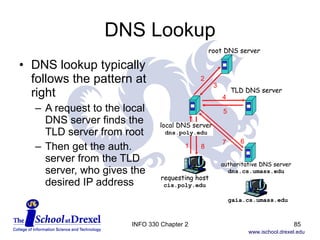
The document discusses the application layer in computer networking. It covers key concepts like client-server architecture, peer-to-peer architecture, and hybrid architectures. It also describes several important application layer protocols, including HTTP, FTP, SMTP, POP3, IMAP, and DNS.













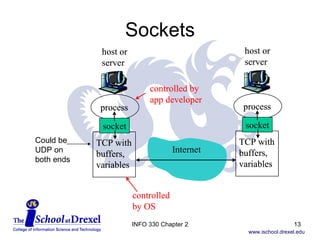


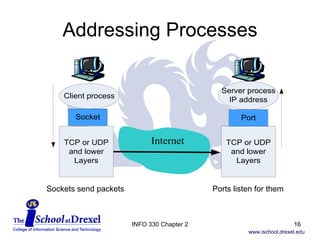





















![HTTP Messages HTTP messages are two types, request messages (from client) and response messages (from server) All HTTP messages are plain ASCII text ‘ Both types of message consist of a start-line, zero or more header fields (also known as "headers"), an empty line (i.e., a line with nothing preceding the CRLF) indicating the end of the header fields, and possibly a message-body.’ [RFC 2616, para 4.1] CRLF is a “carriage return and line feed” INFO 330 Chapter 2](https://image.slidesharecdn.com/chapter-2153/85/Chapter-2-38-320.jpg)
![HTTP Messages There are many headers which could appear in requests or responses Cache-Control, Connection , Date , Pragma, Trailer, Transfer-Encoding, Upgrade, Via, and/or Warning [RFC 2616, para 4.5] Disclaimer : RFC 2616 is 176 pages long – so we’re just providing a summary of where to look for info if you’re curious about the details of these messages INFO 330 Chapter 2](https://image.slidesharecdn.com/chapter-2153/85/Chapter-2-39-320.jpg)
![HTTP Requests Request messages have variable number of lines, depending on the method called General request syntax is Method Request-URI HTTP-Version Methods are OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE, or CONNECT [RFC 2616, para 5.1.1] Most commonly used is GET Request-URI is the desired Uniform Resource Identifier (URI, commonly called a URL) INFO 330 Chapter 2](https://image.slidesharecdn.com/chapter-2153/85/Chapter-2-40-320.jpg)
![HTTP Requests HTTP-Version is what it sounds like, e.g. HTTP/1.1 There are many possible request headers Accept, Accept-Charset, Accept-Encoding, Accept-Language, Authorization, Expect, From, Host , If-Match, If-Modified-Since, If-None-Match, If-Range, If-Unmodified-Since, Max-Forwards, Proxy-Authorization, Range, Referer, TE (extension transfer-codings), and/or User-Agent [RFC 2616, para 5.3] INFO 330 Chapter 2](https://image.slidesharecdn.com/chapter-2153/85/Chapter-2-41-320.jpg)
![HTTP Responses HTTP responses go from server to client General syntax starts with HTTP-Version Status-Code Reason-Phrase [RFC 2616, para 6.1] The Status-Code could be dozens of values "200" OK "403" Forbidden "404" Not Found The Reason-Phrase is any text phrase assigned INFO 330 Chapter 2](https://image.slidesharecdn.com/chapter-2153/85/Chapter-2-42-320.jpg)
![HTTP Responses Response headers can include Accept-Ranges, Age, ETag, Location, Proxy-Authenticate, Retry-After, Server , Vary, and/or WWW-Authenticate [RFC 2616, para 6.2] Responses usually include entities, unless the HEAD method was used INFO 330 Chapter 2](https://image.slidesharecdn.com/chapter-2153/85/Chapter-2-43-320.jpg)
![HTTP Entities An entity is the object sent or returned with an HTTP message Entities can be with requests or responses Entity headers include Allow, Content-Encoding, Content-Language, Content-Length (bytes), Content-Location, Content-MD5, Content-Range, Content-Type , Expires, Last-Modified , and/or extension-header [RFC 2616, para 7.1] Where extension-header is any allowable message-header for that kind of message INFO 330 Chapter 2](https://image.slidesharecdn.com/chapter-2153/85/Chapter-2-44-320.jpg)









![FTP Commands and replies are very basic Most commands are three or four-letter abbreviations Replies are three-digit codes, followed by text Command connection is based on Telnet, incidentally [RFC 959, para 2.3] Due to its age, FTP has provisions for a huge range of data types (ASCII or EBCDIC) and file, record, and page structures INFO 330 Chapter 2](https://image.slidesharecdn.com/chapter-2153/85/Chapter-2-54-320.jpg)




![SMTP Other commands include ( with comments in italics ) RSET (abort current transaction) SEND FROM:<reverse-path> SOML FROM:<reverse-path> (send or mail) SAML FROM:<reverse-path> (send and mail) VRFY <string> (verify a user name) EXPN <string> (expand mailing list) HELP [ <string>] NOOP (just send an OK reply) TURN (your turn to be client or server) INFO 330 Chapter 2](https://image.slidesharecdn.com/chapter-2153/85/Chapter-2-59-320.jpg)