Download to read offline










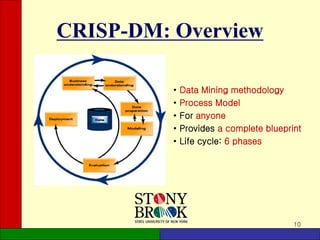

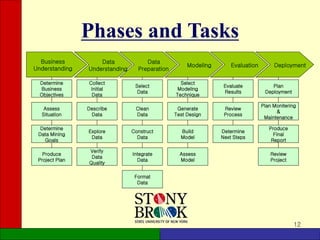






















The document provides an overview of the CRISP-DM (Cross-Industry Standard Process for Data Mining) methodology. It describes CRISP-DM as a standard process for data mining projects that consists of 6 phases: business understanding, data understanding, data preparation, modeling, evaluation, and deployment. Each phase has defined tasks to guide users through a complete data mining process from start to finish. The document outlines the objectives and key activities in each phase to give readers a high-level understanding of the CRISP-DM methodology.




















































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)













![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
