Downloaded 19 times



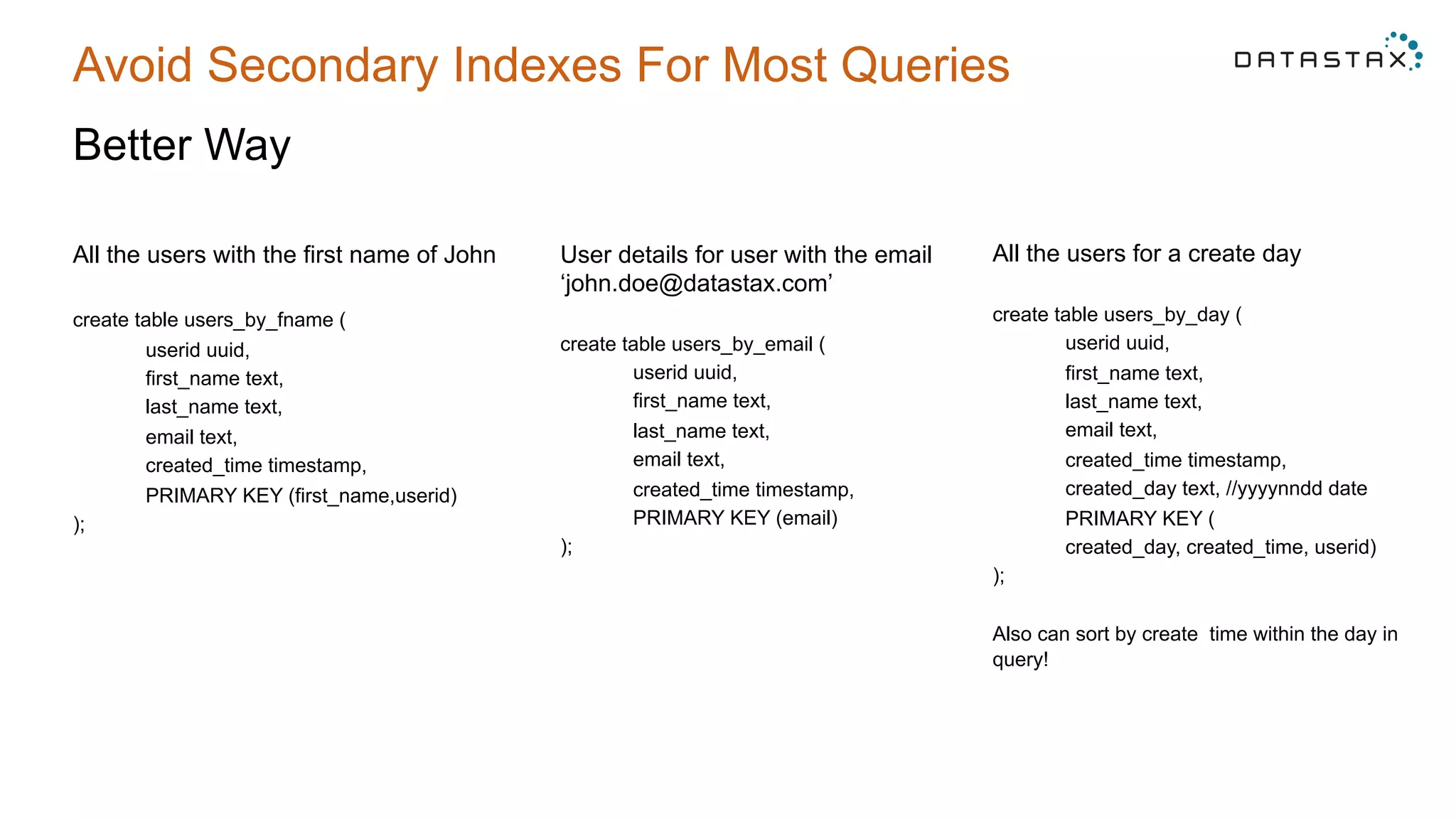



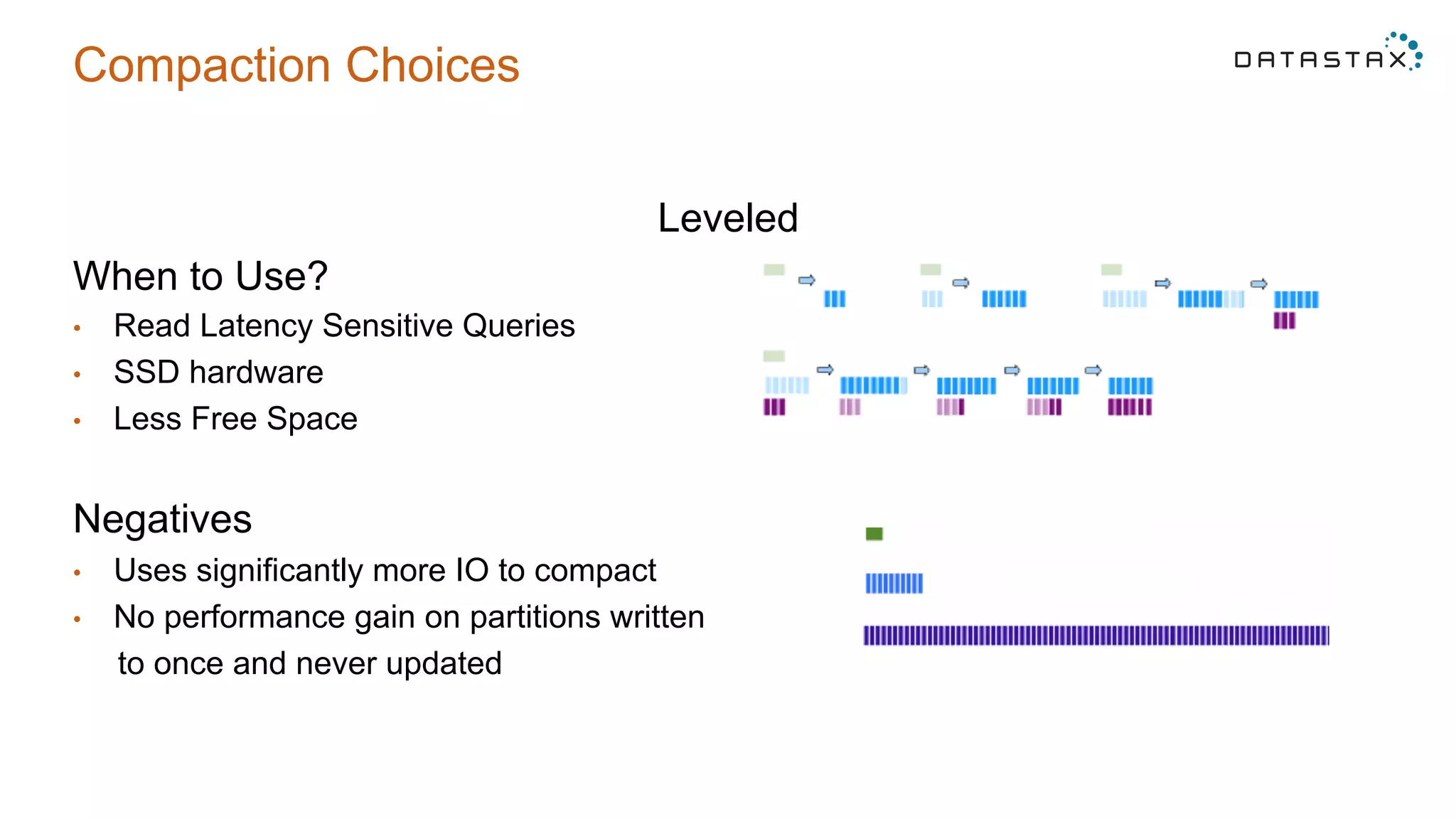
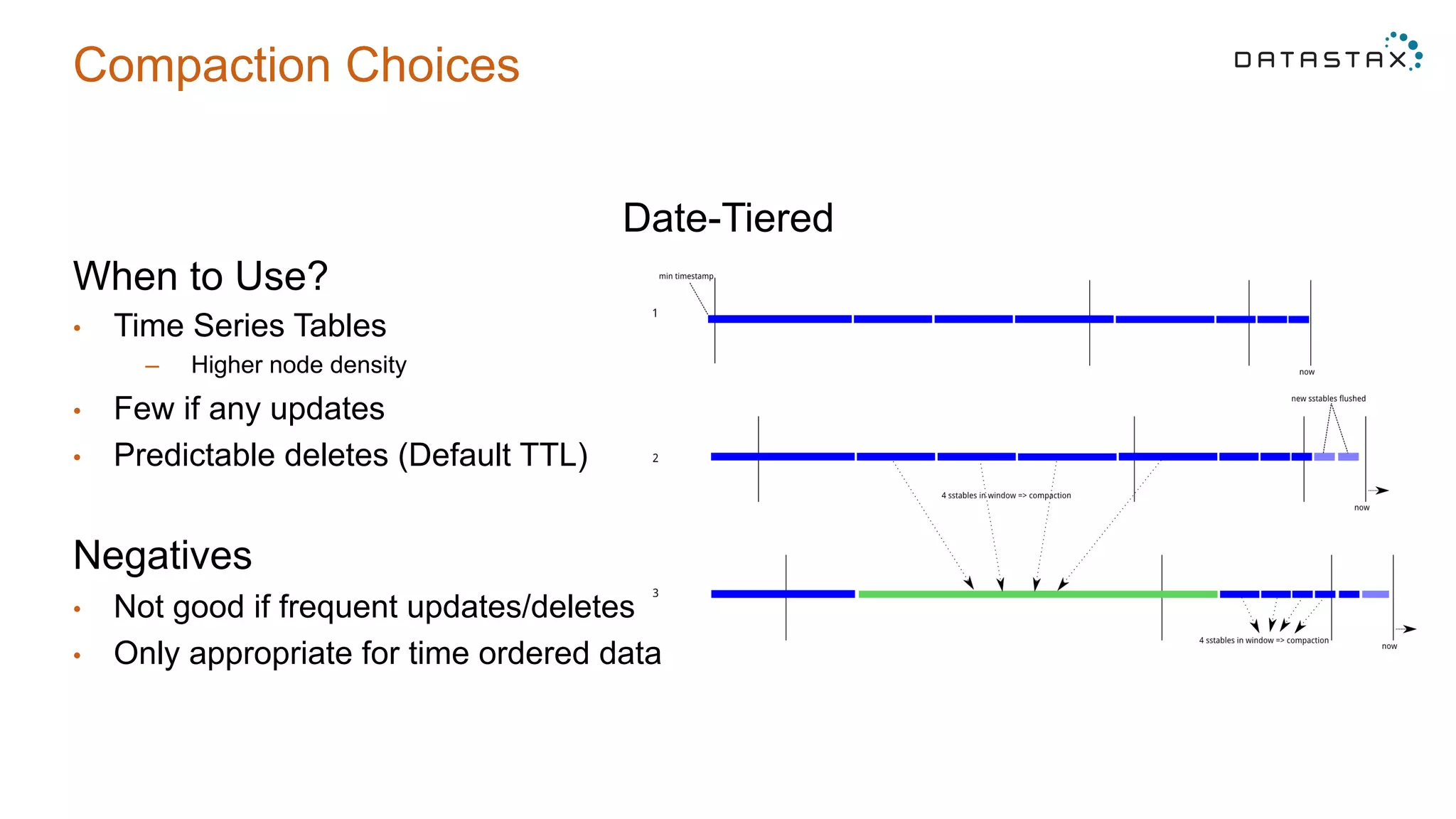












The document provides 5 tips for using Cassandra and DSE: 1) Data modeling best practices to avoid secondary indexes, 2) Understanding compaction choices like size-tiered, leveled, and date-tiered and their use cases, 3) Common mistakes in proofs-of-concept like testing on different hardware and empty nodes, 4) Hardware recommendations like using moderate sized nodes with SSDs, and 5) Anti-patterns like loading large batches of data and modeling queues with improper partitioning.







































![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)







