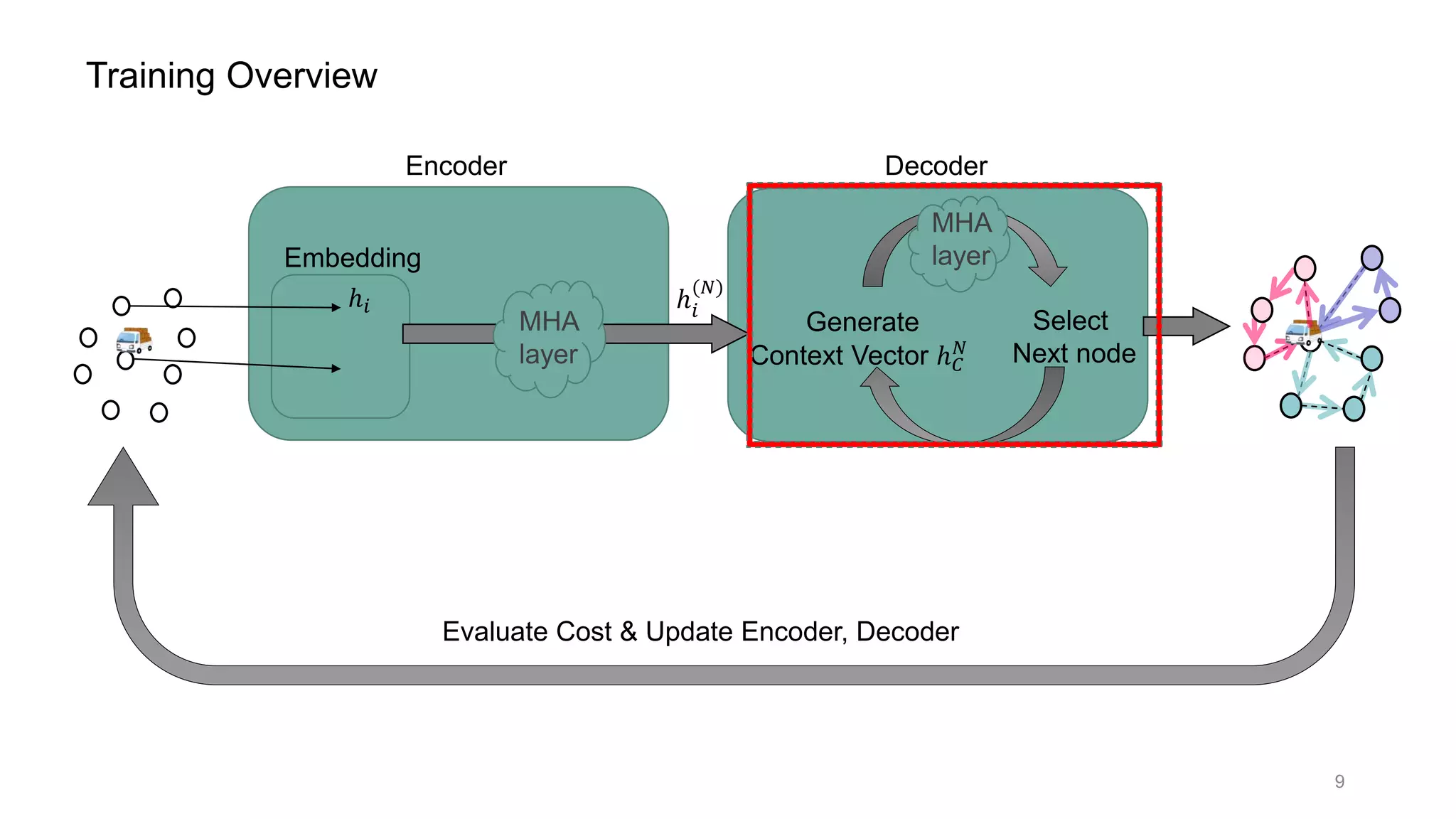
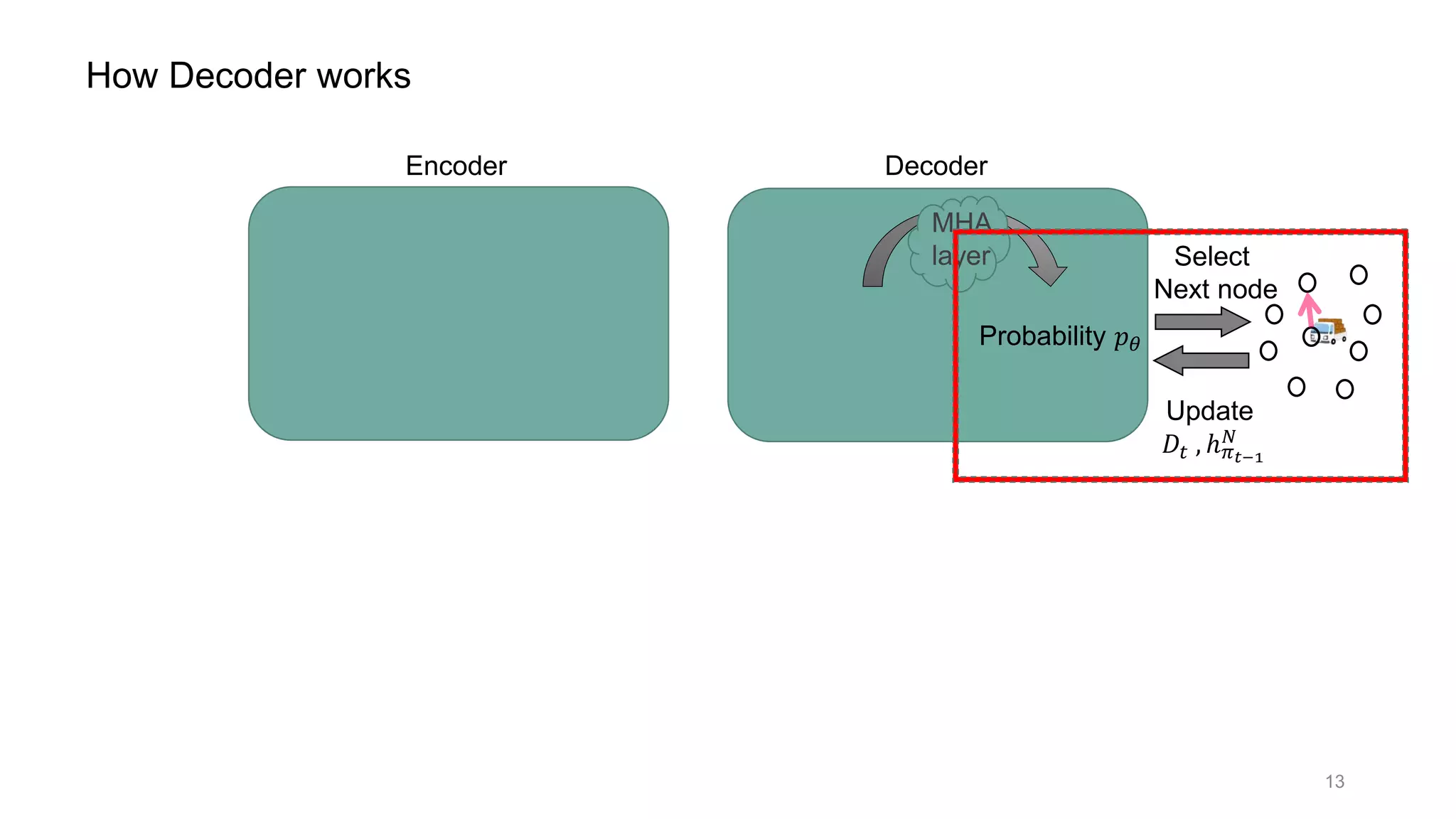
How Decoder works
Context vector ℎ 𝐶
𝑁
: contains state information;
ℎ 𝐶
𝑁
= [ℎ 𝑁
, ℎ 𝜋 𝑡−1
𝑁
, 𝐷𝑡]
ℎ 𝑁
: graph embedding( = output of Encoder)
ℎ 𝜋 𝑡−1
𝑁 : last visited node embedding
𝐷𝑡 : remaining vehicle capacity
11](https://image.slidesharecdn.com/presenvrp-200731125803/75/CVRP-solver-with-Multi-Head-Attention-12-2048.jpg)
![𝑔𝑟𝑎𝑑𝑖𝑒𝑛𝑡 ∇ 𝜃 𝐽 𝜃 s ≅ E[ 𝐿 𝜋 s − b s ∙ ∇ 𝜃 𝑙𝑜𝑔𝑝 𝜃 𝜋 s ]
𝑙𝑜𝑔𝑝 = L𝑜𝑔𝑆𝑜𝑓𝑡𝑚𝑎𝑥 = log
exp 𝑥𝑖
exp 𝑥𝑖
= 𝑖𝑛 𝑟𝑎𝑛𝑔𝑒 −𝐼𝑛𝑓, 0
REINFORCE(Williams, 1992), policy gradient
𝐿 𝜋 s : length of path
𝜋: path (index permutation)
𝑠: graph
b s : baseline
∇ 𝜃: gradient by 𝜃
𝑝 𝜃: probability
𝑚𝑖𝑛𝑖𝑚𝑖𝑧𝑒 𝐿𝑜𝑠𝑠 𝐹𝑢𝑛𝑐𝑡𝑖𝑜𝑛 𝐽 𝜃 s = 𝐸[𝐿 𝜋 s ]
𝑙𝑜𝑔𝑝 𝜃 𝜋 s = log(
𝑖=1
𝑛
𝑝 𝜋 𝑖 𝜋 < 𝑖 , 𝑠)) =
𝑖=1
𝑛
log(𝑝 𝜋 𝑖 𝜋 < 𝑖 , 𝑠)), 𝑛𝑜𝑑𝑒𝑠 𝑖 ∈ 0, 1, … , 𝑛
Approximation of gradient using REINFORCE
∇ 𝜃 𝐽 𝜃 s → 0
16](https://image.slidesharecdn.com/presenvrp-200731125803/75/CVRP-solver-with-Multi-Head-Attention-17-2048.jpg)
![𝑔𝑟𝑎𝑑𝑖𝑒𝑛𝑡 ∇ 𝜃 𝐽 𝜃 s ≅ E[ 𝐿 𝜋 s − b s ∙ ∇ 𝜃 𝑙𝑜𝑔𝑝 𝜃 𝜋 s ]
𝑙𝑜𝑔𝑝 = L𝑜𝑔𝑆𝑜𝑓𝑡𝑚𝑎𝑥 = log
exp 𝑥𝑖
exp 𝑥𝑖
= 𝑖𝑛 𝑟𝑎𝑛𝑔𝑒 −𝐼𝑛𝑓, 0
REINFORCE(Williams, 1992), policy gradient
𝐿 𝜋 s : length of path
𝜋: path (index permutation)
𝑠: graph
b s : baseline
∇ 𝜃: gradient by 𝜃
𝑝 𝜃: probability
𝑚𝑖𝑛𝑖𝑚𝑖𝑧𝑒 𝐿𝑜𝑠𝑠 𝐹𝑢𝑛𝑐𝑡𝑖𝑜𝑛 𝐽 𝜃 s = 𝐸[𝐿 𝜋 s ]
𝑙𝑜𝑔𝑝 𝜃 𝜋 s = log(
𝑖=1
𝑛
𝑝 𝜋 𝑖 𝜋 < 𝑖 , 𝑠)) =
𝑖=1
𝑛
log(𝑝 𝜋 𝑖 𝜋 < 𝑖 , 𝑠)), 𝑛𝑜𝑑𝑒𝑠 𝑖 ∈ 0, 1, … , 𝑛
Approximation of gradient using REINFORCE
In order to reduce variance
Update every epoch if the current model perform well
17
∇ 𝜃 𝐽 𝜃 s → 0](https://image.slidesharecdn.com/presenvrp-200731125803/75/CVRP-solver-with-Multi-Head-Attention-18-2048.jpg)
![Reference
Paper
・[1] Attention, Learn to Solve Routing Problems (Wouter Kool et al. 2019)
・[2] Attention is all you need (Vaswani et al. 2017)
Article
・https://qiita.com/ohtaman/items/0c383da89516d03c3ac0 (深層学習で数理最適化問題を解く [前編])
Implementation
・https://github.com/Rintarooo/VRP_MHA (my own TensorFlow 2 Implementation)
・ https://github.com/wouterkool/attention-learn-to-route (Official PyTorch implementation)
・ https://github.com/alexeypustynnikov/AM-VRP
・ https://github.com/d-eremeev/ADM-VRP
8
42
9
3
5
7
6
1
19](https://image.slidesharecdn.com/presenvrp-200731125803/75/CVRP-solver-with-Multi-Head-Attention-20-2048.jpg)






![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)








































