Download as PDF, PPTX
















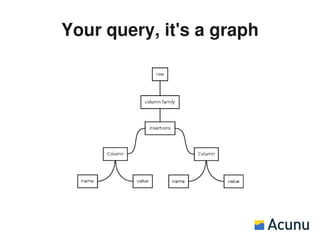





















This document discusses CQL, the Cassandra Query Language. CQL is designed to be similar to SQL but with some differences to account for Cassandra's data model. The presentation provides an overview of CQL's syntax and capabilities, discusses why CQL was created to provide a more stable interface than Cassandra's native protocol, and analyzes CQL's performance compared to the native protocol. Future roadmap items for CQL are also presented, including prepared statements and custom transports. Available CQL drivers for languages like Java, Python, Ruby, and Node.js are also briefly mentioned.






















![[231] the simplicity of cluster apps with circuit](https://cdn.slidesharecdn.com/ss_thumbnails/213thesimplicityofclusterappswithcircuit-150915022150-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)









































































