Download as PDF, PPTX






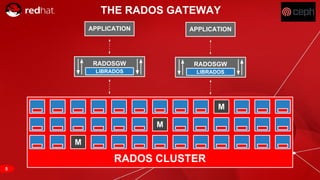

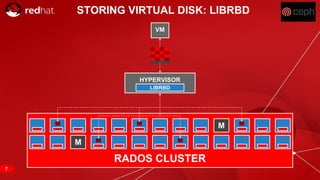
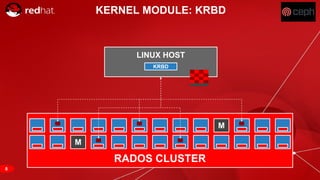

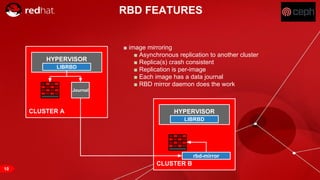

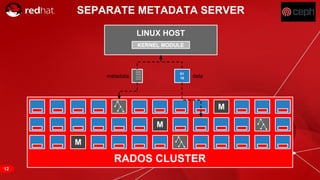

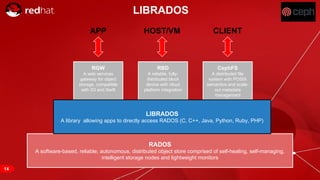



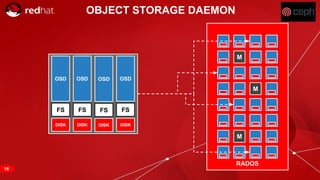



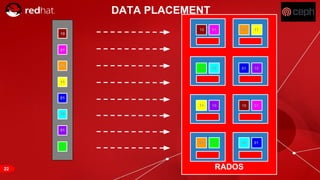
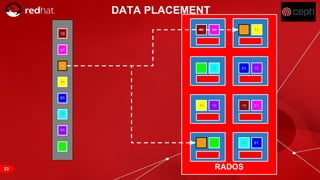
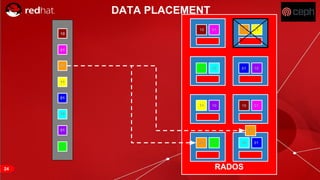



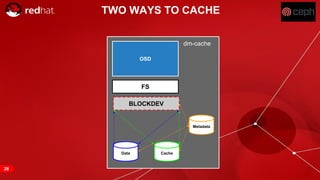

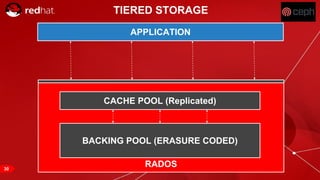
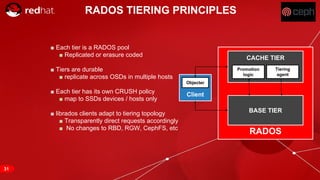
















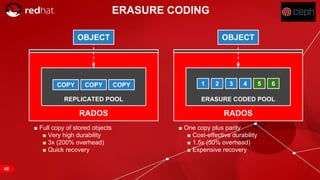
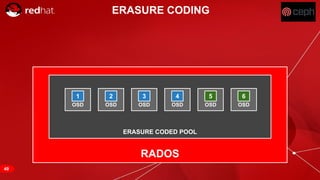
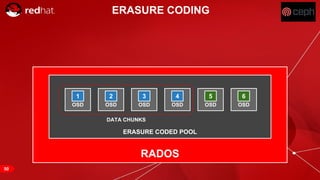
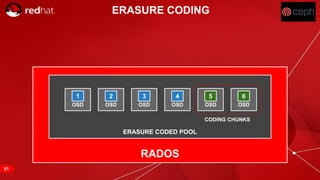
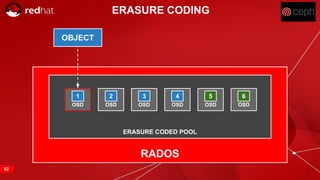


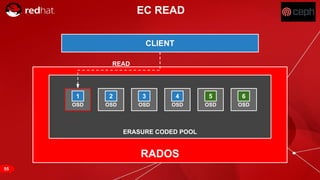
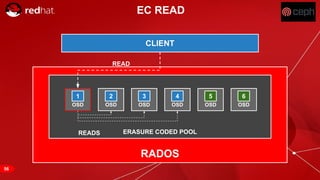
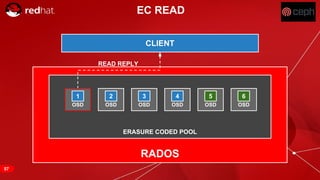

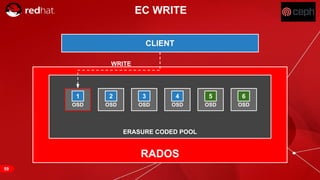
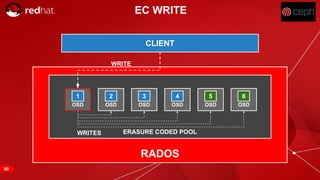
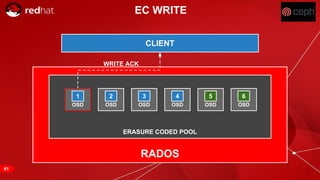

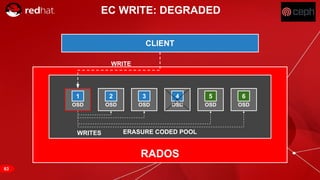

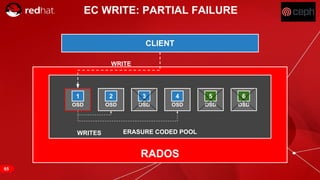





The document discusses cache tiering and erasure coding in Ceph. It provides an overview of Ceph components and architecture, including RADOS, LIBRADOS, RBD, RGW and CephFS. It then covers data placement using CRUSH, cache tiering approaches using multiple RADOS pools, and erasure coding which stores data and coding chunks across OSDs for fault tolerance with less overhead than replication. Read and write operations for cache tiering and erasure coded pools are described.


































































