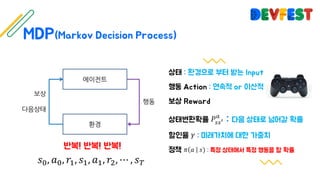
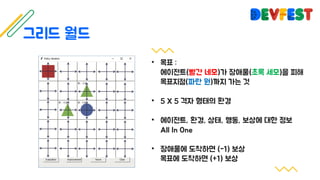
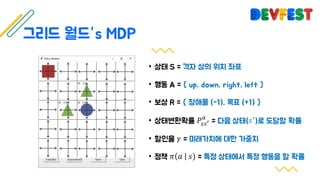
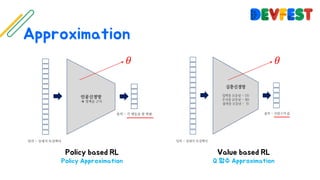
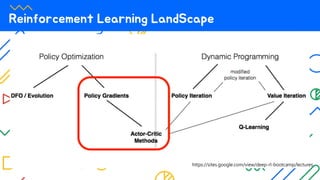
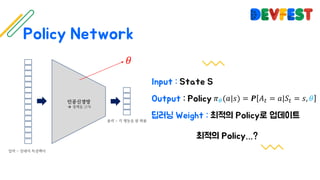
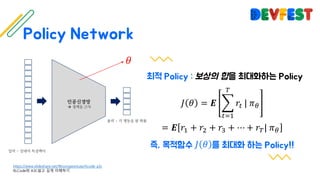
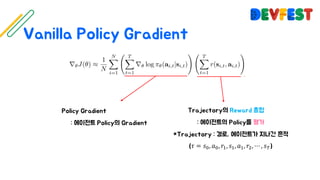
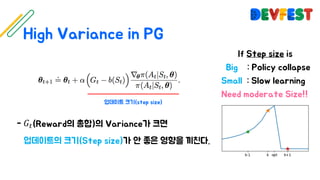
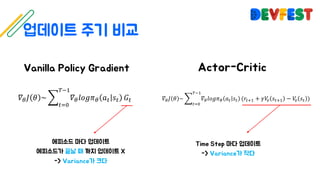
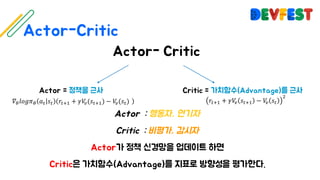
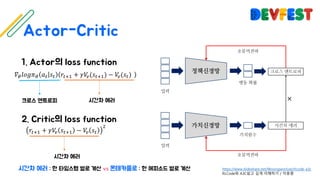
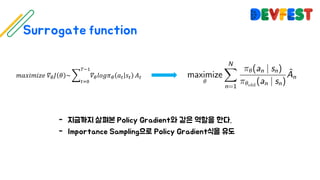
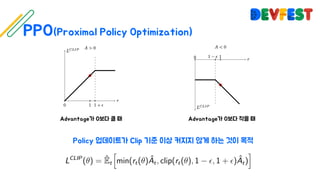
The document appears to be a collection of resources and references related to reinforcement learning, including various tutorials, slides, and methods like A3C. It contains mathematical notations and concepts pertinent to reinforcement learning algorithms. Additionally, it lists URLs for further reading and understanding of the subject.



























































![[DL輪読会]GANとエネルギーベースモデル](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar20200828-210519065921-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Se...](https://cdn.slidesharecdn.com/ss_thumbnails/theneuro-symbolicconceptlearnerinterpretingsceneswordsandsentencesfromnaturalsupervision-190906012005-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] Residual Attention Network for Image Classification](https://cdn.slidesharecdn.com/ss_thumbnails/residualattentionnetworkforimageclassification-170907072057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)](https://cdn.slidesharecdn.com/ss_thumbnails/201807263dv-180728060959-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]representation learning via invariant causal mechanisms](https://cdn.slidesharecdn.com/ss_thumbnails/2021910representationlearningviainvariantcausalmechanisms-210910032836-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)









![集中不等式のすすめ [集中不等式本読み会#1]](https://cdn.slidesharecdn.com/ss_thumbnails/concentrationintro-150128034517-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)




















