




























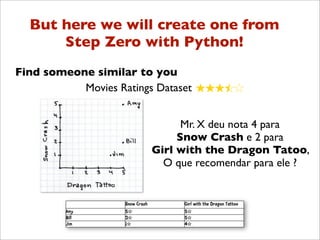



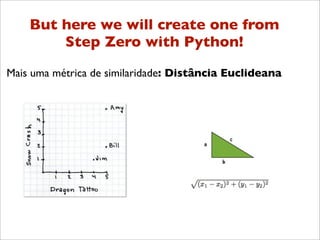




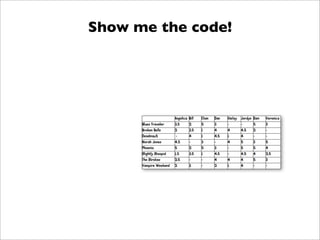



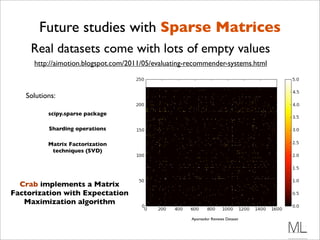
![Codificando o Mahantan
def manhattan(rating1, rating2):
"""Computes the Manhattan distance. Both rating1 and rating2 are
dictionaries of the form {'The Strokes': 3.0, 'Slightly
Stoopid': 2.5}"""
distance = 0
commonRatings = False
for key in rating1:
if key in rating2:
distance += abs(rating1[key] – rating2[key])
commonRatings = True
if commonRatings:
return distance
else:
return -1 #Indicates no ratings in common](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-54-320.jpg)

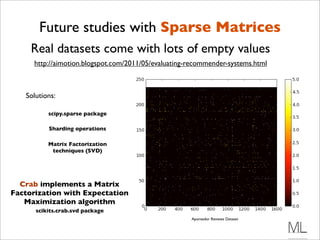
![Codificando o Mahantan
def manhattan(rating1, rating2):
"""Computes the Manhattan distance. Both rating1 and rating2 are
dictionaries of the form {'The Strokes': 3.0, 'Slightly
Stoopid': 2.5}"""
distance = 0
commonRatings = False
for key in rating1:
if key in rating2:
distance += abs(rating1[key] – rating2[key])
commonRatings = True
if commonRatings:
return distance
else:
return -1 #Indicates no ratings in common](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-56-320.jpg)
![Codificando o Mahantan
def manhattan(rating1, rating2):
"""Computes the Manhattan distance. Both rating1 and rating2 are
dictionaries of the form {'The Strokes': 3.0, 'Slightly
Stoopid': 2.5}"""
distance = 0
commonRatings = False
for key in rating1:
if key in rating2:
distance += abs(rating1[key] – rating2[key])
commonRatings = True
if commonRatings:
return distance
else:
return -1 #Indicates no ratings in common
>>> manhattan(users['Hailey'], users['Veronica'])
2.0
>>> manhattan(users['Hailey'], users['Jordyn'])
1.5
>>>](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-57-320.jpg)

![Codificando Euclidean
def euclidean(rating1, rating2):
"""Computes the euclidean distance.
Both rating1 and rating2 are dictionaries of the form
{'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
distance = 0.0
commonRatings = False
for key in rating1:
if key in rating2:
distance += pow(abs(rating1[key] - rating2[key]), 2.0)
commonRatings = True
if commonRatings:
return pow(distance, 1/2.0)
else:
return -1 #Indicates no ratings in common](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-59-320.jpg)

![Codificando Euclidean
def euclidean(rating1, rating2):
"""Computes the euclidean distance.
Both rating1 and rating2 are dictionaries of the form
{'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
distance = 0.0
commonRatings = False
for key in rating1:
if key in rating2:
distance += pow(abs(rating1[key] - rating2[key]), 2.0)
commonRatings = True
if commonRatings:
return pow(distance, 1/2.0)
else:
return -1 #Indicates no ratings in common
1.4142135623730951](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-61-320.jpg)
![Codificando Euclidean
def euclidean(rating1, rating2):
"""Computes the euclidean distance.
Both rating1 and rating2 are dictionaries of the form
{'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
distance = 0.0
commonRatings = False
for key in rating1:
if key in rating2:
distance += pow(abs(rating1[key] - rating2[key]), 2.0)
commonRatings = True
if commonRatings:
return pow(distance, 1/2.0)
else:
return -1 #Indicates no ratings in common
>>> euclidean(users['Hailey'], users['Veronica'])
1.4142135623730951](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-62-320.jpg)

![Find the closest users
def computeNearestNeighbor(username, users):
"""creates a sorted list of users based on their distance to
username"""
distances = []
for user in users:
if user != username:
distance = manhattan(users[user], users[username])
distances.append((distance, user))
# sort based on distance -- closest first
distances.sort()
return distances](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-64-320.jpg)

![Find the closest users
>>> computeNearestNeighbor('Hailey', users)
[(2.0, 'Veronica'), (4.0, 'Chan'),(4.0, 'Sam'), (4.5, 'Dan'), (5.0,
'Angelica'), (5.5, 'Bill'), (7.5, 'Jordyn')]
>>>](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-66-320.jpg)
![Find the closest users
def computeNearestNeighbor(username, users):
"""creates a sorted list of users based on their distance to
username"""
distances = []
for user in users:
if user != username:
distance = manhattan(users[user], users[username])
distances.append((distance, user))
# sort based on distance -- closest first
distances.sort()
return distances
>>> computeNearestNeighbor('Hailey', users)
[(2.0, 'Veronica'), (4.0, 'Chan'),(4.0, 'Sam'), (4.5, 'Dan'), (5.0,
'Angelica'), (5.5, 'Bill'), (7.5, 'Jordyn')]
>>>](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-67-320.jpg)

![The recommender
def recommend(username, users):
"""Give list of recommendations"""
# first find nearest neighbor
nearest = computeNearestNeighbor(username, users)[0][1]
recommendations = []
# now find bands neighbor rated that user didn't
neighborRatings = users[nearest]
userRatings = users[username]
for artist in neighborRatings:
if not artist in userRatings:
recommendations.append((artist, neighborRatings[artist]))
recommendations.sort(key=lambda artistTuple: artistTuple[1],
reverse = True)
return recommendations](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-69-320.jpg)

![The recommender
>>> recommend('Hailey', users)
[('Phoenix', 4.0), ('Blues Traveler', 3.0), ('Slightly Stoopid', 2.5)]
>>> recommend('Chan', users)
[('The Strokes', 4.0), ('Vampire Weekend', 1.0)]
>>> recommend('Angelica', users)
[]](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-71-320.jpg)
![The recommender
def recommend(username, users):
"""Give list of recommendations"""
# first find nearest neighbor
nearest = computeNearestNeighbor(username, users)[0][1]
recommendations = []
# now find bands neighbor rated that user didn't
neighborRatings = users[nearest]
userRatings = users[username]
for artist in neighborRatings:
if not artist in userRatings:
recommendations.append((artist, neighborRatings[artist]))
recommendations.sort(key=lambda artistTuple: artistTuple[1],
reverse = True)
return recommendations
>>> recommend('Hailey', users)
[('Phoenix', 4.0), ('Blues Traveler', 3.0), ('Slightly Stoopid', 2.5)]
>>> recommend('Chan', users)
[('The Strokes', 4.0), ('Vampire Weekend', 1.0)]
>>> recommend('Angelica', users)
[]](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-72-320.jpg)

](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-74-320.jpg)
![The recommender
def recommend(username, users):
"""Give list of recommendations"""
# first find nearest neighbor
nearest = computeNearestNeighbor(username, users)[0][1]
recommendations = []
# now find bands neighbor rated that user didn't
neighborRatings = users[nearest]
userRatings = users[username]
for artist in neighborRatings:
if not artist in userRatings:
recommendations.append((artist, neighborRatings[artist]))
recommendations.sort(key=lambda artistTuple: artistTuple[1],
reverse = True)
return recommendations
>>> computeNearestNeighbor('Angelica', users)
[(3.5, 'Veronica'), (4.5, 'Chan'), (5.0, 'Hailey'), (8.0, 'Sam'), (9.0,
'Bill'), (9.0, 'Dan'), (9.5, 'Jordyn')]('Hailey', users)](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-75-320.jpg)


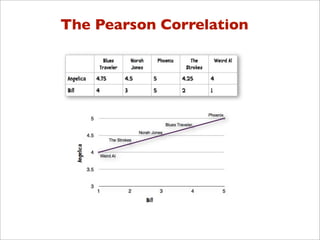
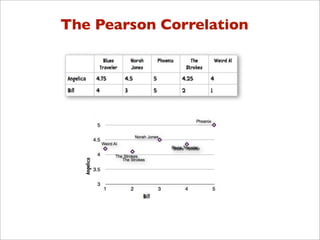
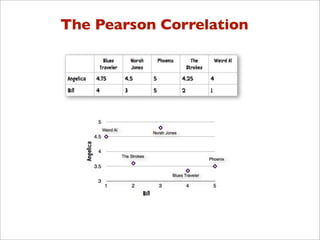

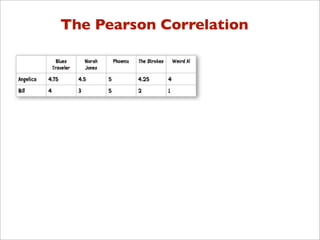

![Pearson Correlation
def pearson(rating1, rating2):
sum_xy = 0
sum_x = 0
sum_y = 0
sum_x2 = 0
sum_y2 = 0
n = 0
for key in rating1:
if key in rating2:
n += 1
x = rating1[key]
y = rating2[key]
sum_xy += x * y
sum_x += x
sum_y += y
sum_x2 += x**2
sum_y2 += y**2
# now compute denominator
denominator = sqrt(sum_x2 - (sum_x**2) / n) *
sqrt(sum_y2 -(sum_y**2) / n)
if denominator == 0:
return 0
else:
return (sum_xy - (sum_x * sum_y) / n) / denominator](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-84-320.jpg)

![Pearson Correlation
>>> pearson(users['Angelica'], users['Bill'])
-0.90405349906826993
>>> pearson(users['Angelica'], users['Hailey'])
0.42008402520840293
>>> pearson(users['Angelica'], users['Jordyn'])
0.76397486054754316
>>>](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-86-320.jpg)
![Pearson Correlation
def pearson(rating1, rating2):
sum_xy = 0
sum_x = 0
sum_y = 0
sum_x2 = 0
sum_y2 = 0
n = 0
for key in rating1:
if key in rating2:
n += 1
x = rating1[key]
y = rating2[key]
sum_xy += x * y
sum_x += x
sum_y += y
sum_x2 += x**2
sum_y2 += y**2
# now compute denominator
denominator = sqrt(sum_x2 - (sum_x**2) / n) *
sqrt(sum_y2 -(sum_y**2) / n)
if denominator == 0:
return 0
else:
return (sum_xy - (sum_x * sum_y) / n) / denominator
>>> pearson(users['Angelica'], users['Bill'])
-0.90405349906826993
>>> pearson(users['Angelica'], users['Hailey'])
0.42008402520840293
>>> pearson(users['Angelica'], users['Jordyn'])
0.76397486054754316
>>>](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-87-320.jpg)

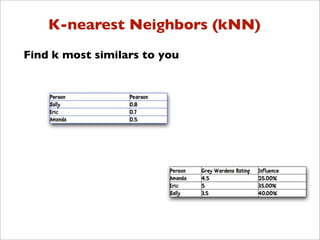







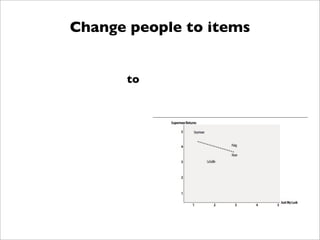
![Change people to items
{'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5}}
to
{'Lady in the Water':{'Lisa Rose':2.5,'Gene Seymour':3.0},
'Snakes on a Plane':{'Lisa Rose':3.5,'Gene Seymour':3.5}} etc.
def transformPrefs(prefs):
result={}
for person in prefs:
for item in prefs[person]:
result.setdefault(item,{})
# Flip item and person
result[item][person]=prefs[person][item]
return result](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-97-320.jpg)
![Change people to items
{'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5}}
to
{'Lady in the Water':{'Lisa Rose':2.5,'Gene Seymour':3.0},
'Snakes on a Plane':{'Lisa Rose':3.5,'Gene Seymour':3.5}} etc.
def transformPrefs(prefs):
result={}
for person in prefs:
for item in prefs[person]:
result.setdefault(item,{})
# Flip item and person
result[item][person]=prefs[person][item]
return result
>> movies=recommendations.transformPrefs(recommendations.users)
>> recommendations.computeNearestNeighbors(‘Blues Traveler’, movies)
[(0.657, 'You, Me and Dupree'), (0.487, 'Lady in the Water'), (0.111, 'Snakes on a
Plane'), (-0.179, 'The Night Listener'), (-0.422, 'Just My Luck')]](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-98-320.jpg)

![Change people to items
{'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5}}
to
{'Lady in the Water':{'Lisa Rose':2.5,'Gene Seymour':3.0},
'Snakes on a Plane':{'Lisa Rose':3.5,'Gene Seymour':3.5}} etc.
def transformPrefs(prefs):
result={}
for person in prefs:
for item in prefs[person]:
result.setdefault(item,{})
# Flip item and person
result[item][person]=prefs[person][item]
return result](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-101-320.jpg)
![Change people to items
{'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5}}
to
{'Lady in the Water':{'Lisa Rose':2.5,'Gene Seymour':3.0},
'Snakes on a Plane':{'Lisa Rose':3.5,'Gene Seymour':3.5}} etc.
def transformPrefs(prefs):
result={}
for person in prefs:
for item in prefs[person]:
result.setdefault(item,{})
# Flip item and person
result[item][person]=prefs[person][item]
return result
>> movies=recommendations.transformPrefs(recommendations.critics)
>> recommendations.computeNearestNeighbors(movies,'Superman Returns')
[(0.657, 'You, Me and Dupree'), (0.487, 'Lady in the Water'), (0.111, 'Snakes on a
Plane'), (-0.179, 'The Night Listener'), (-0.422, 'Just My Luck')]](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-102-320.jpg)



![Find the closest items
def calculateSimilarItems(prefs,sim_distance=manhattan):
! # Create a dictionary of items showing which other items they
! # are most similar to.
! result={}
! # Invert the preference matrix to be item-centric
! itemPrefs=transformPrefs(prefs)
! c=0
! for item in itemPrefs:
! ! # Status updates for large datasets
! ! c+=1
! ! if c%100==0: print "%d / %d" % (c,len(itemPrefs))
# Find the most similar items to this one
scores=computeNearestNeighbor(item,itemPrefs,distance=sim_distance)
result[item]=scores
! return result](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-106-320.jpg)
![Find the closest items
def calculateSimilarItems(prefs,sim_distance=manhattan):
! # Create a dictionary of items showing which other items they
! # are most similar to.
! result={}
! # Invert the preference matrix to be item-centric
! itemPrefs=transformPrefs(prefs)
! c=0
! for item in itemPrefs:
! ! # Status updates for large datasets
! ! c+=1
! ! if c%100==0: print "%d / %d" % (c,len(itemPrefs))
# Find the most similar items to this one
scores=computeNearestNeighbor(item,itemPrefs,distance=sim_distance)
result[item]=scores
! return result
>>> itemsim=recommendations.calculateSimilarItems(users)
>>> itemsim
{'Lady in the Water': [(0.40000000000000002, 'You, Me and Dupree'), (0.2857142857142857, 'The
Night Listener'),... 'Snakes on a Plane': [(0.22222222222222221, 'Lady in the Water'),
(0.18181818181818182, 'The Night Listener'),... etc.](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-107-320.jpg)

![The recommender
def recommend(username,users, similarities, n=3):
scores = {}
totalSim = {}
#
# now get the ratings for the user
#
userRatings = users[username]
# Loop over items rated by this user
for item, rating in userRatings.items():
#Loop over items similar to this one
for sim, other_item in similarities[item]:
# Ignore if this user has already rated this item
if other_item in userRatings: continue
# Weighted sum of rating times similarity
scores.setdefault(other_item, 0.0)
scores[other_item]+= sim * rating
# Sum of all the similarities
totalSim.setdefault(other_item, 0.0)
totalSim[other_item] += sim
# Divide each total score by total weighting to get an average
recommendations = [(score/totalSim[item],item) for item,score in scores.items()]
# finally sort and return
recommendations.sort(key=lambda artistTuple: artistTuple[1], reverse = True)
# Return the first n items
return recommendations[:n]](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-109-320.jpg)
![The recommender
>>> recommend('Hailey', users,similarities,3)
[(3.1176470588235294, 'Slightly Stoopid'),
(2.639207507820647, 'Phoenix'),(2.64476386036961, 'Blues Traveler')]](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-110-320.jpg)
![The recommender
def recommend(username,users, similarities, n=3):
scores = {}
totalSim = {}
#
# now get the ratings for the user
#
userRatings = users[username]
# Loop over items rated by this user
for item, rating in userRatings.items():
#Loop over items similar to this one
for sim, other_item in similarities[item]:
# Ignore if this user has already rated this item
if other_item in userRatings: continue
# Weighted sum of rating times similarity
scores.setdefault(other_item, 0.0)
scores[other_item]+= sim * rating
# Sum of all the similarities
totalSim.setdefault(other_item, 0.0)
totalSim[other_item] += sim
# Divide each total score by total weighting to get an average
recommendations = [(score/totalSim[item],item) for item,score in scores.items()]
# finally sort and return
recommendations.sort(key=lambda artistTuple: artistTuple[1], reverse = True)
# Return the first n items
return recommendations[:n]
>>> recommend('Hailey', users,similarities,3)
[(3.1176470588235294, 'Slightly Stoopid'),
(2.639207507820647, 'Phoenix'),(2.64476386036961, 'Blues Traveler')]](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-111-320.jpg)
![source, the recommendation architecture that we propose will would rely more on collaborative-filtering techniques, that is,
aggregate the results of such filtering techniques. Bezerra and Carvalho proposed approaches where the results
the reviews from similar users.
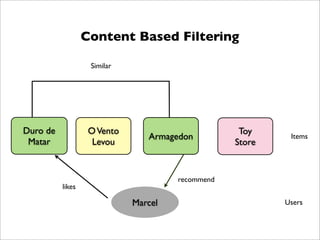
We aim at integrating the previously mentioned hybrid prod- Figure 1 shows a overview of our meta recommender
achieved showed to be very promising [19].
approach. By combining the content-based filtering and the
uct recommendation approach in a mobile application so the
A.
Crab is already in production
users could benefit from useful and logical recommendations. collaborative-based one into a hybrid recommender system, it
Moreover, we aim at providing a suited explanation for each would use the services/products III. S YSTEM catalogues
repositories which D ESIGN
recommendation to the user, since the current approaches just the services to be recommended, and the review repository
Application data information our mobile recommender sys-
that contains the user opinions about those services. All this for
only deliver product recommendations with a overall score
without pointing out the appropriateness of such recommen- datatembecan be from data source containers in the web product description
can extracted divided into two parts: the rec
dation [13]. Besides the basic information provided by the such(such location-based social network Foursquare its attributes) and the user
as the as location, description and [17] as
Hybrid Meta Approach gives the system’s architecture and
suppliers, the system will deliver the explanation, providing
relevant reviews of similar users, we believe that it will
tags, etc.). The Figure 3
increase the confidence in the buying decision process and the
displayed at the Figure 2 and the location recommendation
engine from Google: Google HotPot [18]. by user (such as rating, comments,
reviews or ratings provided
mo
wh
product accepptance rate. In the mobile context this approach
po
could help the users in this process and showing the user
relative components. thi
opinions could contribute to achieve this task. rec
spe
!"#$"%&'$ 5&-$
!"#$%&'%($) !".,"/#) acc
!"*+#,$+'-) !"*+#,$+'-) +,-*.&$
!(#$()&'*&%$
/01&'234&$ !6#$6,00&41&7$
wh
res
!<#$<'&2&'&04&%A$B,431*,0A$&14C$
ves
0+44%6+'%$,.")1%#"2)
0+($"($)1%#"2)
3,4$"',(5)
ou
3,4$"',(5)
)))67,8,#%)+,4%$91$'%4)-1":))))
suc
!"#$%&"'()*+,#&-,.)
/$%,0"12()*3$4%)3""5.)
))))1,;&,<4)<1&%%,')=2)4&:&8$1))
)))))))))))%$4%,5)94,14>?) <',7)41$
pro
8&=,%*1,'>$
exp
8&4,99&0731*,0$:0;*0&$ !B#$B*%1$,2$D4,'&7$<',7)41%$
!(#$()&'*&%$
ma
8&?*&@$
we
Fig. 2. User Reviews from Foursquare Social Network 8&=,%*1,'>$
com
7"$%)
!"8+99"(2"'))
!8#$830E&7$<',7)41%$
The content-based filtering approach will be used to filter ext
the product/service repository, while the collaborative based
8&%).1%$ B.
approach will derive the product review recommendations. In
addition we will use text mining techniques to distinct the
!"8+99"(2%$,+(#) polarity of the user review between positive or negative one.
This information summarized would contribute in the product Architecture
Fig. 3. Mobile Recommender System rat
score recommendation computation. The final product recom-
Fig. 1. Meta Recommender Architecture
mendation score is computed by integrating the result of both
me
recommenders. By now, weproduct/service recommender, the user could
In our mobile are considering to use different and
Since one of the goals of this work is to incorporate options regarding this integration approach, one and get a list of recommen-
different data sources of user opinions and descriptions, we filter some products or services at special oth
is the symbolic data analysis approach (SDA) [19], which
have addopted an meta recommendation architecture. By using eachtations. The user user ratings/reviews arehis preferences or give his
product description and also can enter modeled ow
a meta recommender architecture, the system would provide
a personalized control over the generated recommendation list
feedback to some offered product recommendation.
as set of modal symbolic descriptions that summarizes the Re
information provided by the corresponding data sources. It is](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-113-320.jpg)
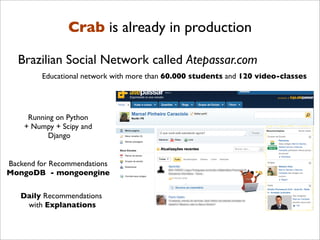




![Distributed Computing with mrJob
https://github.com/Yelp/mrjob
"""The classic MapReduce job: count the frequency of words.
"""
from mrjob.job import MRJob
import re
WORD_RE = re.compile(r"[w']+")
class MRWordFreqCount(MRJob):
def mapper(self, _, line):
for word in WORD_RE.findall(line):
yield (word.lower(), 1)
def reducer(self, word, counts):
yield (word, sum(counts))
if __name__ == '__main__':
MRWordFreqCount.run()
It supports Amazon’s Elastic MapReduce(EMR) service, your own Hadoop cluster or
local (for testing)
http://aimotion.blogspot.com/2012/08/introduction-to-recommendations-with.html](https://image.slidesharecdn.com/recsysintroduction-130225232248-phpapp02/85/Construindo-Sistemas-de-Recomendacao-com-Python-119-320.jpg)








The document discusses recommendation systems using Python, highlighting their importance in managing information overload and suggesting relevant content to users. It covers various methods like content-based filtering, collaborative filtering, and hybrid approaches, while providing practical examples and code snippets for implementation. The author encourages utilizing frameworks like Crab for building recommendation engines, illustrating the process of finding similar users and generating recommendations based on user ratings.






































































































