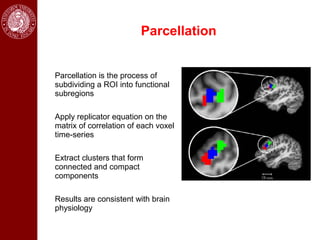
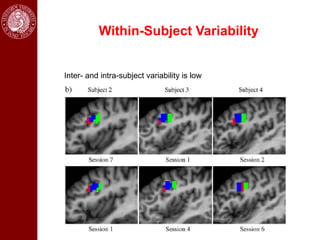
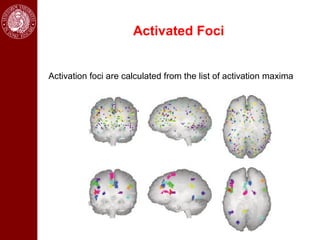
- The document contains a table of contents listing applications of image segmentation, including medical image analysis.
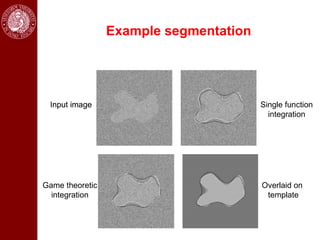
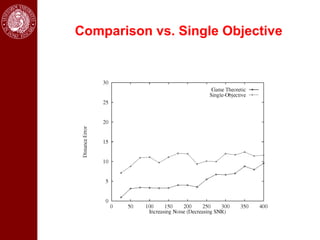
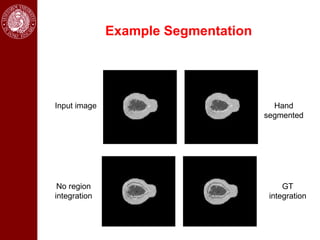
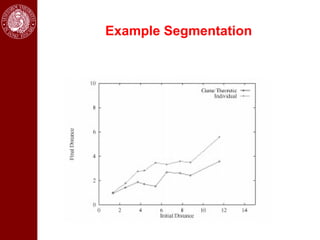
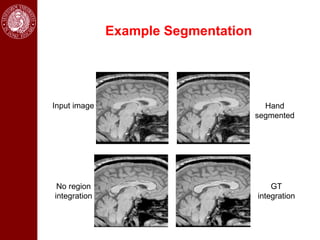
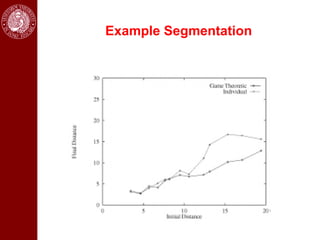
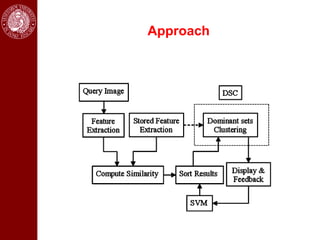
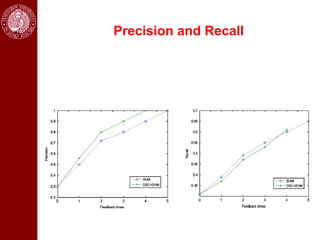
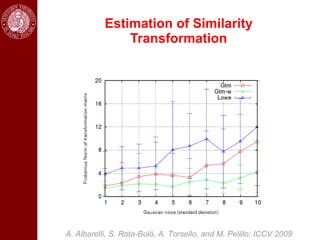
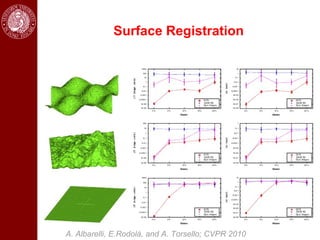
- It then discusses using game theory to integrate region-based and boundary-based image segmentation approaches. Pixels and boundaries are modeled as players in a game, with the goal of maximizing both region and boundary posteriors through limited interaction.
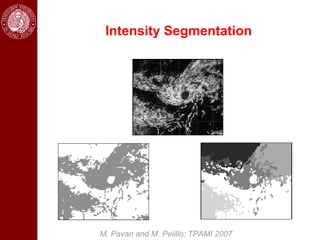
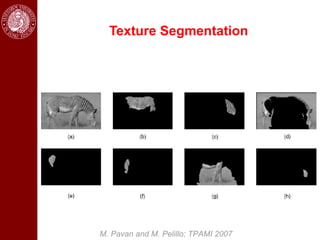
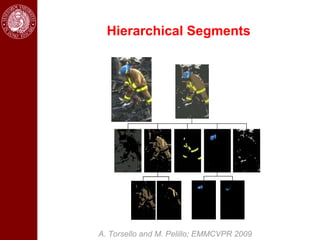
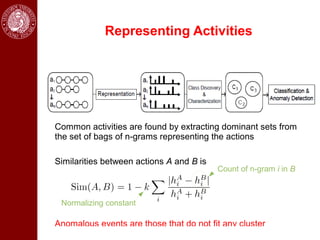
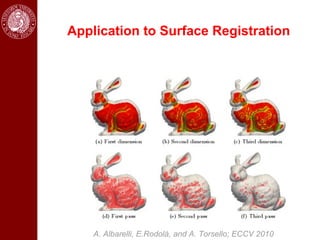
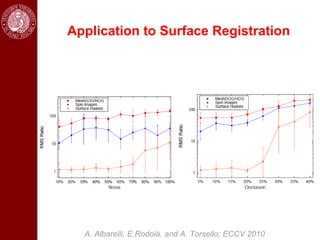
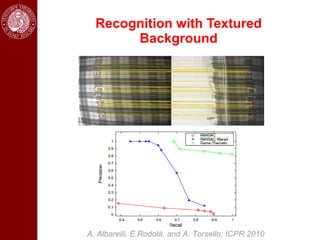
- Dominant sets, a graph-based clustering technique, is also discussed for applications like intensity, color, texture segmentation of images and video. Hierarchical segmentation is achieved by regularizing dominant sets with boundary information.




































































































![[PR12] Generative Models as Distributions of Functions](https://cdn.slidesharecdn.com/ss_thumbnails/pr12generativemodelsasdistributionsoffunctions-jaejunyoo-210411152822-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[ICLR2021 (spotlight)] Benefit of deep learning with non-convex noisy gradien...](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2021-210331133549-thumbnail.jpg?width=640&height=640&fit=bounds)












































































