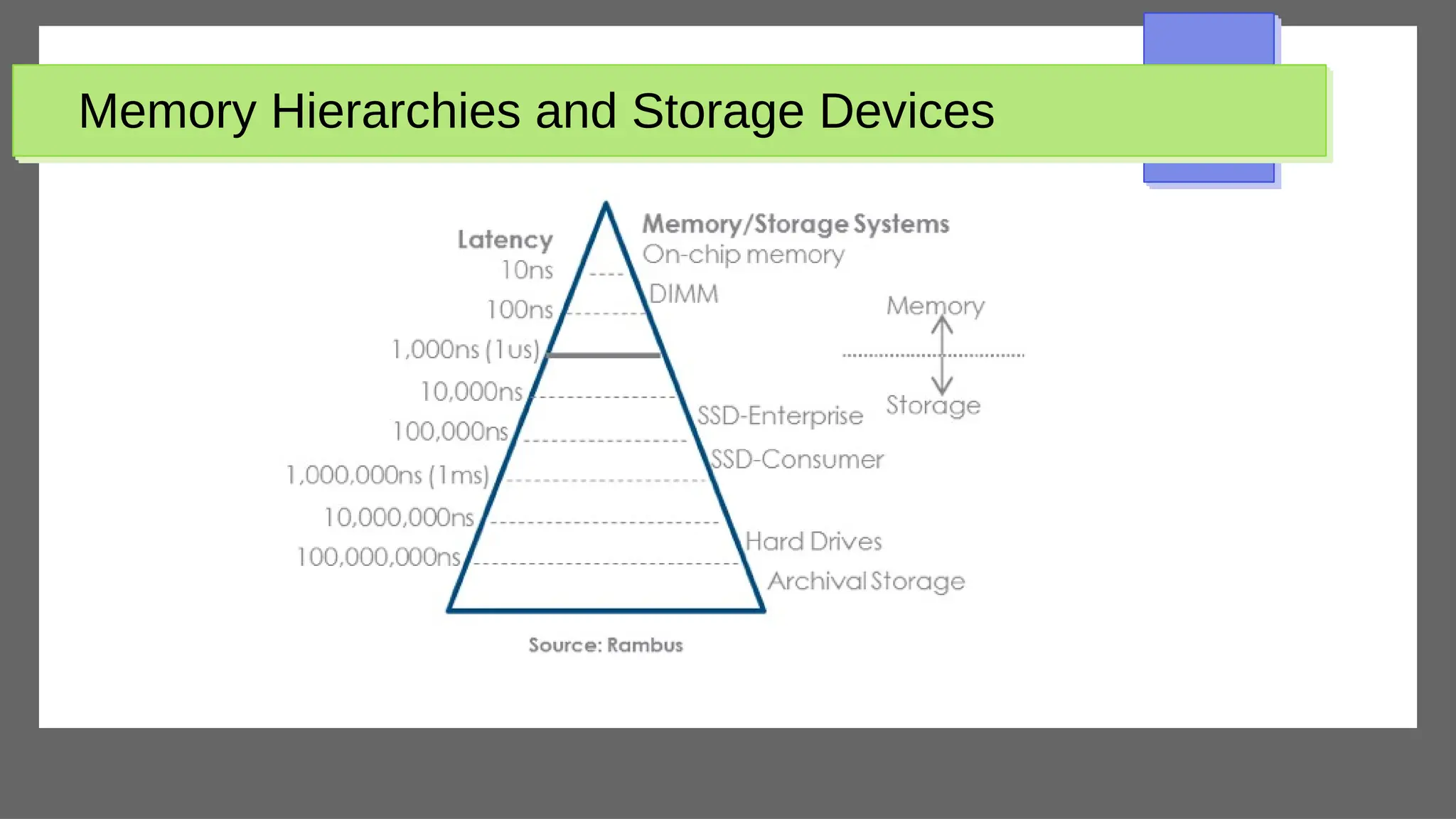
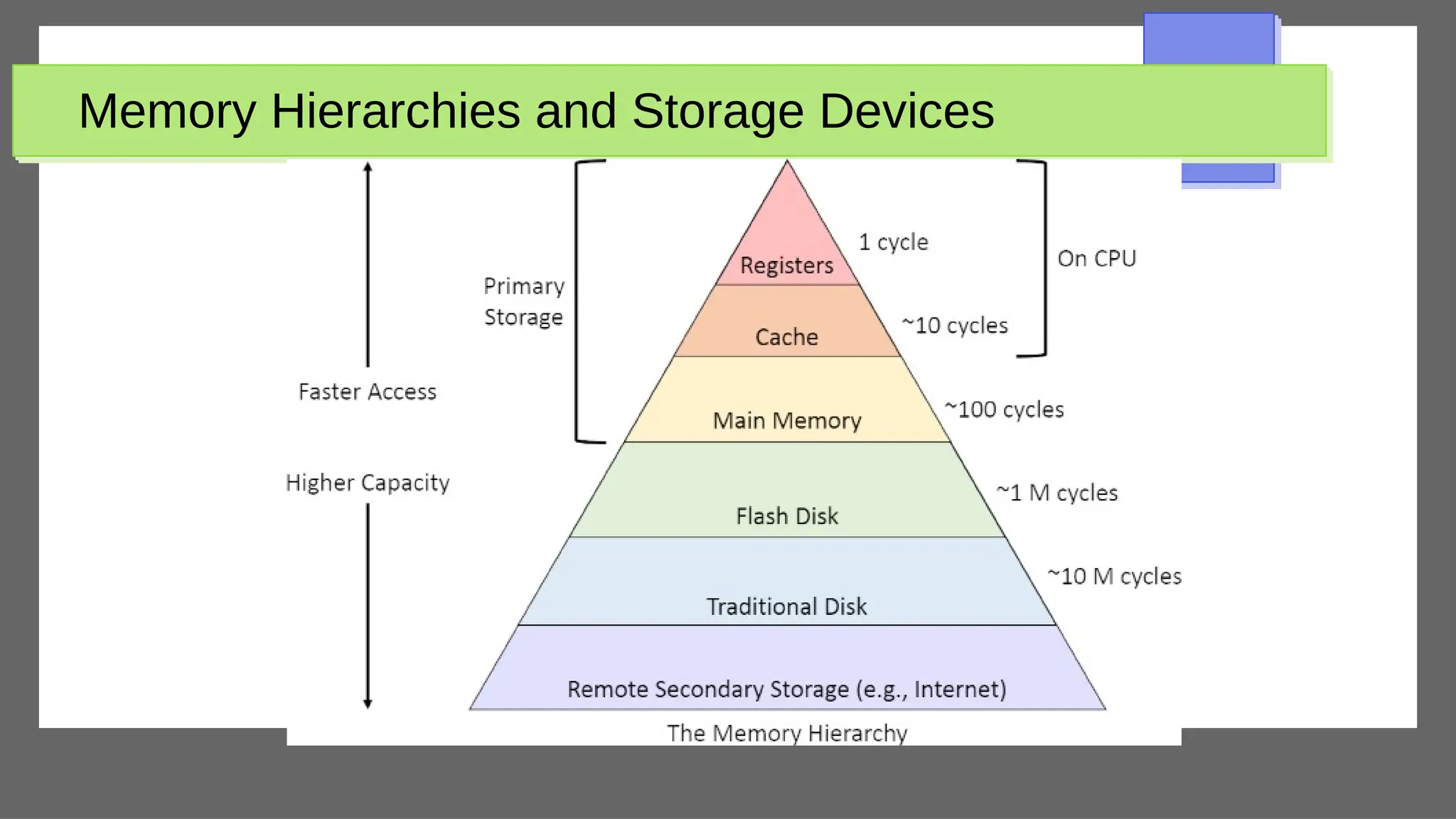
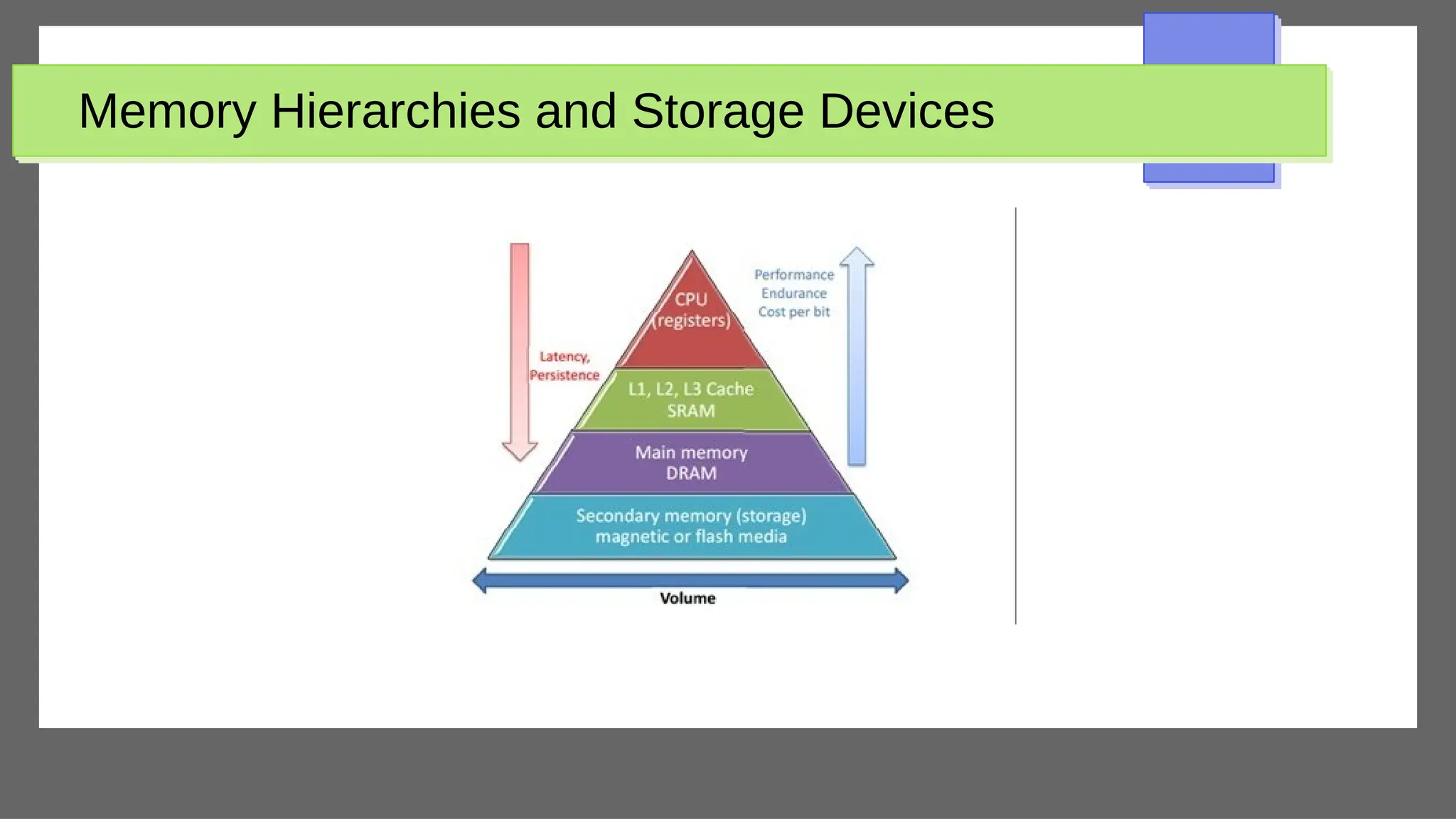
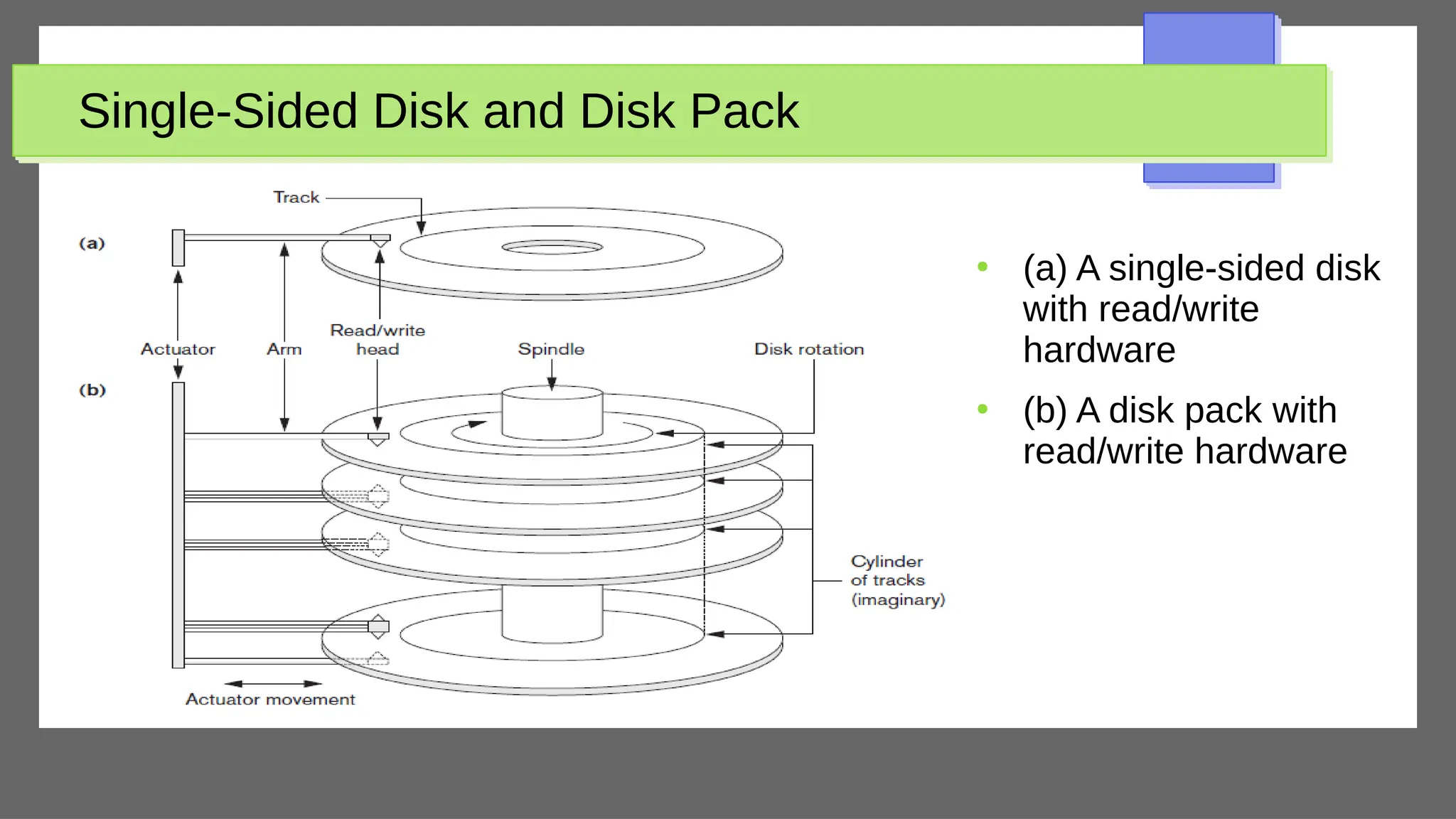
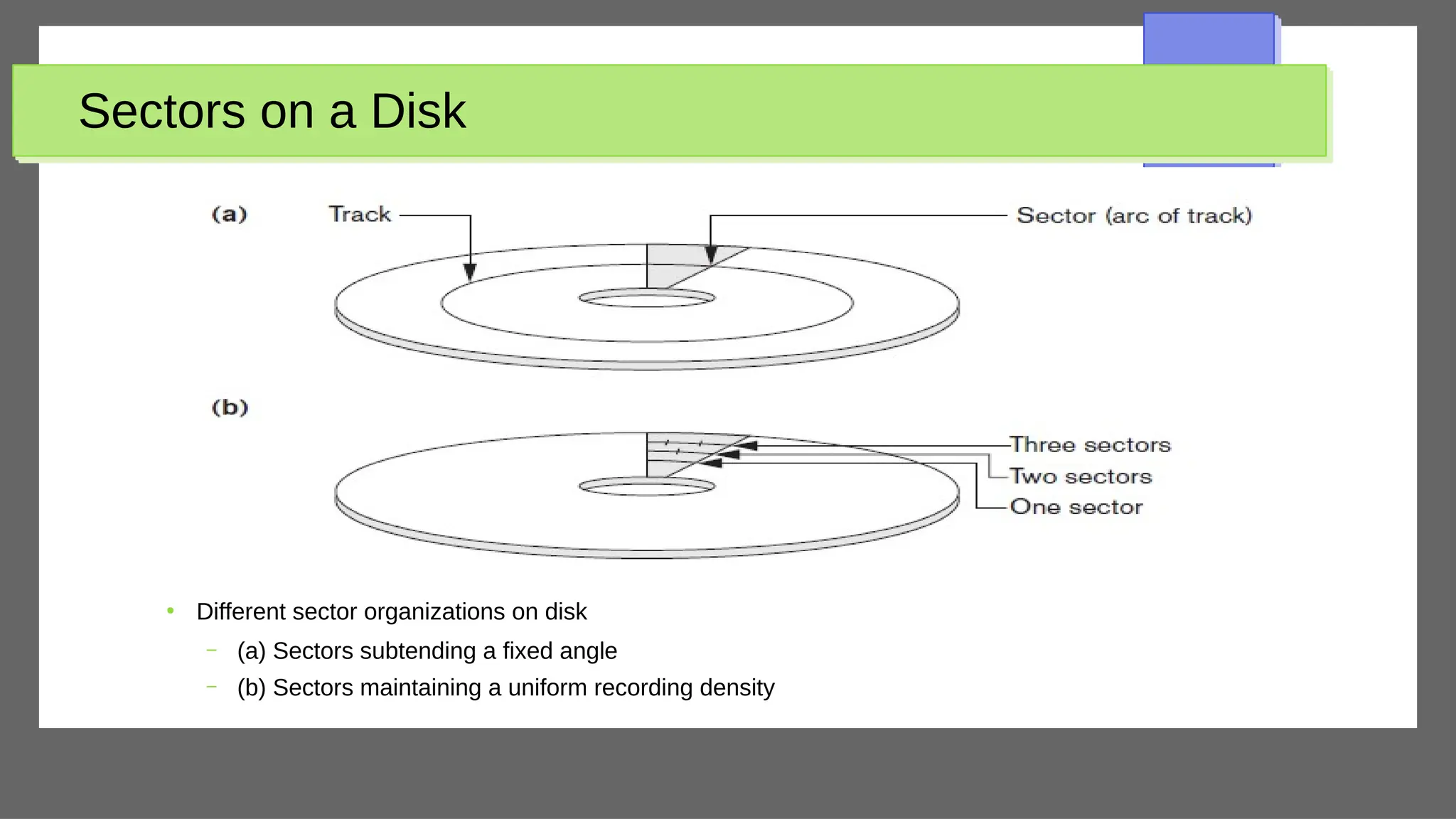
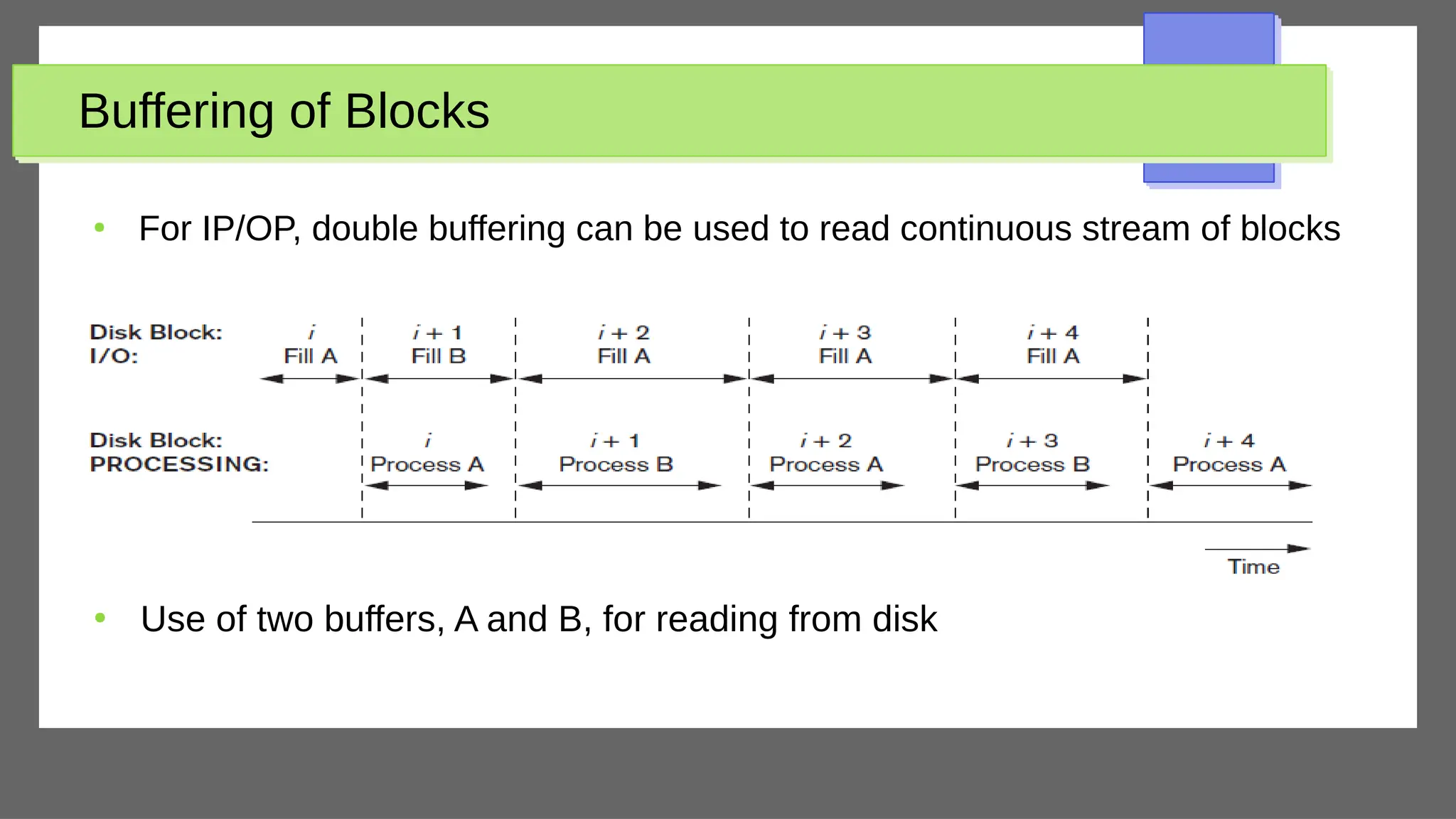
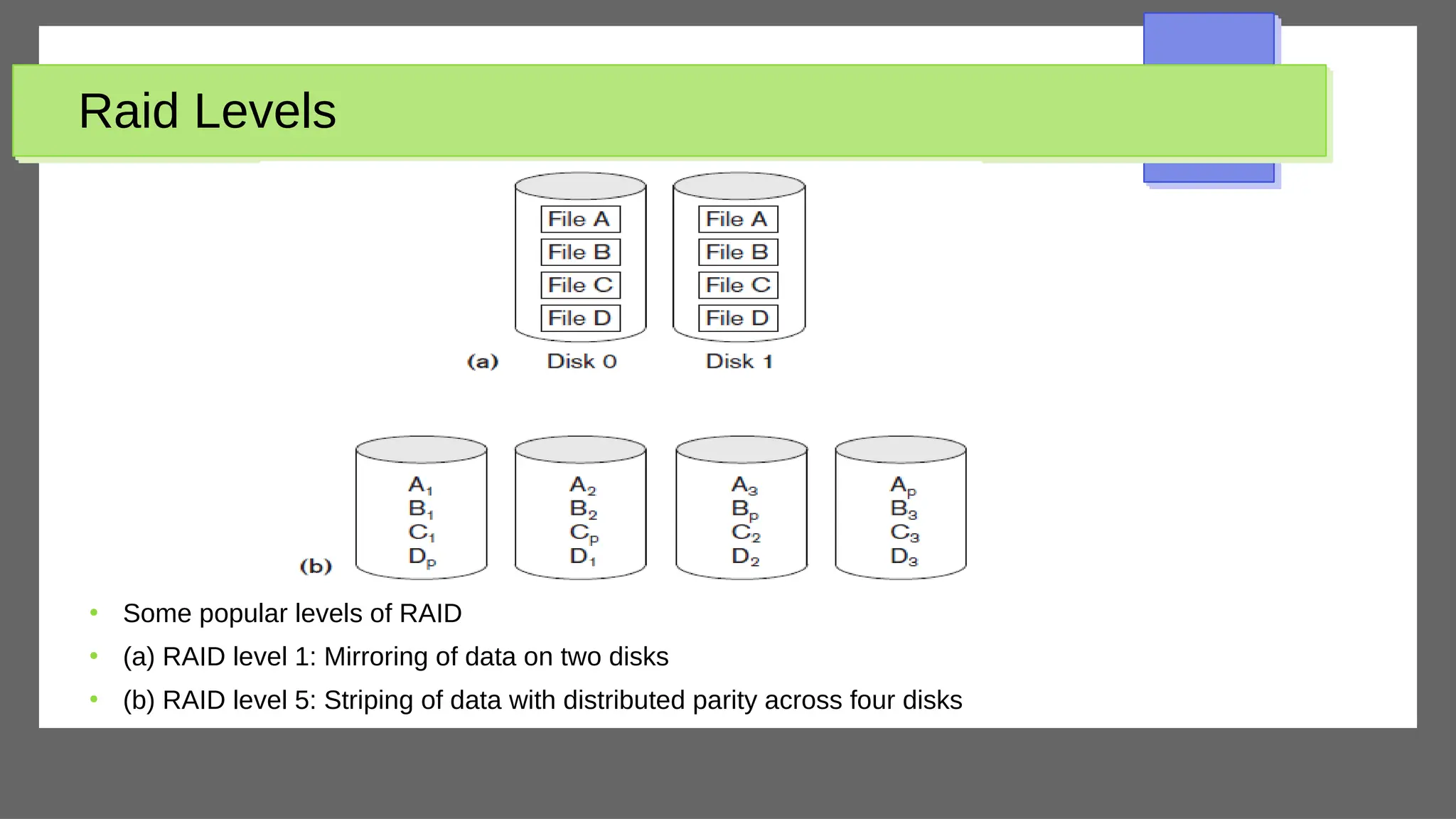
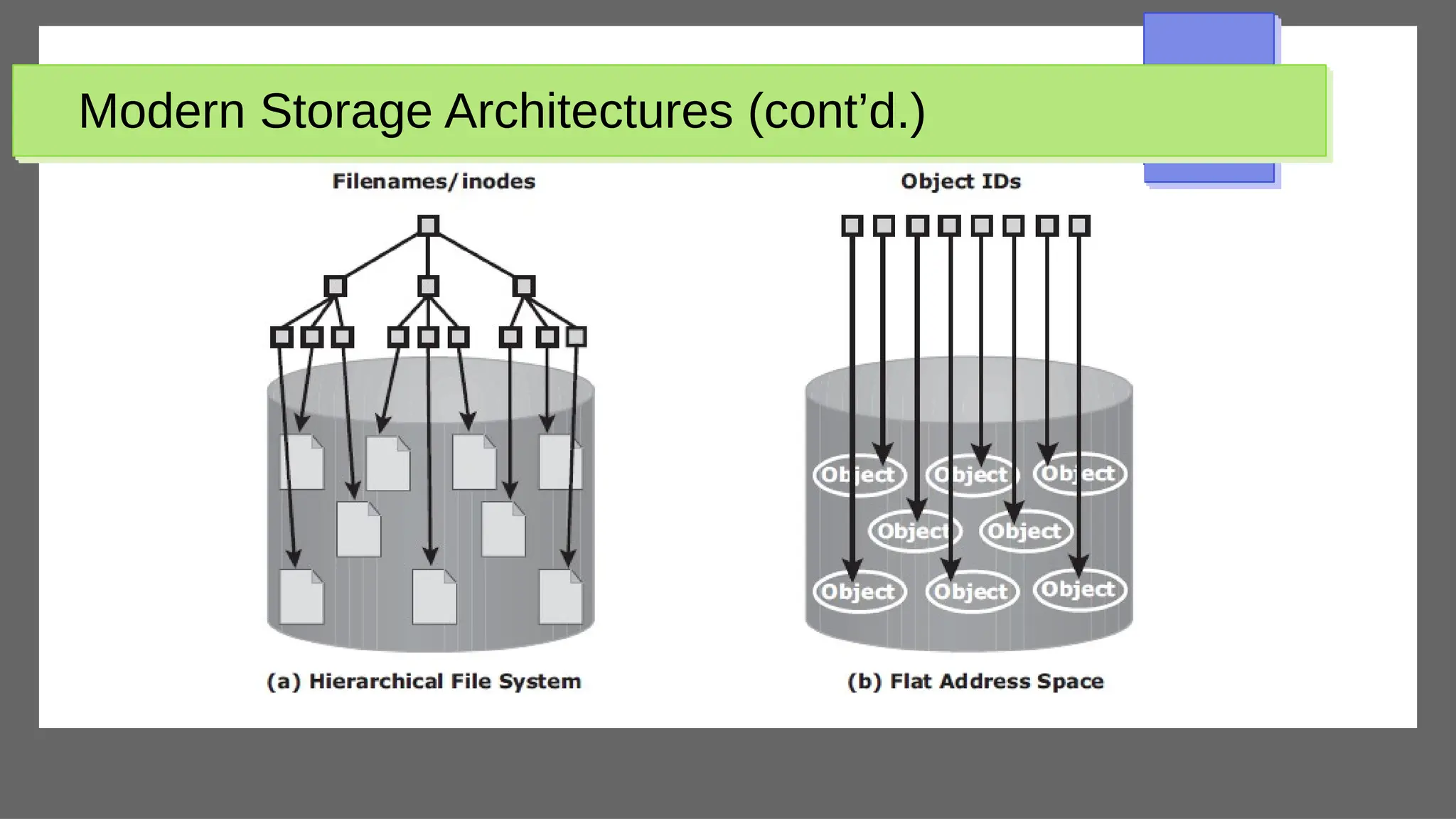
The document discusses physical database design and storage architectures. It covers topics like secondary storage devices, buffering blocks, placing file records on disk, different types of files (heap files and sorted files), hashing techniques, and modern storage systems like RAID. The key aspects covered are how databases are typically stored on magnetic disks using physical file structures, different storage devices and hierarchies, placing records on disks, indexing and organizing records in files, and techniques for efficient data access and storage.