Download as PDF, PPTX






![What The API Looks Like
FT.AGGREGATE {index} {query}
[LOAD {len} {property} ...]
[GROUPBY {len} {property} ...
[REDUCE {func} {len} {arg} … [AS {alias}] ]
[SORTBY {len}{property} [ASC|DESC] …[MAX {n}]
[APPLY {expr} AS {alias}]
[LIMIT {offset} {num} ]](https://image.slidesharecdn.com/redisearchaggregations-180327224833/85/Redis-Day-TLV-2018-RediSearch-Aggregations-7-320.jpg)
![Aggregate Filters
● Determine what results we process
● Same query syntax as normal RediSearch queries
● Can be used to create complex selections
@country:{Israel | Italy}
@age:[25 52]
@profession:”1337 h4x0r”
-@languages:{perl | php}](https://image.slidesharecdn.com/redisearchaggregations-180327224833/85/Redis-Day-TLV-2018-RediSearch-Aggregations-8-320.jpg)


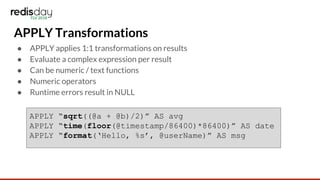

![String Functions and Expressions
● lower(s)
● upper(s)
● substr(s, offset, len)
● format(fmt, …)
● time(unix_timestamp, [fmt])
● parsetime(str, [fmt])](https://image.slidesharecdn.com/redisearchaggregations-180327224833/85/Redis-Day-TLV-2018-RediSearch-Aggregations-13-320.jpg)







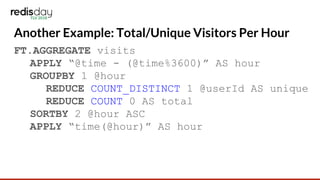

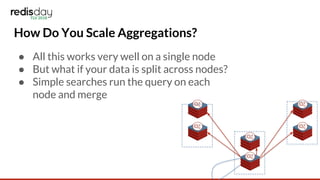






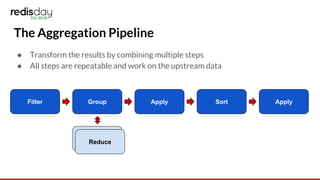
This document discusses RediSearch aggregations, which allow processing search results to produce statistical insights. Aggregations take a search query, group and reduce the results, apply transformations, and sort. Key steps include filtering results, grouping and reducing with functions like count and average, applying expressions, and sorting. Examples show finding top GitHub committers and visits by hour. Scaling aggregations to multiple nodes requires pushing processing stages to nodes and merging results, such as summing counts or taking list intersections.



















![TypoScript and EEL outside of Neos [InspiringFlow2013]](https://cdn.slidesharecdn.com/ss_thumbnails/typoscriptandeel-130420043915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































































