Download to read offline


![www.scling.com
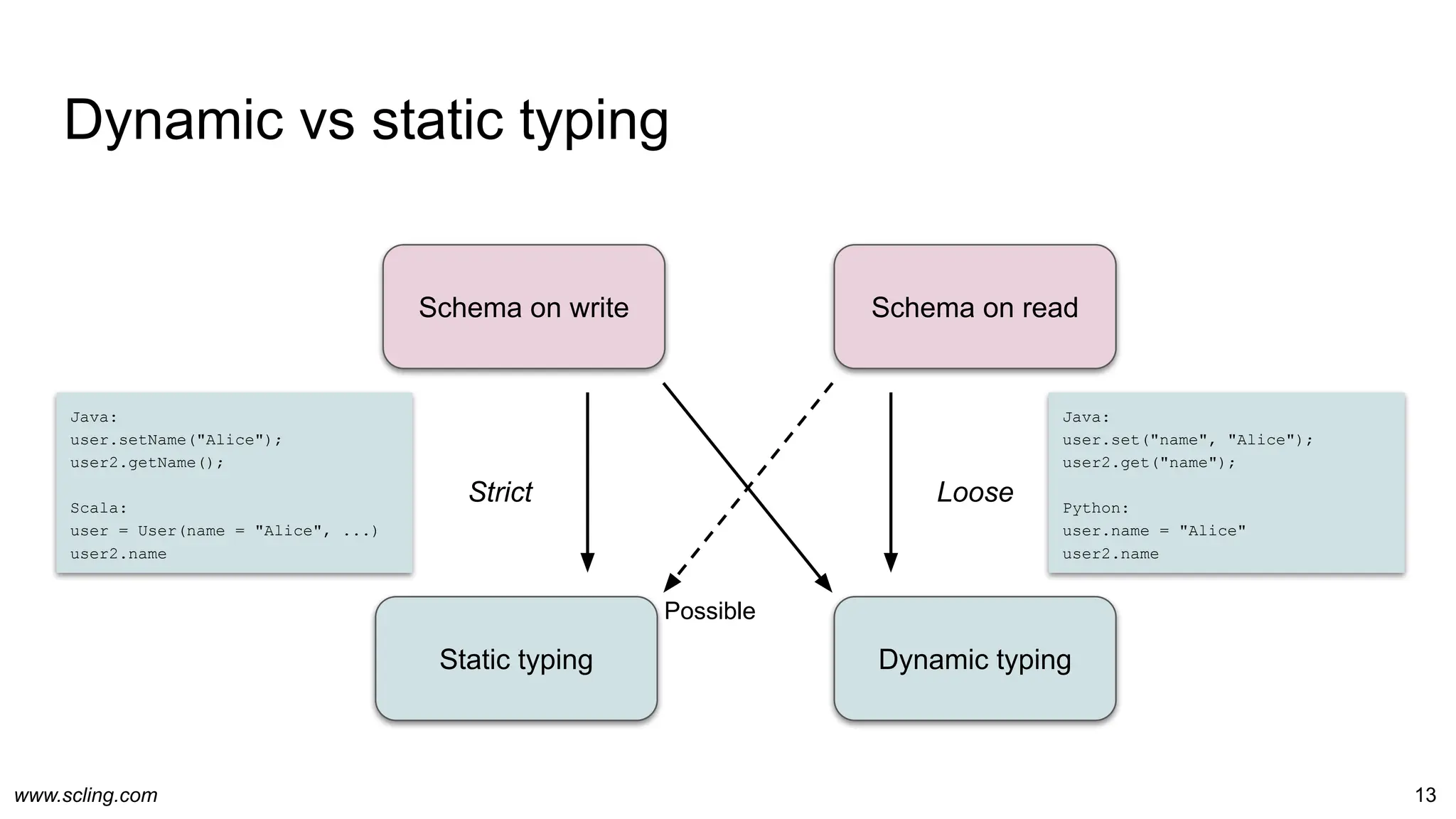
Schema definitions
10
{
"type" : "record",
"namespace" : "com.mapflat.example",
"name" : "User",
"fields" : [
{ "name" : "id" , "type" : "int" },
{ "name" : "name" , "type" : "string" },
{ "name" : "age" , "type" : "int" },
{ "name" : "phone" , "type" : ["null", "string"],
"default": null }
]
}
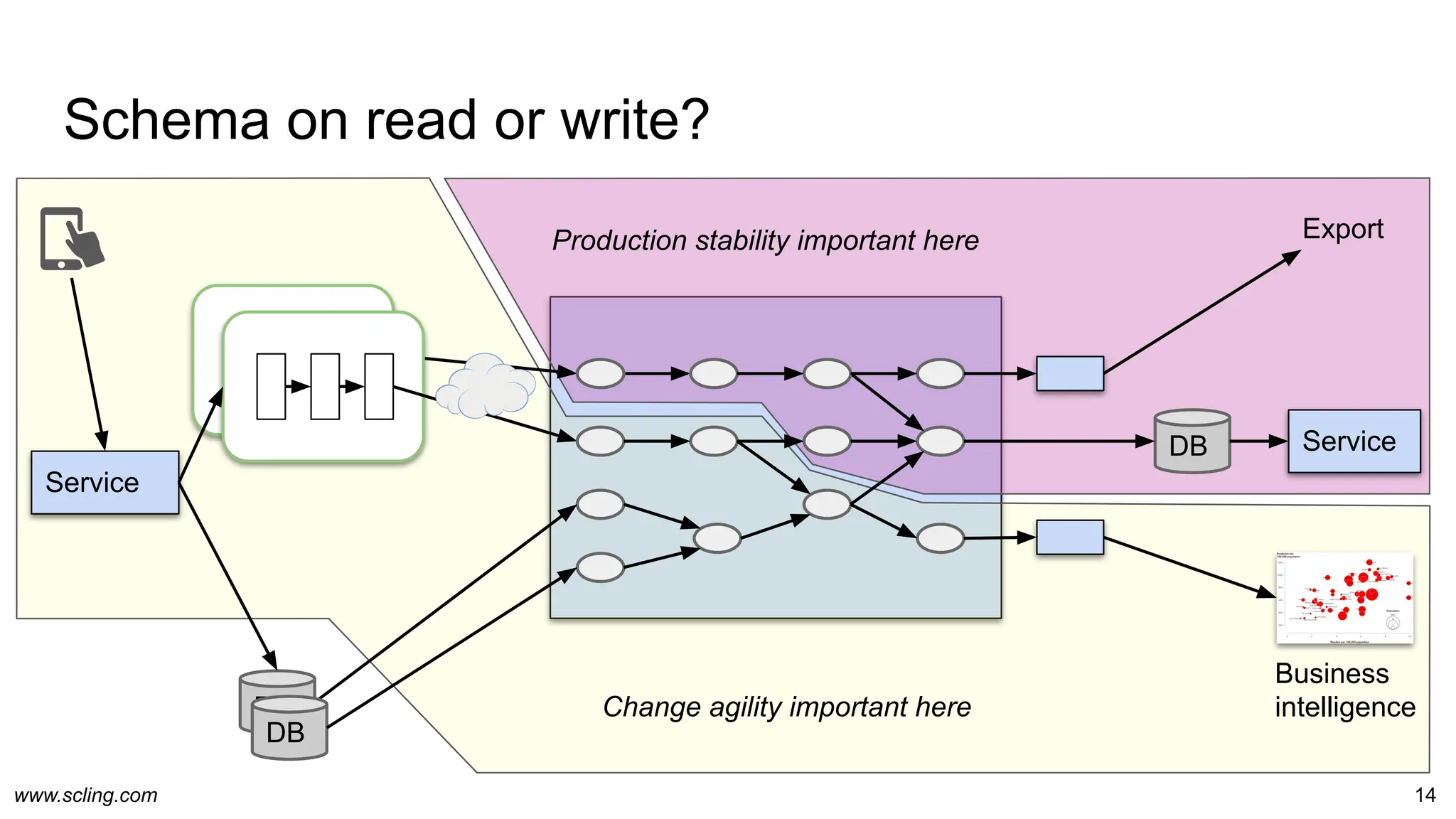
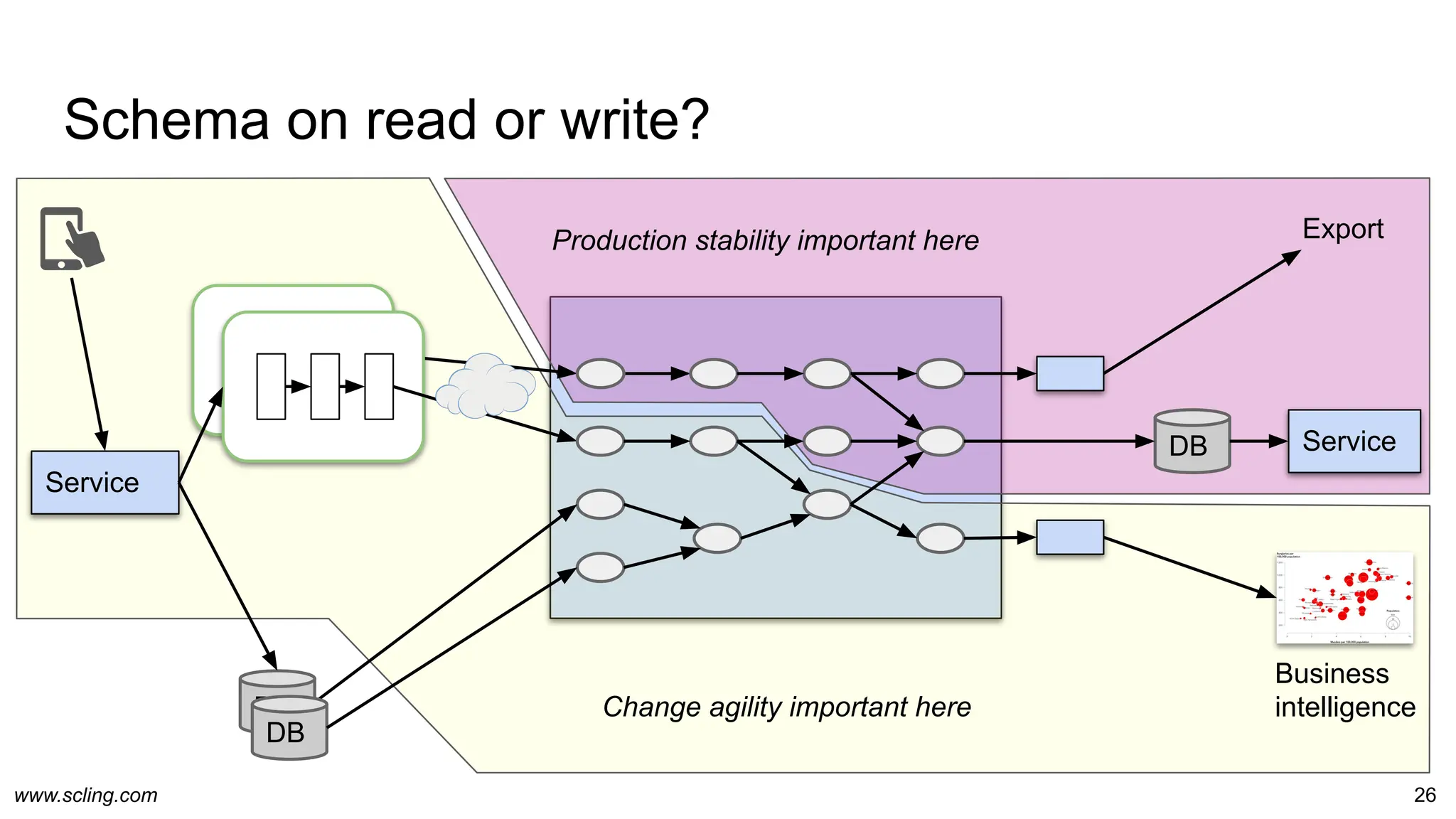
● RDBMS: Table metadata
● Avro format: JSON/DSL definition
○ Definition is bundled with avro data files
○ Reused by Parquet format
● pyschema / dataclass
● Scala case classes
● JSON-schema
● JSON: Each record
○ One record insufficient to deduce schema
{ "id": 1, "name": "Alice", "age": "34" }
{ "id": 1, "name": "Bob", "age": "42", "phone": "08-123456" }
case class User(id: String, name: String, age: Int,
phone: Option[String] = None)
val users = Seq( User("1", "Alice", 32),
User("2", "Bob", 43, Some("08-123456")))](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-10-2048.jpg)


![www.scling.com
● Expressive
● Custom types
● IDE support
● Avro for data lake storage
Schema definition choice
15
● RDBMS: Table metadata
● Avro: JSON/DSL definition
○ Definition is bundled with avro data files
● Parquet
● pyschema / dataclass
● Scala case classes
● JSON-schema
● JSON: Each record
○ One record insufficient to deduce schema
case class User(id: String, name: String, age: Int,
phone: Option[String] = None)
val users = Seq( User("1", "Alice", 32),
User("2", "Bob", 43, Some("08-123456")))](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-15-2048.jpg)
![www.scling.com
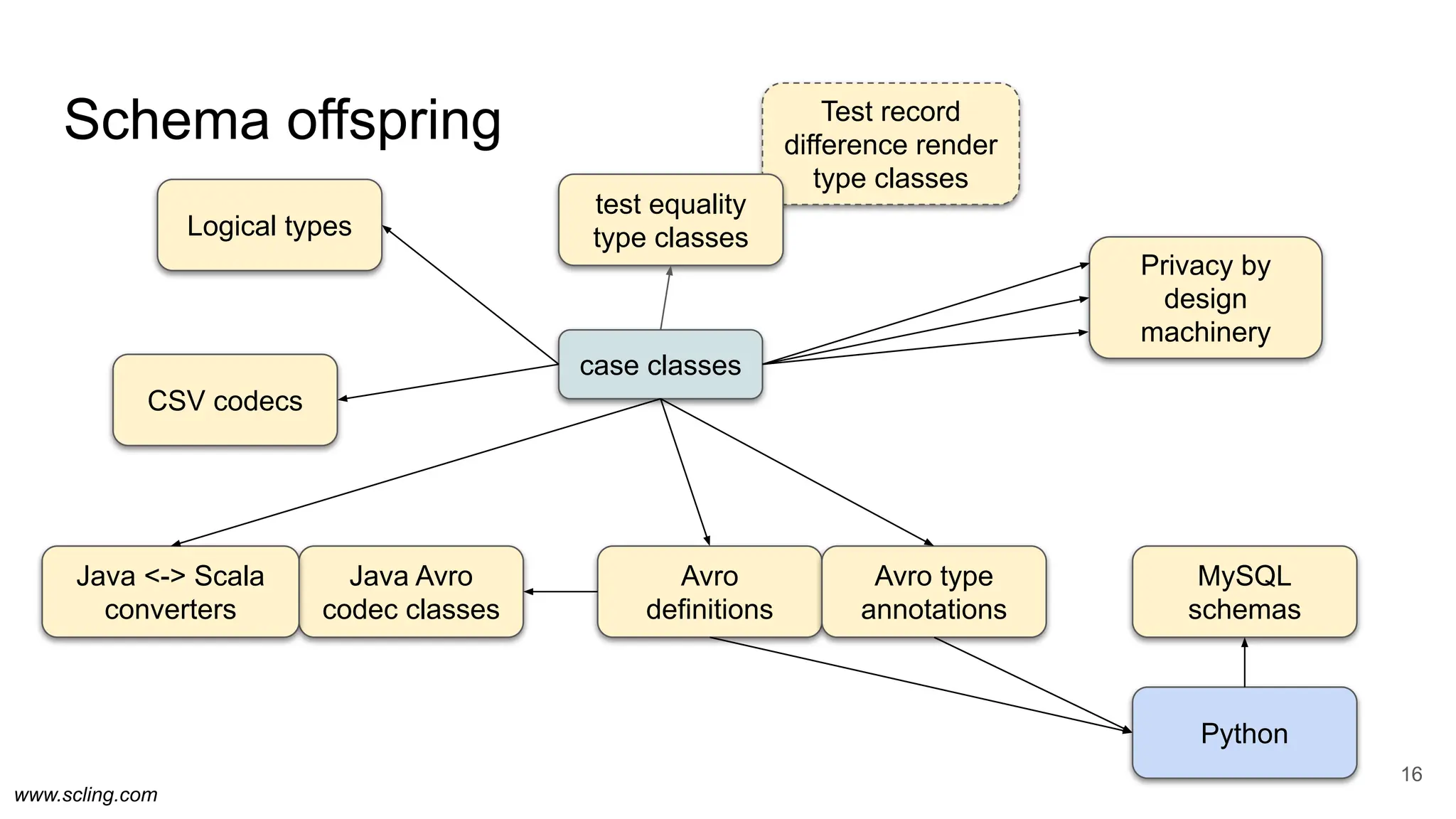
Avro codecs
17
case classes
Avro
definitions
Java Avro
codec classes
Java <-> Scala
converters
{
"name": "JavaUser",
{ "name": "age", "type": "int" }
{ "name": "phone", "type": [ "null", "string" ] }
}
public class JavaUser implements SpecificRecord {
public Integer getAge() { ... }
public String getPhone() { ... }
}
object UserConverter extends AvroConverter[User] {
def fromSpecific(u: JavaUser): User
def toSpecific(u: User): JavaUser
}
case class User(age: Int,
phone: Option[String] = None)](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-17-2048.jpg)
![www.scling.com
Scalameta
● Parsing and analysis of scala
source code
18
val a = b() + 3
["val", " ", "a", " ", "=", " ", "b",
"(", ")", " ", "+", " ", "3"]
[val, "a", =, Call("b"), +, Int(3)]
[val, Int(a), =,
Call(com.scling.func.b), +, Int(3)]
lex
parse
semantic
analysis](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-18-2048.jpg)

![www.scling.com
Schema & syntax tree
20
Defn.Class(
List(Mod.Annot(Init(Type.Name("PrivacyShielded"), , List())), case),
Type.Name("SaleTransaction"),
List(),
Ctor.Primary(
List(),
,
List(
List(
Term.Param(
List(Mod.Annot(Init(Type.Name("PersonalId"), , List()))),
Term.Name("customerClubId"),
Some(Type.Apply(Type.Name("Option"), List(Type.Name("String")))),
None
),
Term.Param(
List(Mod.Annot(Init(Type.Name("PersonalData"), , List()))),
Term.Name("storeId"),
Some(Type.Apply(Type.Name("Option"), List(Type.Name("String")))),
None
),
Term.Param(
List(),
Term.Name("item"),
Some(Type.Apply(Type.Name("Option"), List(Type.Name("String")))),
None
),
Term.Param(List(), Term.Name("timestamp"), Some(Type.Name("String")), None)
)
)
),
Template(List(), List(), Self(, None), List()))
@PrivacyShielded
case class SaleTransaction(
@PersonalId customerClubId: Option[String],
@PersonalData storeId: Option[String],
item: Option[String],
timestamp: String
)](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-20-2048.jpg)
![www.scling.com
Quasiquotes
21
val stat: Stat = "val a = b() + 3".parse[Stat].get
val stat: Stat = q"val a = b() + 3"](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-21-2048.jpg)
![www.scling.com
Quasiquotes in practice
22
q"""
object $converterName extends AvroConverter[${srcClass.clazz.name}
] {
import RecordFieldConverters._
type S = $jClassName
def schema: Schema = $javaClassTerm.getClassSchema()
def tag: ClassTag[S] = implicitly[ClassTag[S]]
def datumReader: SpecificDatumReader[S] = new SpecificDatumReader[$jClassName](classOf[$jClassName])
def datumWriter: SpecificDatumWriter[S] = new SpecificDatumWriter[$jClassName](classOf[$jClassName])
def fromSpecific(record: $jClassName): ${srcClass.clazz.name} =
${Term.Name(srcClass.clazz.name.value)}
(..$fromInits )
def toSpecific(record: ${srcClass.clazz.name}
): $jClassName =
new $jClassName(..$specificArgs)
}
"""](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-22-2048.jpg)
![www.scling.com
Test equality Test record
difference render
type classes
23
case classes
test equality
type classes
trait REquality[ T] { def equal(value: T, right: T): Boolean }
object REquality {
implicit val double: REquality[Double] = new REquality[Double] {
def equal(left: Double, right: Double): Boolean = {
// Use a combination of absolute and relative tolerance
left === right +- 1e-5.max(left.abs * 1e-5).max(right.abs * 1e-5)
}
}
/** binds the Magnolia macro to the `gen` method */
implicit def gen[T]: REquality[ T] = macro Magnolia. gen[T]
}
object Equalities {
implicit val equalityUser: REquality[User] =
REquality. gen[User]
}](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-23-2048.jpg)
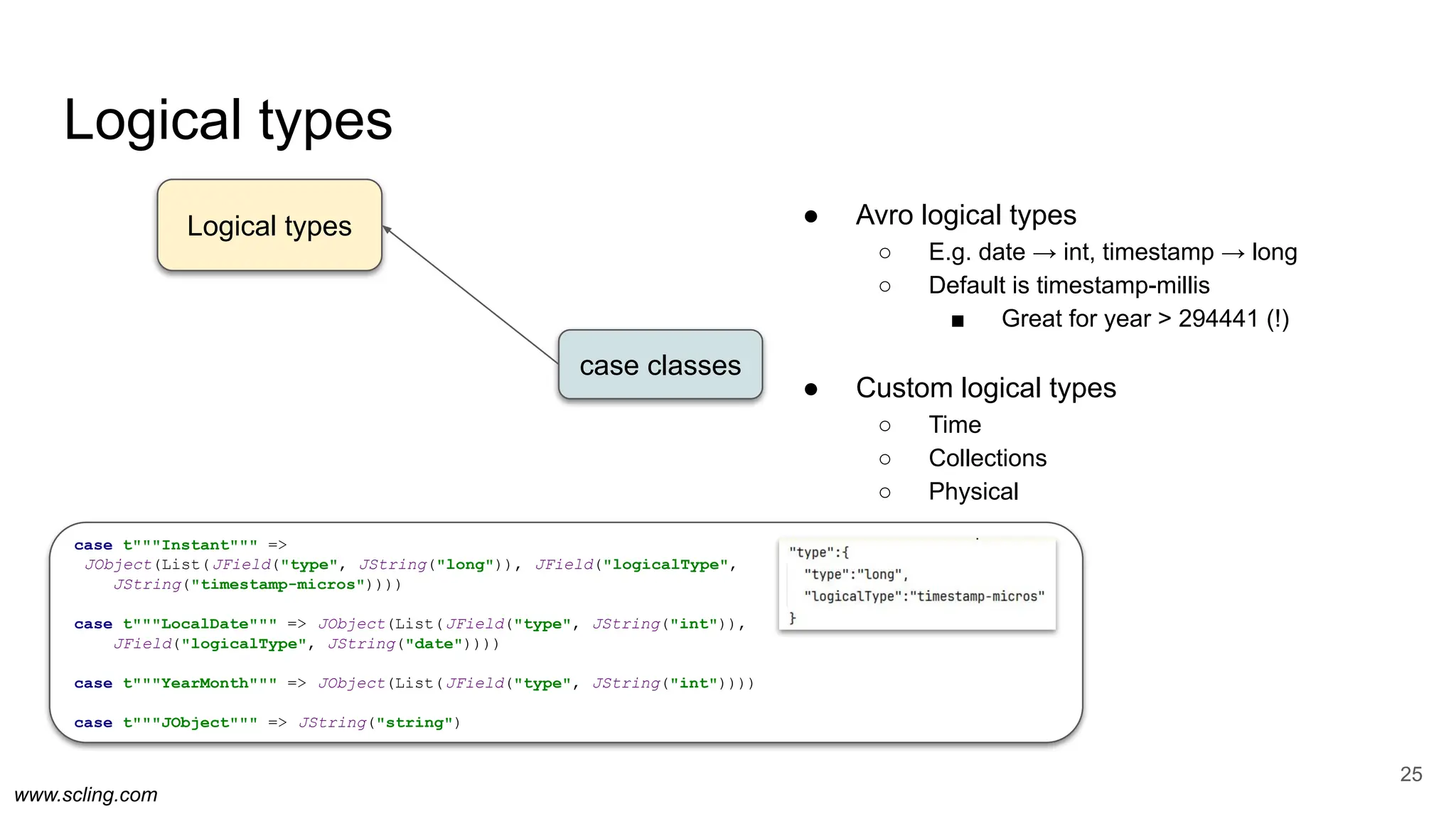
![www.scling.com
case class User(
age: Int,
@AvroProp ("sqlType", "varchar(1012)")
phone: Option[String] = None)
Python + RDBMS
24
case classes
Avro
definitions
Avro type
annotations
MySQL
schemas
Python
{
"name": "User",
{ "name": "age", "type": "int" }
{ "name": "phone",
"type": [ "null", "string" ],
"sqlType": "varchar(1012)",
}
}
class UserEgressJob(CopyToTable):
columns = [
( "age", "int"),
( "name", "varchar(1012)"),
]
...](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-24-2048.jpg)




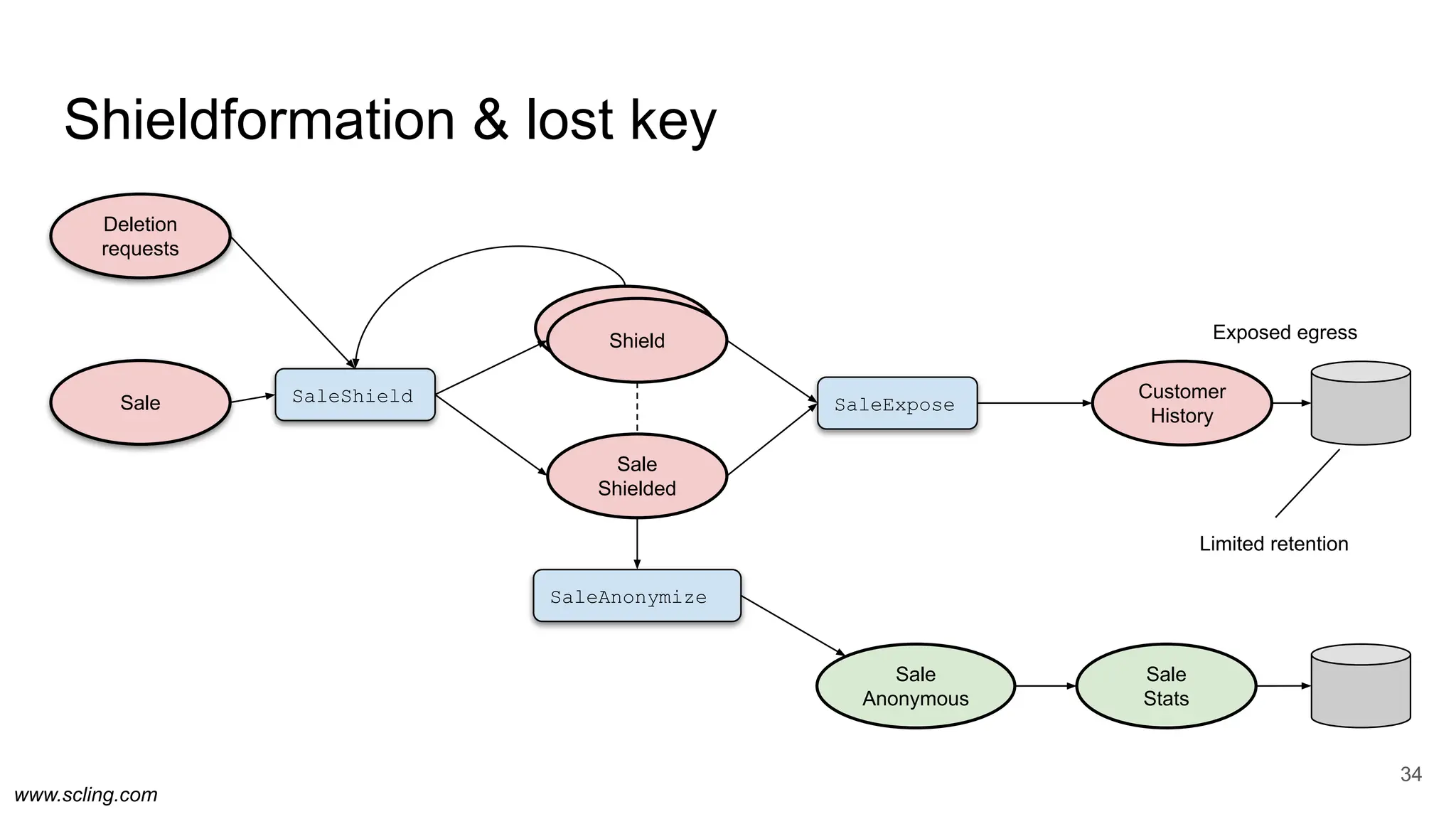
![www.scling.com
Shieldformation
33
@PrivacyShielded
case class Sale(
@PersonalId customerClubId: Option[String],
@PersonalData storeId: Option[String],
item: Option[String],
timestamp: String
)
case class SaleShielded(
shieldId: Option[String],
customerClubIdEncrypted: Option[String],
storeIdEncrypted: Option[String],
item: Option[String],
timestamp: String
)
case class SaleAnonymous(
item: Option[String],
timestamp: String
)
object SaleAnonymize extends SparkJob {
...
}
ShieldForm
object SaleExpose extends SparkJob {
...
}
object SaleShield extends SparkJob {
...
}
case class Shield(
shieldId: String,
personId: Option[String],
keyStr: Option[String],
encounterDate: String
)](https://image.slidesharecdn.com/schemaonreadisobsolete-240427092512-fdb43cf3/75/Schema-on-read-is-obsolete-Welcome-metaprogramming-pdf-33-2048.jpg)
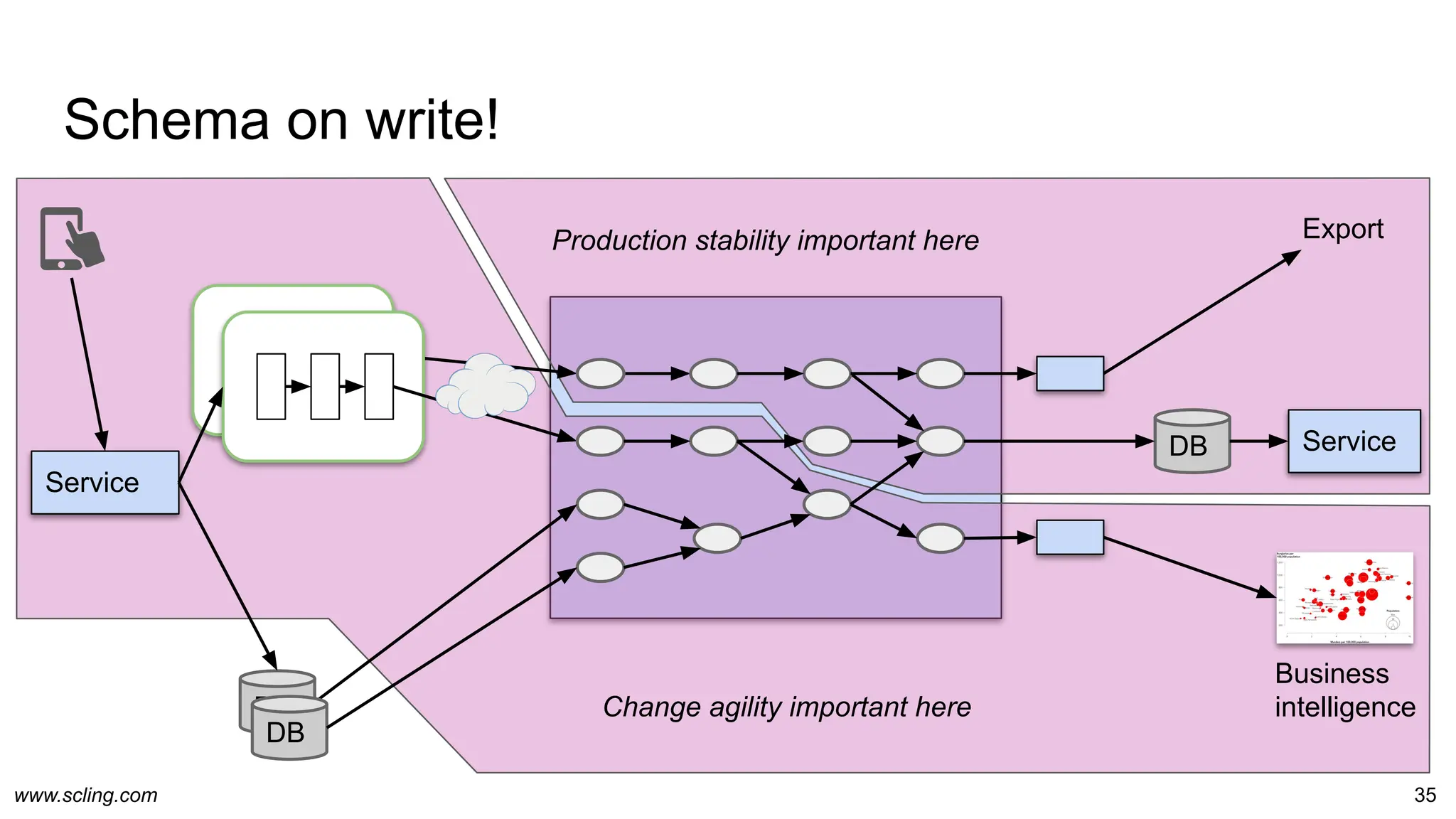
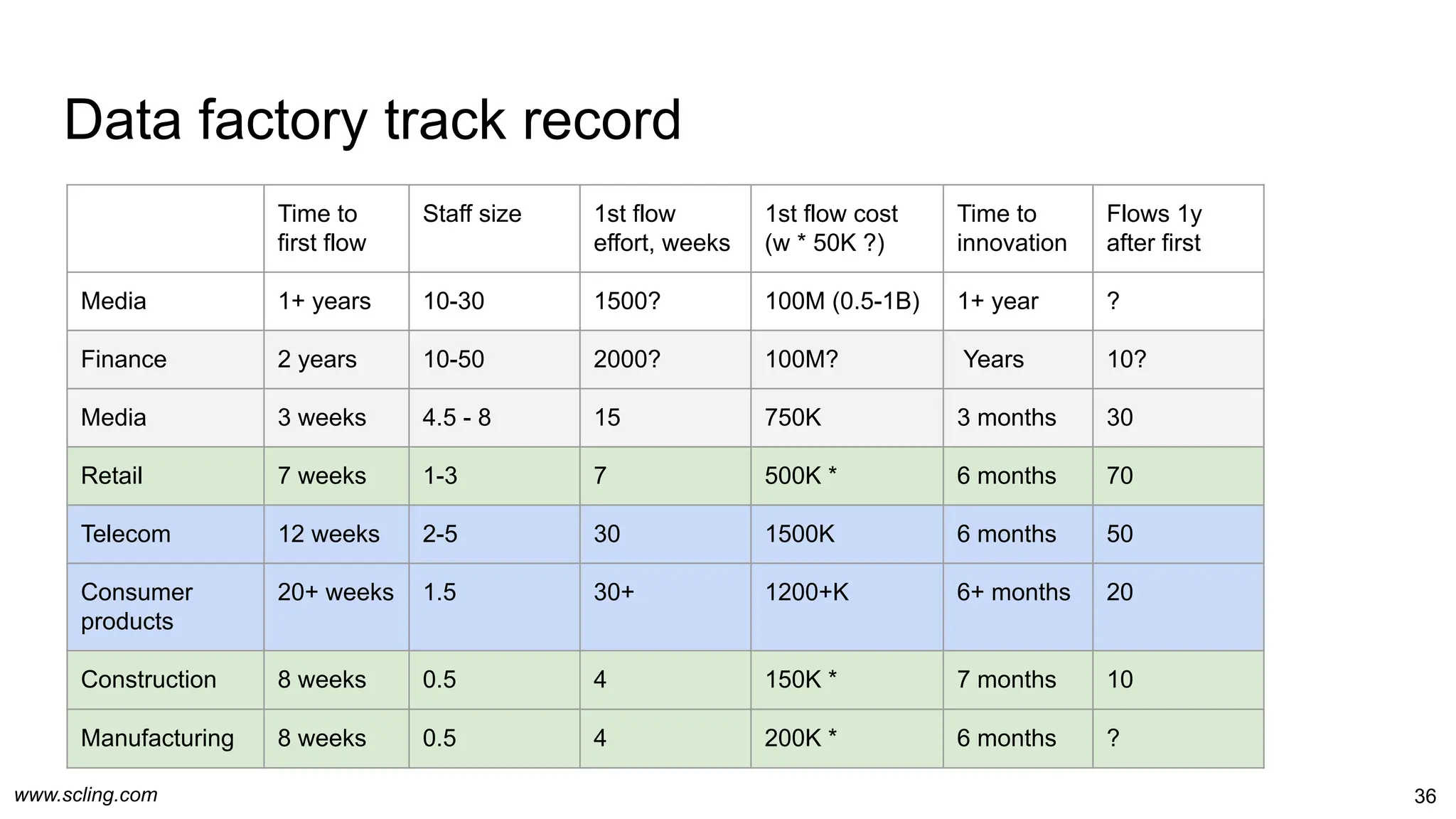

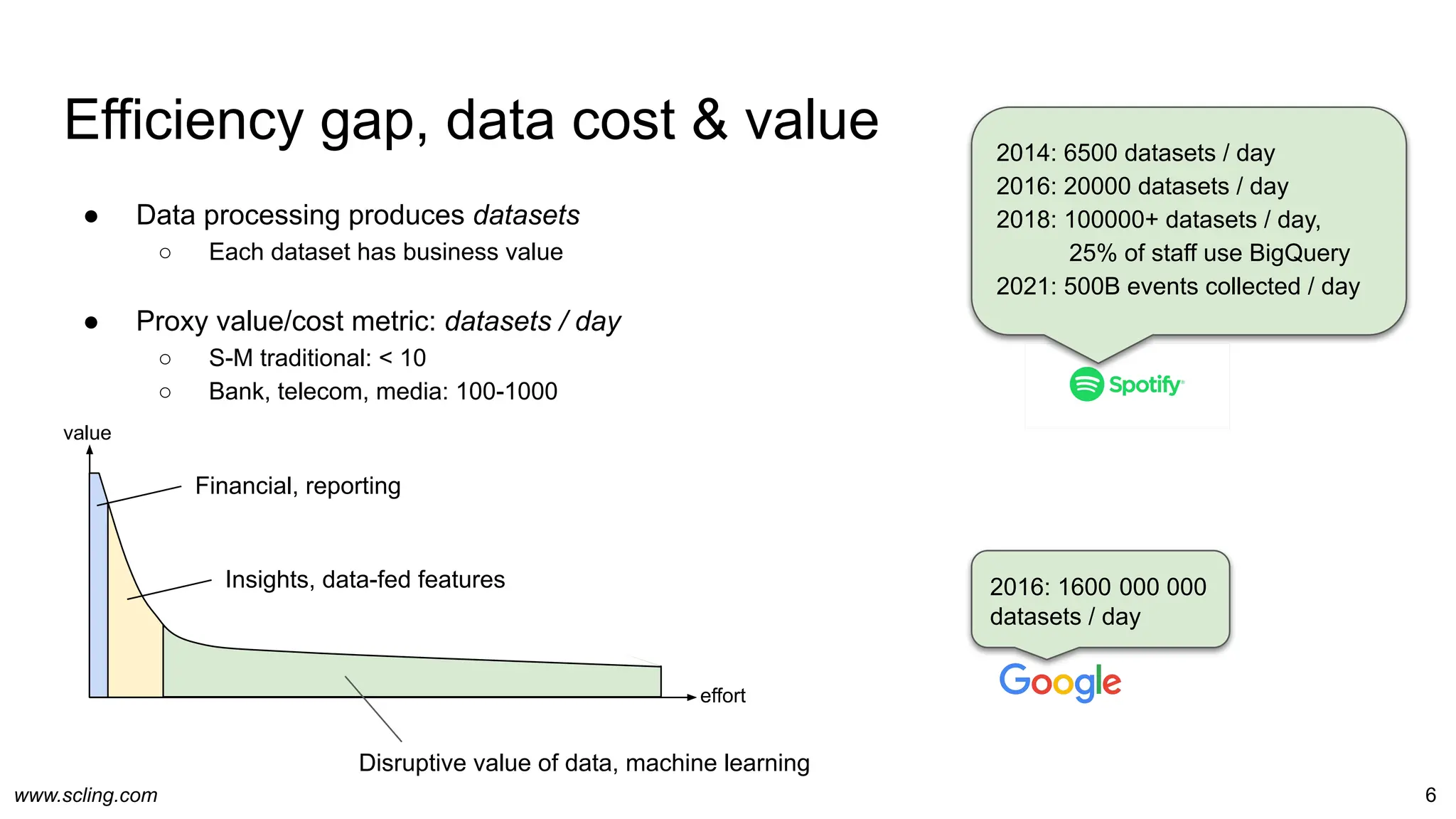
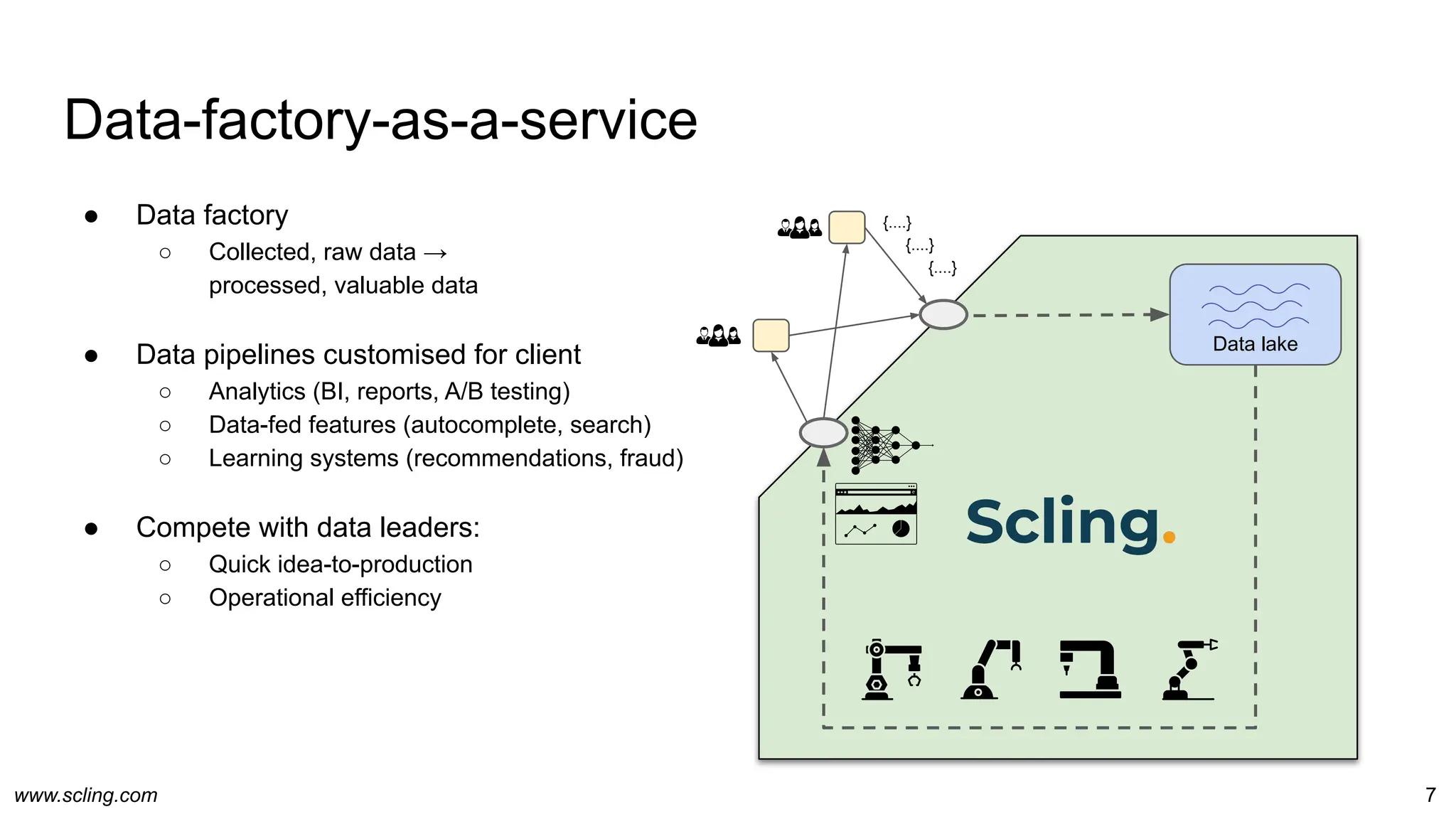
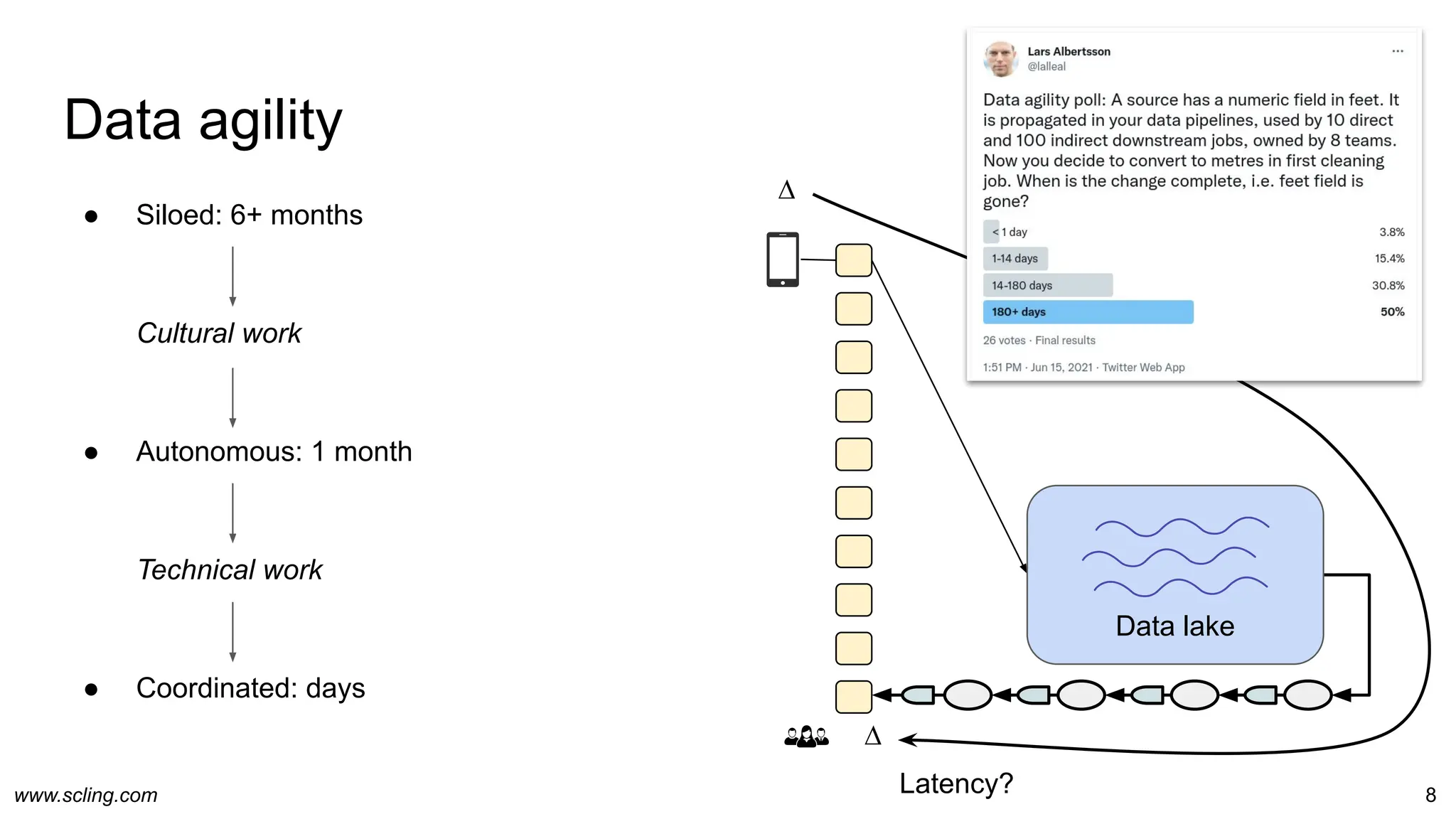
The document discusses the evolution of data engineering, emphasizing the transition from traditional workflows to newer technologies and methodologies like data factories, data pipelines, and schema management. It highlights the importance of data agility, processing efficiency, and the impact of metaprogramming on data operations, while contrasting schema on read and schema on write. Additionally, it touches on privacy considerations and the role of data factories in supporting data processing operations effectively.
















































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)




