Download to read offline









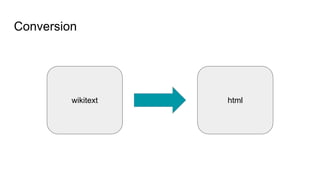
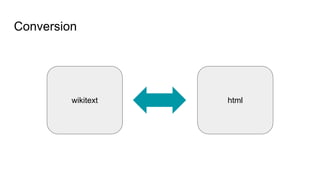
![Wikitext
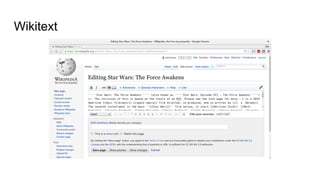
= Star Wars: The Force Awakens =
Star Wars: The Force Awakens is a 2015 American epic space opera
film directed, co-produced, and co-written by [[J. J. Abrams]].](https://image.slidesharecdn.com/wikimediacontentapi-160510171625/85/Wikimedia-Content-API-A-Cassandra-Use-case-11-320.jpg)

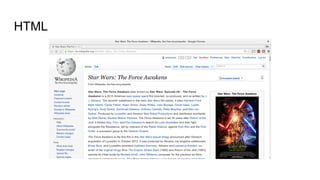

![Metadata
[[Foo|bar]]
<a rel="mw:WikiLink" href="./Foo">bar</a>](https://image.slidesharecdn.com/wikimediacontentapi-160510171625/85/Wikimedia-Content-API-A-Cassandra-Use-case-19-320.jpg)
![Metadata
[[Foo|{{echo|bar}}]]
<a rel="mw:WikiLink" href="./Foo">
<span about="#mwt1" typeof="mw:Object/Template"
data-parsoid="{...}" >bar</span>
</a>](https://image.slidesharecdn.com/wikimediacontentapi-160510171625/85/Wikimedia-Content-API-A-Cassandra-Use-case-20-320.jpg)


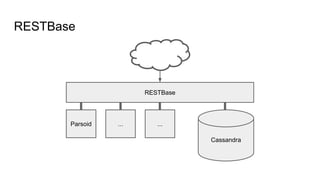





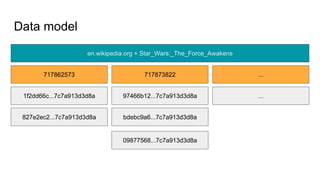

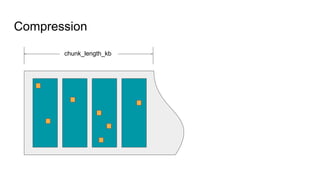
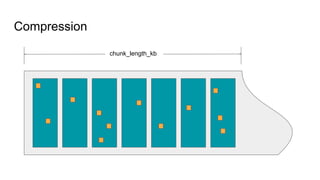





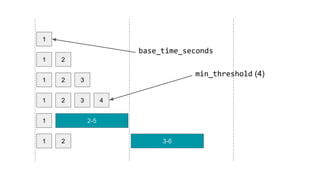




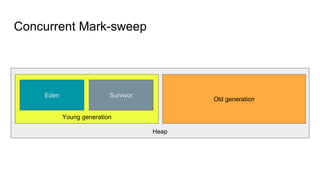
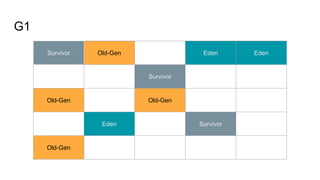











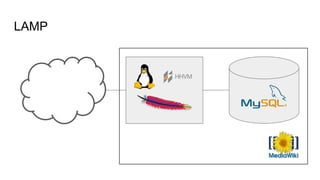
The document presents an overview of Wikimedia's content API and its utilization of Cassandra as a database solution. It details the architectural framework of Wikimedia, including the use of Parsoid and Restbase, and highlights various data management strategies, including compression and compaction techniques. Additionally, it discusses challenges faced in scaling and managing the Cassandra environment and emphasizes the project's commitment to optimizing performance and fault tolerance.
















































![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















