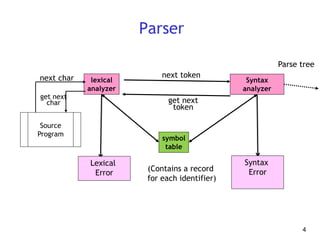
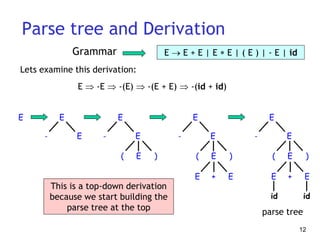
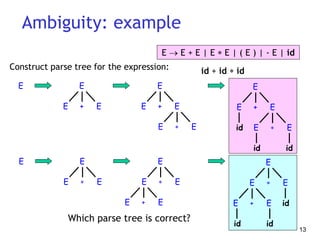
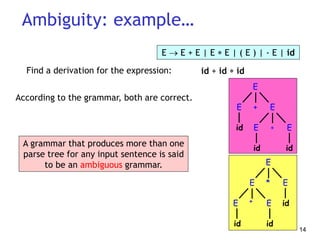
This document discusses syntax analysis and parsing. It introduces context-free grammars and how they are used to specify the syntax of programming languages. There are two main types of parsing: top-down parsing which builds the parse tree from the root going down, and bottom-up parsing which builds up the tree from the leaves to the root. Specific parsing algorithms like recursive descent and LR parsing are also introduced.




























![Cd2 [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/cd2autosaved-161231072301-thumbnail.jpg?width=640&height=640&fit=bounds)
























































