Download to read offline




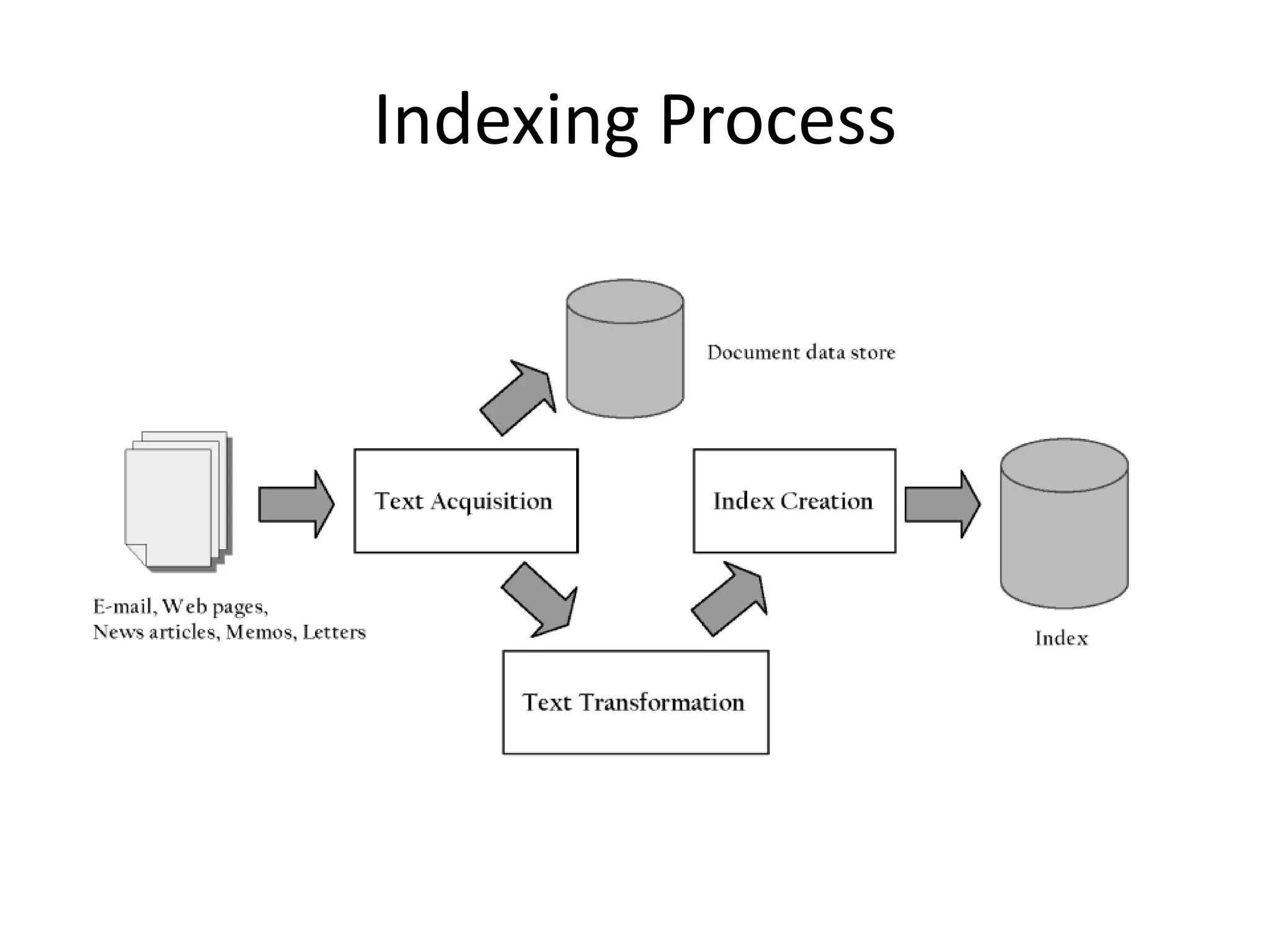

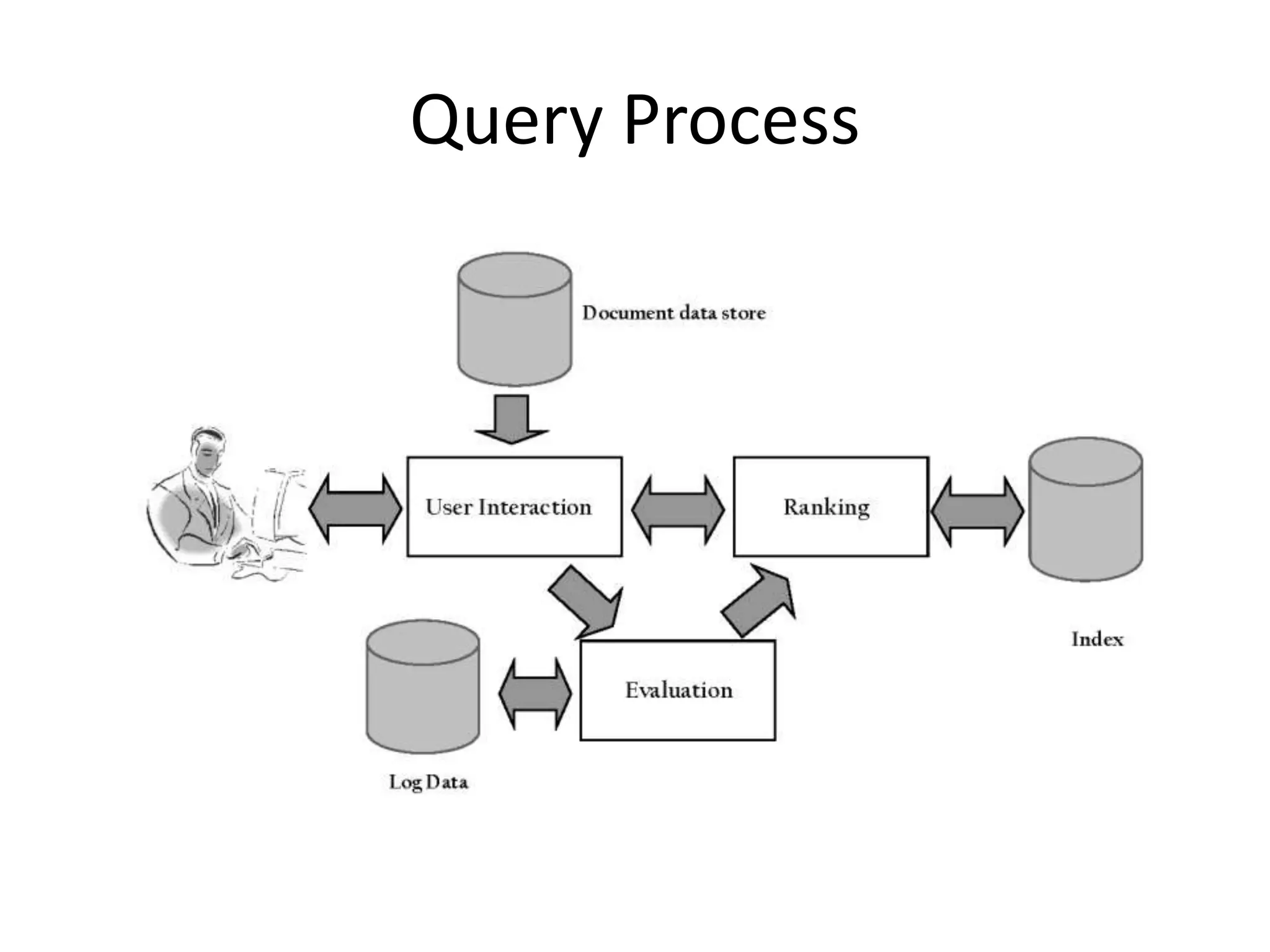



















This document describes the basic architecture of a search engine, including its two main processes: indexing and query. The indexing process involves acquiring text from sources, transforming it by parsing, stemming, etc., and creating indexes for fast searching. The query process allows users to input queries, transform queries, rank and retrieve relevant documents from the indexes, and output search results. Key components described are crawlers, parsers, stemmers, inverted indexes, ranking algorithms, and query logs for evaluation.






















































































![Computer Networks 01[1 using all terms].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/computernetworks011-251214040533-327dd9f8-thumbnail.jpg?width=640&height=640&fit=bounds)