Download as PDF, PPTX








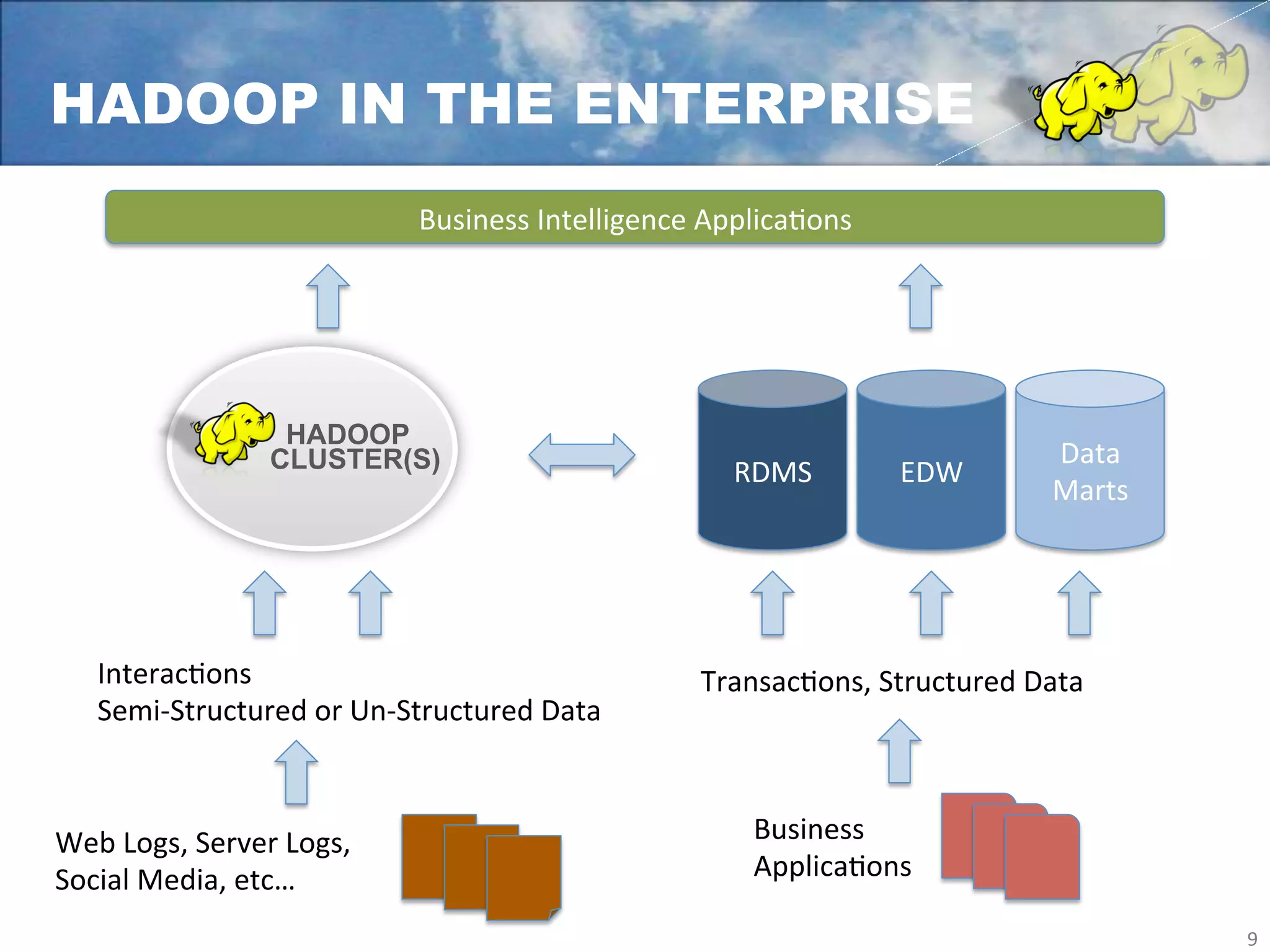

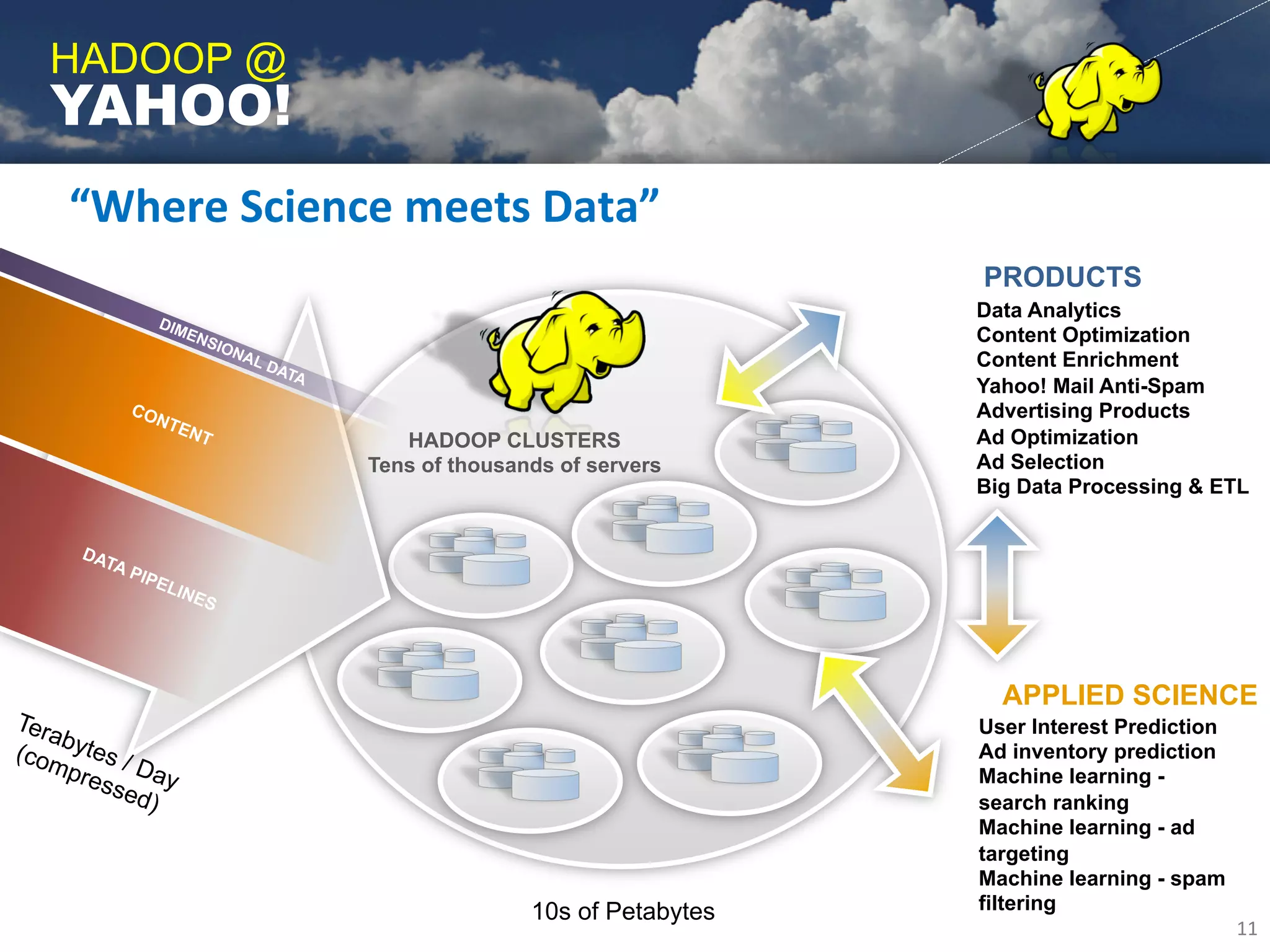
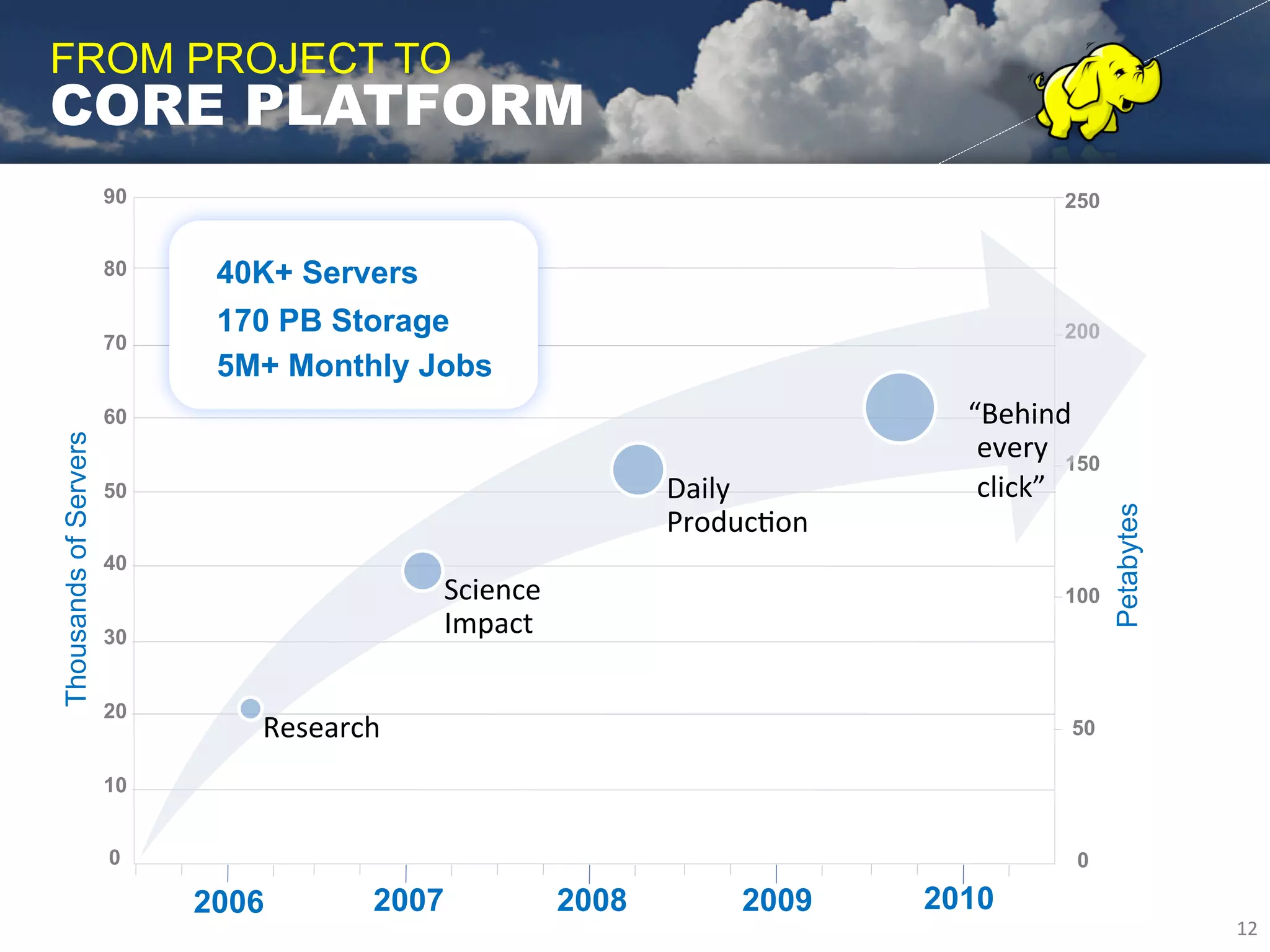
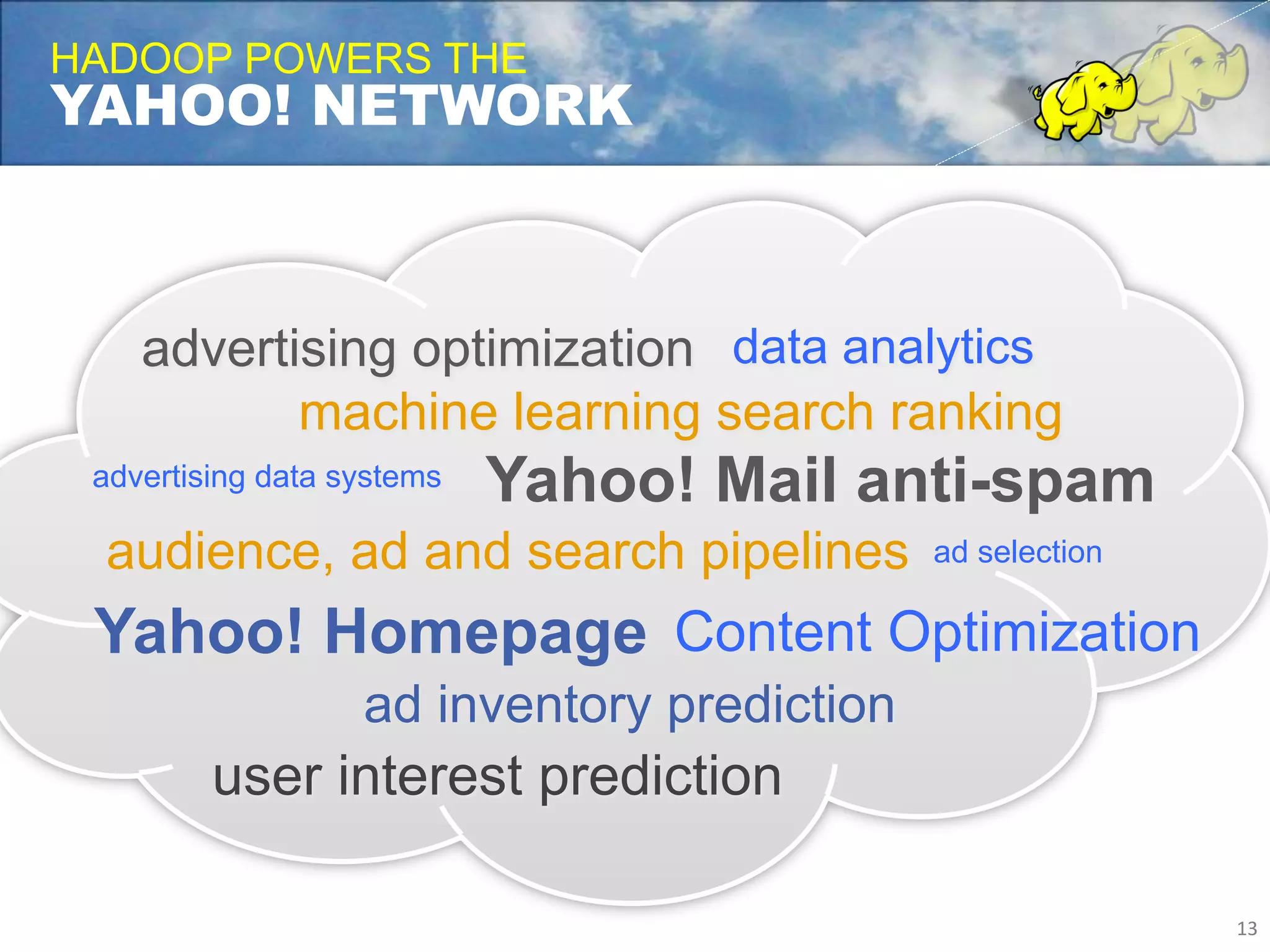

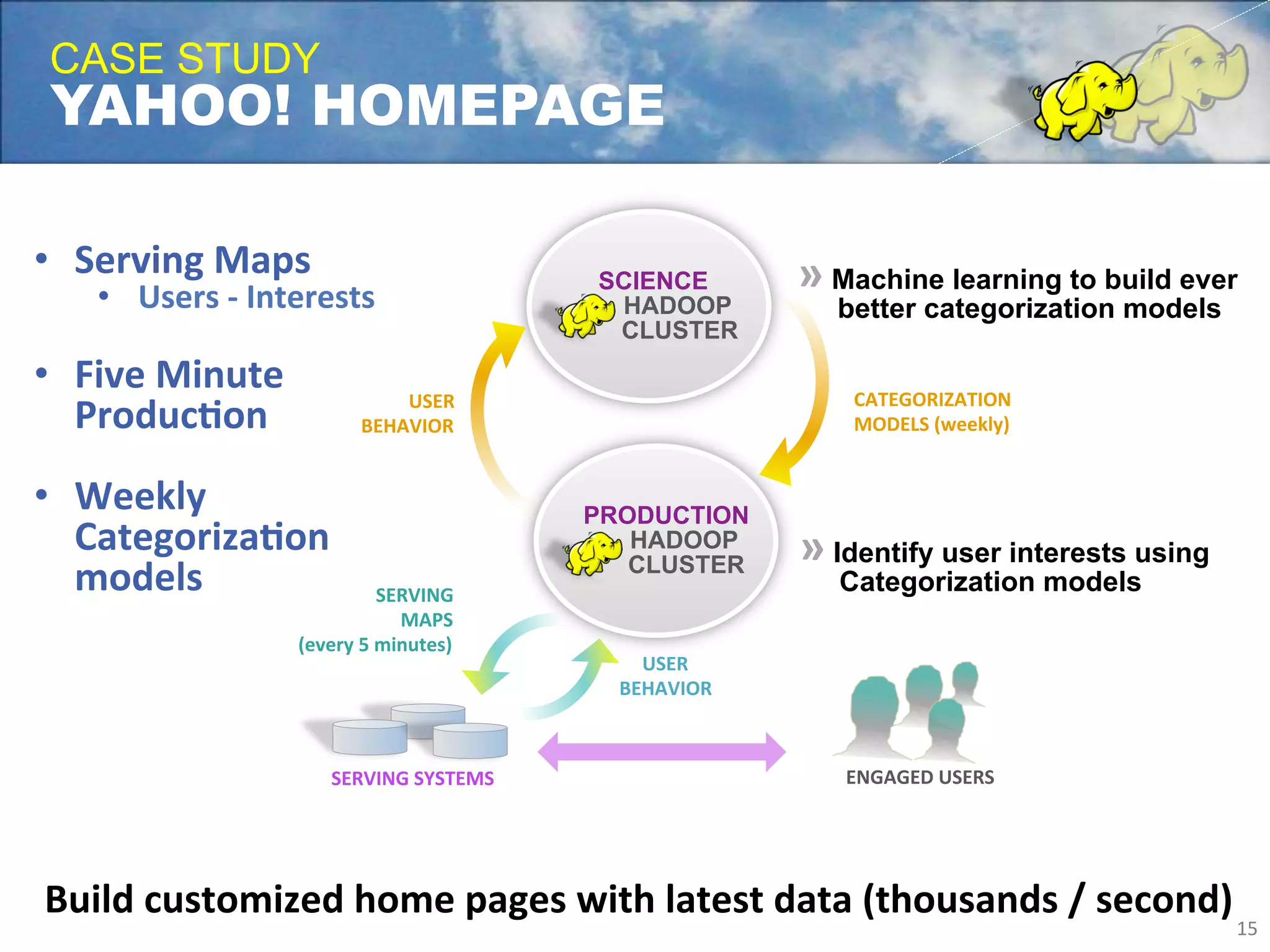
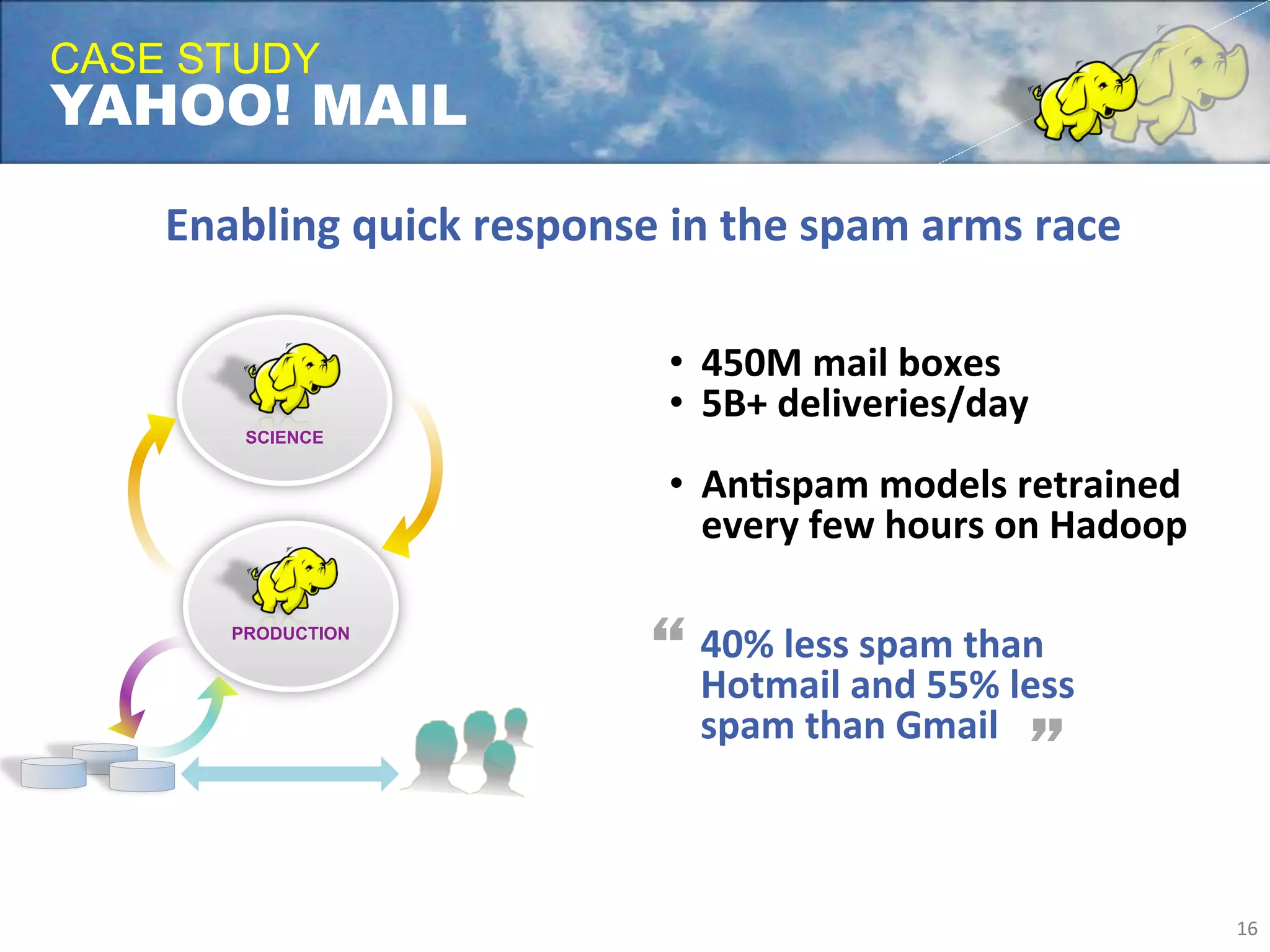


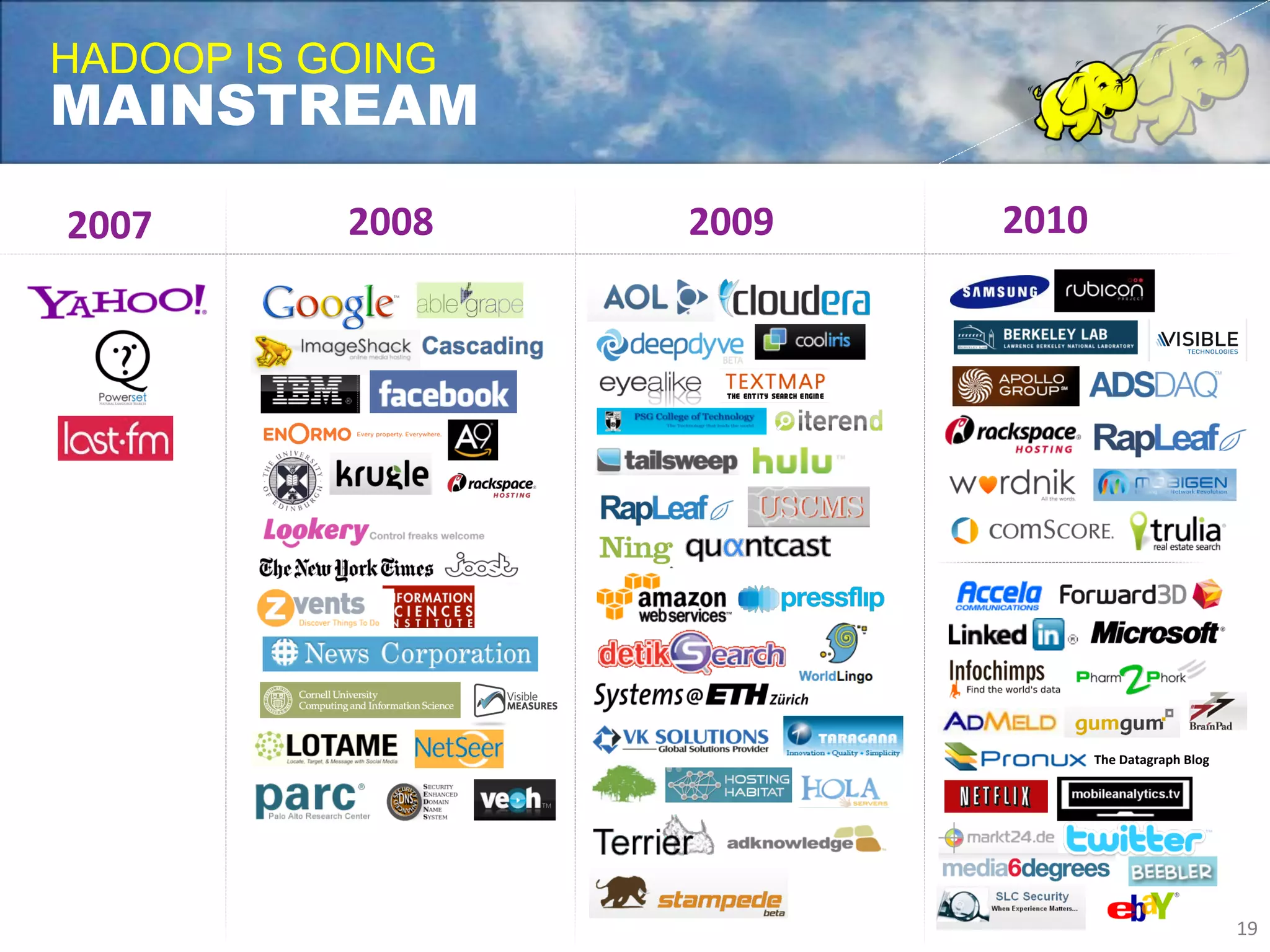
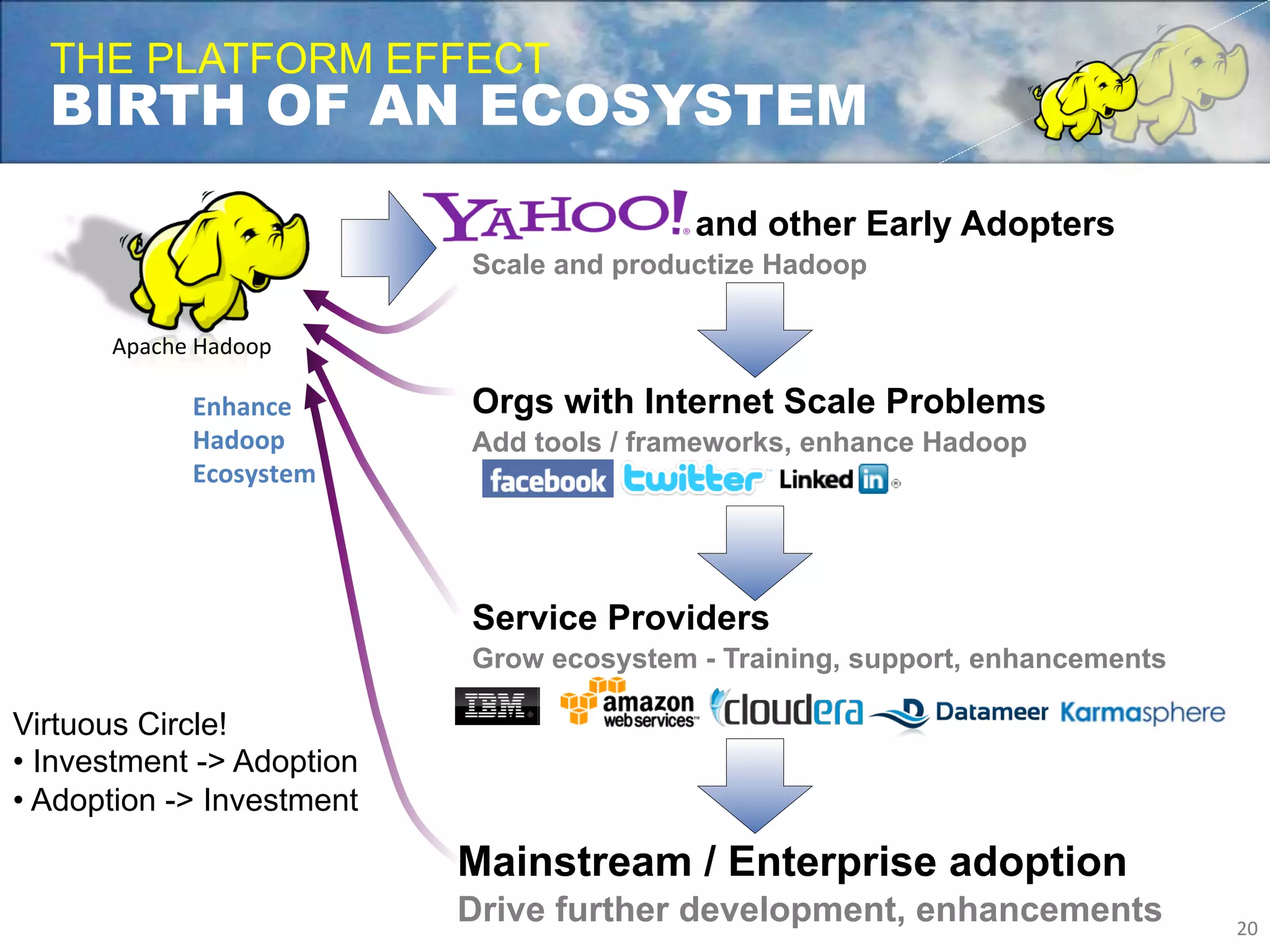




Yahoo uses Apache Hadoop extensively to power many of its products and services. Hadoop allows Yahoo to gain insights from massive amounts of data, including user data from services like Flickr and Yahoo Mail. Yahoo has contributed over 70% of the code to the Apache Hadoop project to date. Hadoop is critical to Yahoo's business by enabling personalization, spam filtering, content optimization, and other data-driven features. Yahoo runs Hadoop on tens of thousands of servers storing over 100 petabytes of data. The company continues working to enhance Hadoop's scalability, flexibility, and performance to make it more suitable for enterprise use.

































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

