Downloaded 96 times






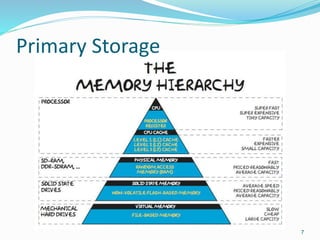


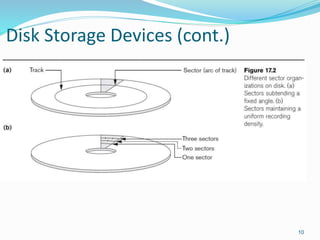

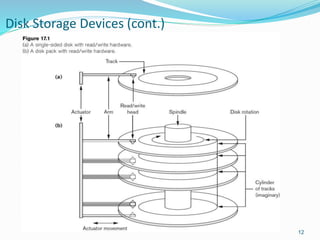
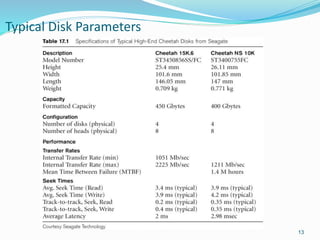


















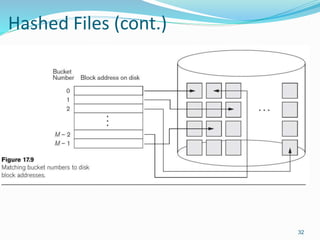

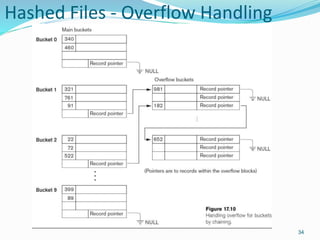




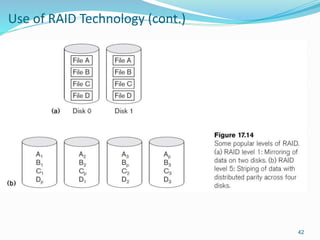




This document provides an overview of database storage systems, focusing on primary and secondary storage, particularly disk storage devices. It discusses how data is organized in records, including concepts of blocking, file types, and operations performed on files, as well as techniques for efficient disk access, such as RAID technology. Additionally, it covers methods for organizing records in files, including unordered, ordered, and hashed files.

































































































