Downloaded 33 times









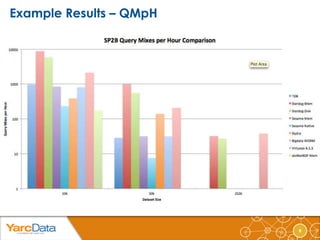
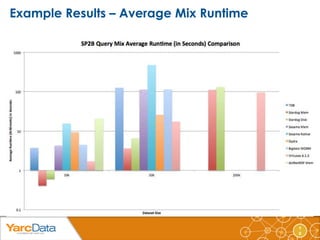
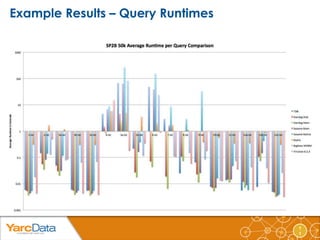



The document discusses the importance of benchmarking various data storage technologies, emphasizing the need for performance evaluation regardless of the technology used. It reviews several benchmarks, such as the Berlin SPARQL Benchmark and Lehigh University Benchmark, while highlighting a lack of standardized methodologies and transparency in performance measurements. Additionally, it introduces a configurable Java command line tool for benchmarking SPARQL queries, which provides various performance metrics.





































![[Uruguay] DB2 Web Query for i - Hernando Bedoya](https://cdn.slidesharecdn.com/ss_thumbnails/db2webquery-111121131455-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































