Downloaded 21 times







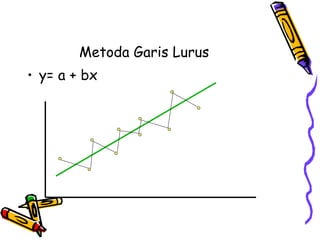
![• Xi variabel independen ke-i
• Yi variabel dependen ke-i maka bentuk model
regresi sederhana adalah :
Yi = α + β X i + ε i , i = 1,2,, n
dengan
α , β parameter yang tidak diketahui
εi sesatan random dgn asumsi
E[ε i ] = 0
Var (ε i ) = σ 2](https://image.slidesharecdn.com/chap5anregkorelasi-130112032128-phpapp01/85/Chap5-an-reg-korelasi-8-320.jpg)

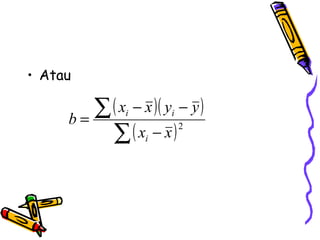







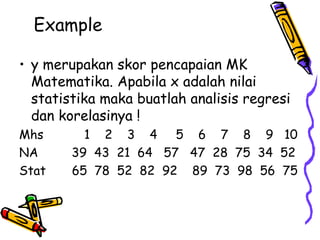









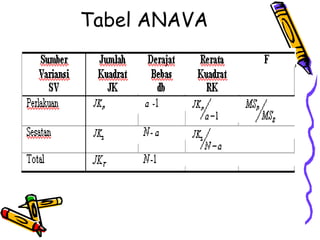


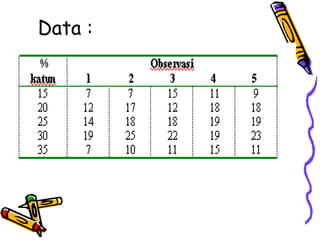



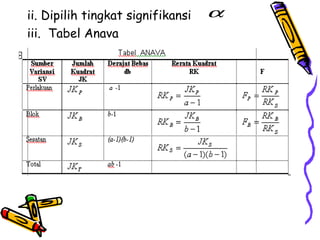
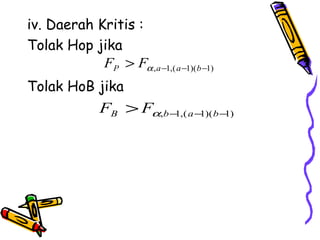



Statistika parametrik digunakan untuk melakukan inferensi terhadap rata-rata populasi, membandingkan dua rata-rata populasi, dan menganalisis hubungan antar variabel menggunakan korelasi dan regresi. Metode ini meliputi penggunaan uji-z, uji-t, uji-F, dan analisis regresi linier untuk memodelkan hubungan antara variabel tergantung dan bebas.

















































































