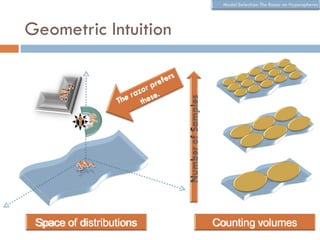
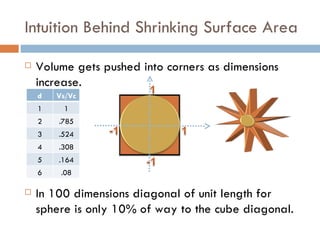
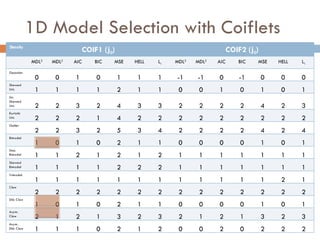
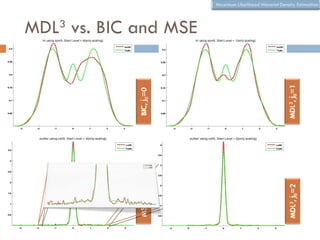
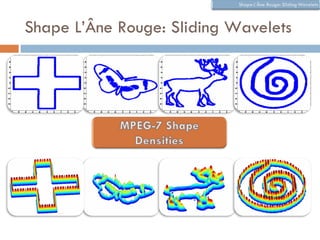
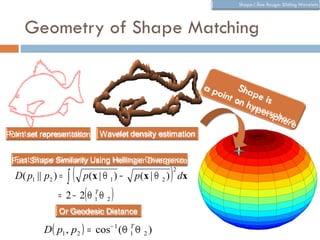
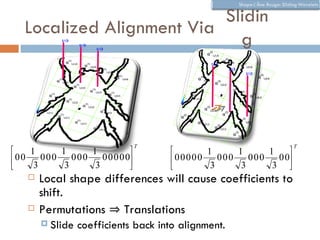
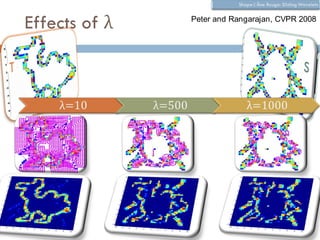
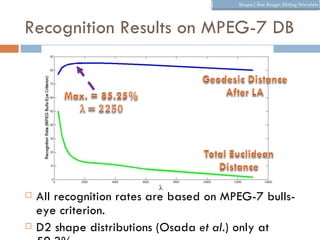
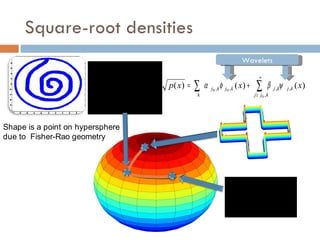
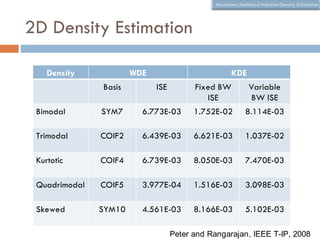
The document discusses using wavelet representations for density estimation and shape analysis. It proposes using a constrained maximum likelihood objective to estimate density coefficients in a multi-resolution wavelet basis. Model selection criteria like MDL, AIC and BIC are compared for selecting the number of resolution levels in the wavelet expansion, with MDL shown to be invariant to the multi-resolution analysis used. The criteria are tested on 1D densities with different shapes, with MDL and MSE performing best in distinguishing the densities.



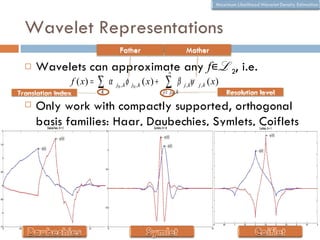


![How Do We Select the Number of
Levels?
In the wavelet expansion of p we need set j0
(starting level) and j1 (ending level)
j 1
p( x) = ∑ k
α j0 , k φ j0 , k ( x) + ∑ β j ,kψ
j > j0 , k
j ,k ( x)
Balasubramanian [32] proposed geometric
approach by analyzing the posterior of a model
class p(M) ∫ p(Θ ) p( E | Θ )dΘ
p(M | E ) =
p( E )
The model selection criterion (razor) is
~
det g ij (Θˆ )
ˆ (Mk =ln( ln p( E | Θˆ ) +det g V Θ M )Θ +
N ( 1
Total volume of manifold
R(M ) = − ln p( E | Θ ) + ) − ) + ln ∫ ln ij ( )d
R ln
2 2π V ˆ (M ) 2 Volume ofg ij (Θˆ )
det distinguishable
Θ
distributions around ML
Scales with Volume of model Ratio of expected Fisher
ML fit parameters and class manifold to empirical Fisher
samples.](https://image.slidesharecdn.com/waveletdensities-110515221800-phpapp01/85/CVPR2010-Advanced-ITinCVPR-in-a-Nutshell-part-7-Future-Trend-9-320.jpg)