Downloaded 20 times





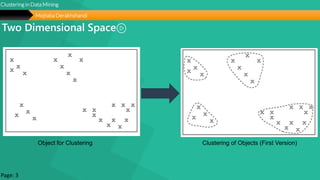
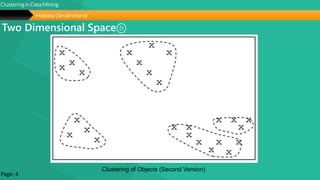



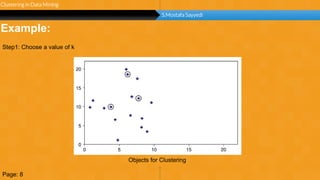


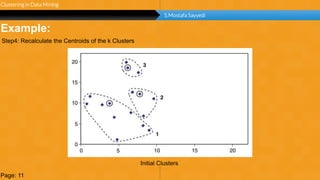
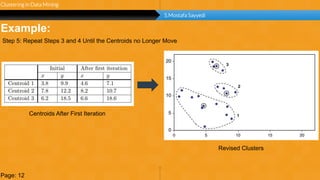



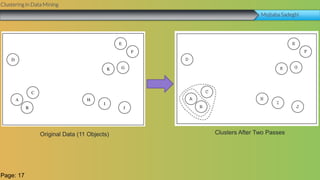
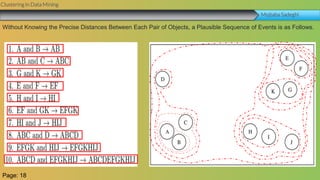
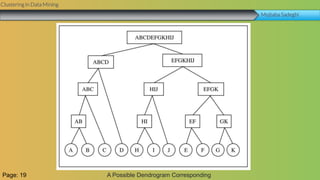


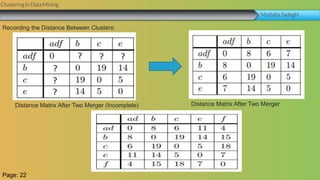
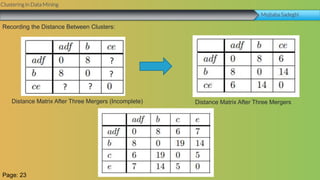
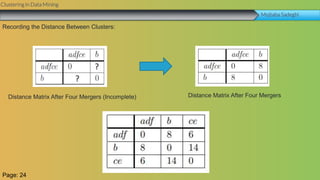
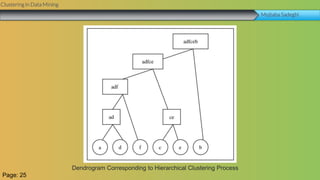




This document summarizes a group project report on clustering in data mining. It discusses different types of clustering algorithms including K-means clustering and agglomerative hierarchical clustering. For K-means clustering, it provides an example showing how clusters are formed by assigning objects to centroids and recalculating centroids over iterations. For hierarchical clustering, it shows how clusters are merged based on distances recorded in a distance matrix and represented through a dendrogram. The document contains examples and diagrams to illustrate key steps and concepts in clustering techniques.































![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)




![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)























![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)












