Downloaded 10 times





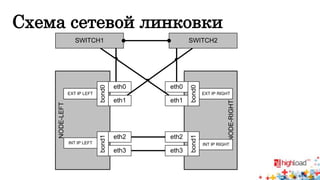
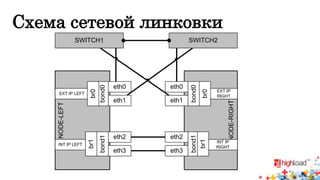

![Конфигурация сетевых интерфейсов (bonding)
/etc/sysconfig/network-scripts/eth[0-1]
DEVICE="eth[0-1]"
BOOTPROTO="static"
HWADDR=“XX:XX:XX:XX:XX:XX"
NM_CONTROLLED="no"
ONBOOT="yes"
MASTER=bond0
SLAVE=yes
TYPE="Ethernet"
/etc/sysconfig/network-scripts/bond0
DEVICE=bond0
BOOTPROTO=none
ONBOOT=yes
IPADDR=EXT IP (LEFT|RIGHT)
NETMASK=X.X.X.X
TYPE=Bonding
USERCRL=no
BONDING_OPTS="mode=1 miimon=100"
/etc/sysconfig/network-scripts/eth[2-3]
DEVICE="eth[2-3]"
BOOTPROTO="static"
HWADDR=“XX:XX:XX:XX:XX:XX"
NM_CONTROLLED="no"
ONBOOT="yes"
MASTER=bond1
SLAVE=yes
MTU=9000
TYPE="Ethernet“
/etc/sysconfig/network-scripts/bond1
DEVICE=bond0
BOOTPROTO=none
ONBOOT=yes
IPADDR=INT IP (LEFT|RIGHT)
NETMASK=255.255.255.252
TYPE=Bonding
USERCRL=no
MTU=9000
BONDING_OPTS="mode=0 miimon=100"](https://image.slidesharecdn.com/random-141107020245-conversion-gate01/85/Highload-2014-10-320.jpg)






















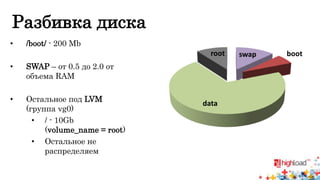
Доклад Виталия Гаврилова посвящён созданию отказоустойчивого микрокластера из попарно соединённых серверов, обеспечивающего высокую доступность и надежность через использование технологий, таких как DRBD и OCFS2. Основное внимание уделяется конфигурации сетевых интерфейсов, организации синхронного дискового пространства и миграции виртуальных машин. Также рассматриваются решения для отказоустойчивых IP-сервисов и мониторинга, при этом подчеркиваются ограничения, связанные с виртуальными машинами и производительностью системы.

























































