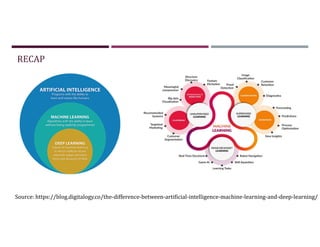
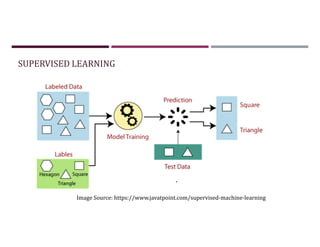
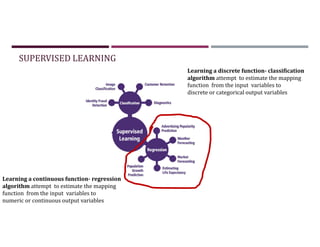
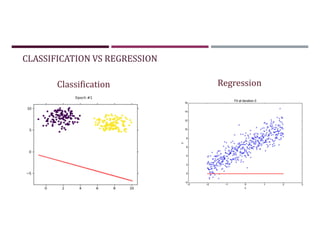
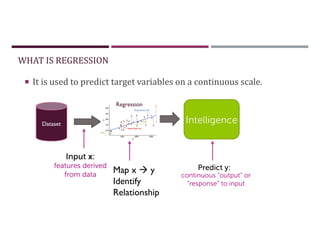
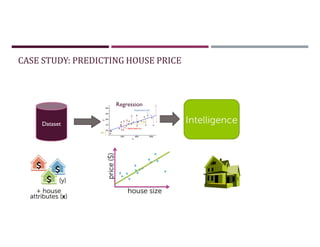
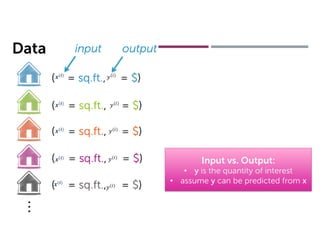
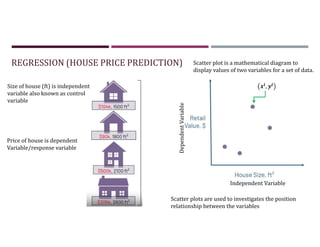
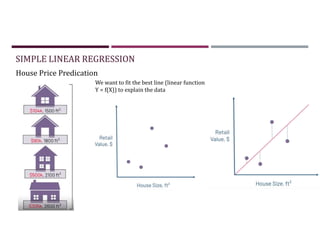
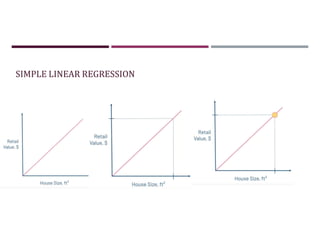
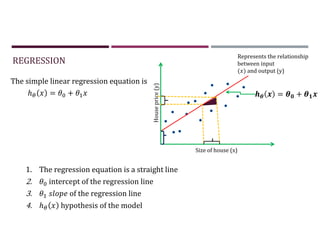
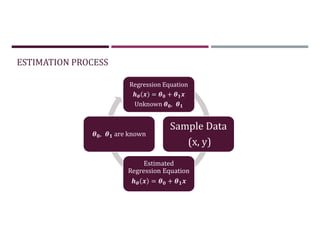
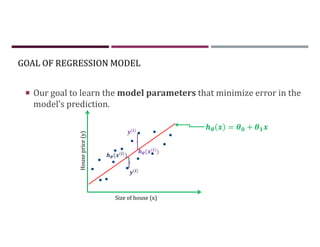
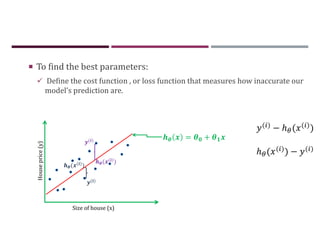
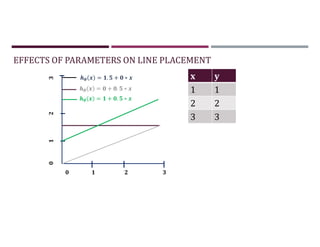
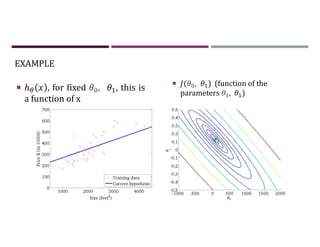
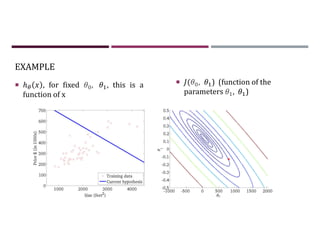
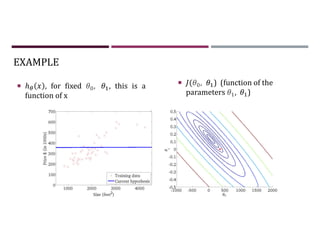
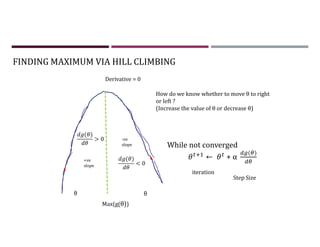
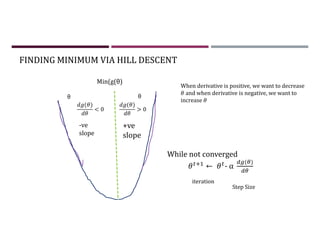
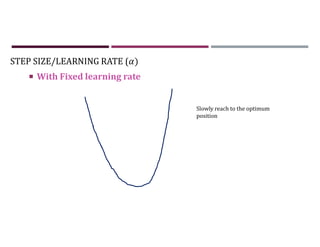
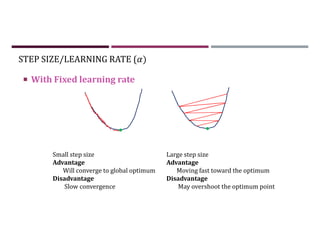
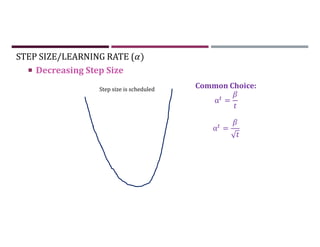
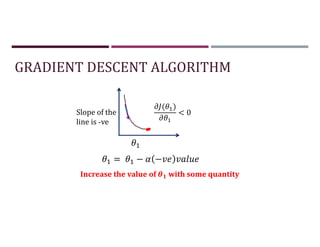
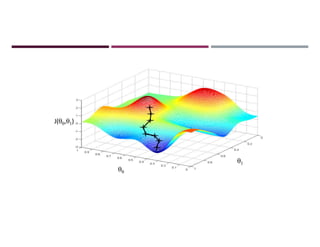
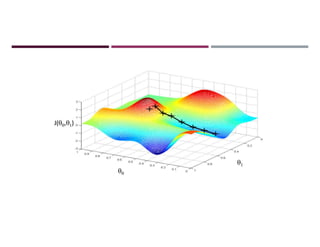
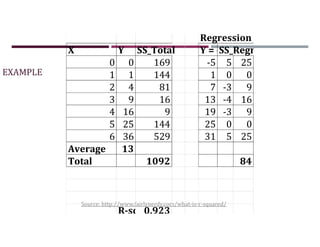
This document discusses supervised learning and regression analysis in machine learning. It defines regression as a technique used to predict continuous target variables by identifying relationships between input features and output variables. Simple linear regression fits a linear function to the data to predict a dependent, or target, variable from an independent variable. Gradient descent is introduced as an optimization algorithm that can be used to fit simple linear regression models by minimizing a cost function.


























![COMPUTE THE GRADIENT
Putting it together
J( , ) = ∑ ( − ℎ ( ( )
))
J( , ) =
∑ [ ( )]
∑ [ ( ( ) )] . ( ( ))](https://image.slidesharecdn.com/1-230511043255-a5097651/85/1-Regression_V1-pdf-54-320.jpg)
![APPROACH 1 : SET GRADIENT = 0
J( , ) =
∑ [ ( )]
∑ [ ( ( ) )] . ( ( ))
Top Term
=
∑
−
∑](https://image.slidesharecdn.com/1-230511043255-a5097651/85/1-Regression_V1-pdf-55-320.jpg)











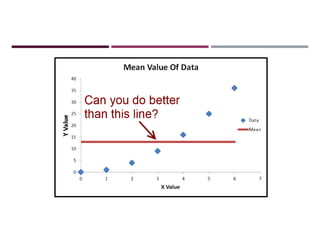

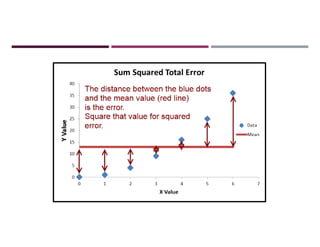

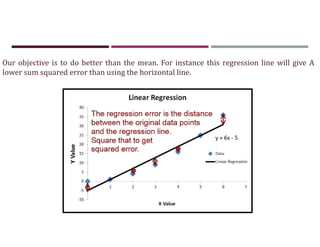
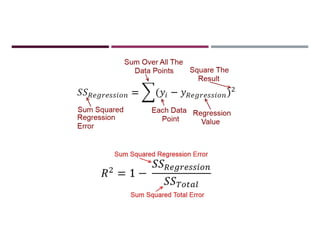


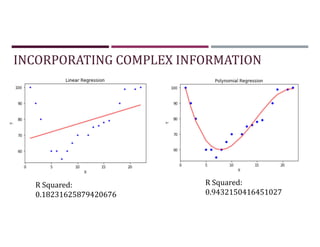
![INCORPORATING COMPLEX INFORMATION
Intercept: 49.67777777777776
Coefficient: [5.01666667]
R Squared: 0.9757431074095347
Intercept: 7.27106067219556
Coefficient: [7.25447403]
R Squared: 0.9503677766997879](https://image.slidesharecdn.com/1-230511043255-a5097651/85/1-Regression_V1-pdf-85-320.jpg)
![MORE COMPLEX FUNCTION OF SINGLE INPUT
Intercept: 7.27106067219556
Coefficient: [7.25447403]
R Squared: 0.9503677766997879
Slope: [0. 4.3072556 0.24072435]
Intercept: 13.026878767297461
R Squared: 0.9608726568678714](https://image.slidesharecdn.com/1-230511043255-a5097651/85/1-Regression_V1-pdf-86-320.jpg)















































