








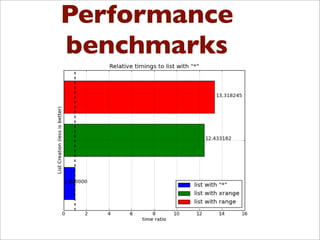
![Solutions ?
In
[1]:
def
f(x):
...:
return
x*x
...:
In
[2]:
%timeit
for
x
in
range
(100):
f(x)
100000
loops,
best
of
3:
20.3
us
per
loop](https://image.slidesharecdn.com/benchypyne-130525122430-phpapp02/85/Benchy-python-framework-for-performance-benchmarking-of-Python-Scripts-9-320.jpg)


![Writing benchmarks
from
benchy.api
import
Benchmark
common_setup
=
""
statement
=
"lst
=
['i'
for
x
in
range(100000)]"
benchmark1
=
Benchmark(statement,
common_setup,
name=
"range")
statement
=
"lst
=
['i'
for
x
in
xrange(100000)]"
benchmark2
=
Benchmark(statement,
common_setup,
name=
"xrange")
statement
=
"lst
=
['i']
*
100000"
benchmark3
=
Benchmark(statement,
common_setup,
name=
"range")](https://image.slidesharecdn.com/benchypyne-130525122430-phpapp02/85/Benchy-python-framework-for-performance-benchmarking-of-Python-Scripts-13-320.jpg)
![Use them in your
workflow
[1]:
print
benchmark1.run()
{'memory':
{'repeat':
3,
'success':
True,
'units':
'MB',
'usage':
2.97265625},
'runtime':
{'loops':
100,
'repeat':
3,
'success':
True,
'timing':
7.5653696060180664,
'units':
'ms'}}
Same code as %timeit
and %memit](https://image.slidesharecdn.com/benchypyne-130525122430-phpapp02/85/Benchy-python-framework-for-performance-benchmarking-of-Python-Scripts-14-320.jpg)
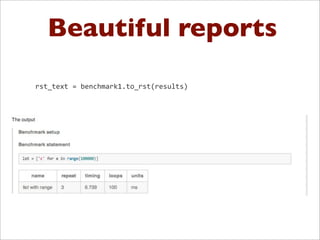



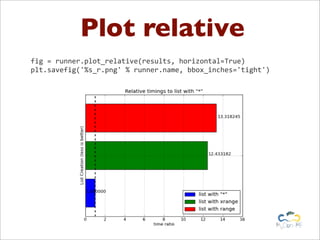
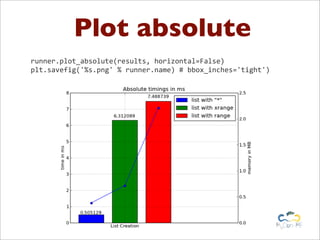



![db.py
import
sqlite3
class
BenchmarkDb(object):
"""
Persistence
handler
for
bechmark
results
"""
def
_create_tables(self):
self._cursor.execute("drop
table
if
exists
benchmarksuites")
self._cursor.execute("drop
table
if
exists
benchmarks")
self._cursor.execute("drop
table
if
exists
results")
...
self._cursor.execute('CREATE
TABLE
benchmarks(checksum
text
PRIMARY
KEY,
name
text,
description
text,
suite_id
integer,
FOREIGN
KEY(suite_id)
REFERENCES
benchmarksuites(id))')
self._cursor.execute('CREATE
TABLE
results(id
integer
PRIMARY
KEY
AUTOINCREMENT,
checksum
text,
timestamp
timestamp,
ncalls
text,
timing
float,
traceback
text,
FOREIGN
KEY(checksum)
REFERENCES
benchmarks(checksum))')
self._con.commit()
def
write_benchmark(self,
bm,
suite=None):
if
suite
is
not
None:
self._cursor.execute('SELECT
id
FROM
benchmarksuites
where
name
=
"%s"'
%
suite.name)
row
=
self._cursor.fetchone()
else:
row
=
None
if
row
==
None:
self._cursor.execute('INSERT
INTO
benchmarks
VALUES
(?,
?,
?,
?)',
(bm.checksum,
bm.name,
bm.description,
None))
else:
self._cursor.execute('INSERT
INTO
benchmarks
VALUES
(?,
?,
?,
?)',
(bm.checksum,
bm.name,
bm.description,
row[0]))](https://image.slidesharecdn.com/benchypyne-130525122430-phpapp02/85/Benchy-python-framework-for-performance-benchmarking-of-Python-Scripts-27-320.jpg)

![Git Repo
class
GitRepository(Repository):
"""
Read
some
basic
statistics
about
a
git
repository
"""
def
__init__(self,
repo_path):
self.repo_path
=
repo_path
self.git
=
_git_command(self.repo_path)
(self.shas,
self.messages,
self.timestamps,
self.authors)
=
self._parse_commit_log()
[('d87fdf2', datetime.datetime(2013, 3, 22, 16, 55, 38)), ('a90a449', datetime.datetime(2013, 3, 22, 16, 54, 36)),
('fe66a86', datetime.datetime(2013, 3, 22, 16, 51, 2)), ('bea6b21', datetime.datetime(2013, 3, 22, 13, 14, 22)),
('bde5e63', datetime.datetime(2013, 3, 22, 5, 2, 56)), ('89634f6', datetime.datetime(2013, 3, 20, 4, 16, 19))]](https://image.slidesharecdn.com/benchypyne-130525122430-phpapp02/85/Benchy-python-framework-for-performance-benchmarking-of-Python-Scripts-29-320.jpg)
![Git Repo
class
BenchmarkRepository(object):
"""
Manage
an
isolated
copy
of
a
repository
for
benchmarking
"""
...
def
_copy_repo(self):
if
os.path.exists(self.target_dir):
print
'Deleting
%s
first'
%
self.target_dir
#
response
=
raw_input('%s
exists,
delete?
y/n'
%
self.target_dir)
#
if
response
==
'n':
#
raise
Exception('foo')
cmd
=
'rm
-‐rf
%s'
%
self.target_dir
print
cmd
os.system(cmd)
self._clone(self.target_dir_tmp,
self.target_dir)
self._prep()
self._copy_benchmark_scripts_and_deps()
def
_clone(self,
source,
target):
cmd
=
'git
clone
%s
%s'
%
(source,
target)
print
cmd
os.system(cmd)
def
_copy_benchmark_scripts_and_deps(self):
pth,
_
=
os.path.split(os.path.abspath(__file__))
deps
=
[os.path.join(pth,
'run_benchmarks.py')]
if
self.dependencies
is
not
None:
deps.extend(self.dependencies)
for
dep
in
deps:
cmd
=
'cp
%s
%s'
%
(dep,
self.target_dir)
print
cmd
proc
=
subprocess.Popen(cmd,
shell=True)
proc.wait()](https://image.slidesharecdn.com/benchypyne-130525122430-phpapp02/85/Benchy-python-framework-for-performance-benchmarking-of-Python-Scripts-30-320.jpg)







![Working now:
Module detection
by_module
=
{}
benchmarks
=
[]
modules
=
['metrics',
'recommenders',
'similarities']
for
modname
in
modules:
ref
=
__import__(modname)
by_module[modname]
=
[v
for
v
in
ref.__dict__.values()
if
isinstance(v,
Benchmark)]
benchmarks.extend(by_module[modname])
for
bm
in
benchmarks:
assert(bm.name
is
not
None)](https://image.slidesharecdn.com/benchypyne-130525122430-phpapp02/85/Benchy-python-framework-for-performance-benchmarking-of-Python-Scripts-39-320.jpg)




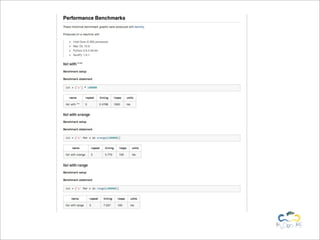
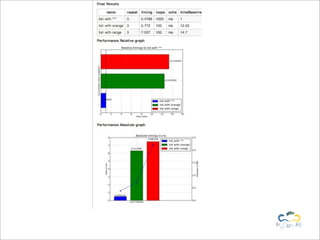
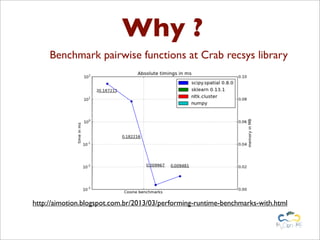
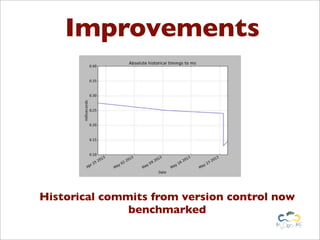
Benchy is a lightweight Python framework for performing benchmarks on code. It allows generating performance and memory usage graphs to compare different code implementations. Benchmarks can be written as objects and executed via a BenchmarkRunner to obtain results. Results are stored in a SQLite database and full reports can be generated in reStructuredText format. The framework aims to provide an easy way to integrate benchmarks into the development workflow.
![F[4]](https://cdn.slidesharecdn.com/ss_thumbnails/f4-150302174824-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)































![Managing multigenerations in the Barbadian workspace[1]](https://cdn.slidesharecdn.com/ss_thumbnails/managingmultigenerationsinthebarbadianworkspace1-111130130003-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










































































