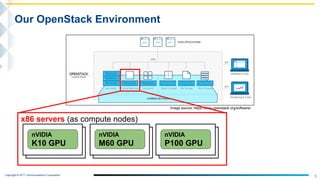
Download to read offline








![Copyright © NTT Communications Corporation.
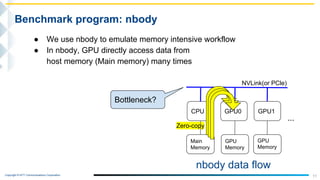
- nbody is kind of cuda sample program.
- This program can calculate single precision and double precision by
using GPU and the results are displayed in GFLOPS.
- It can be also calculated by CPU only.
10
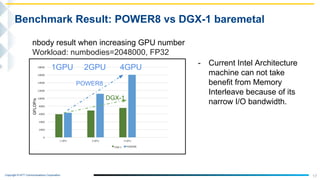
Benchmark program: nbody
$ ./nbody -benchmark -numbodies=2048000 -numdevices=1
-benchmark : (run benchmark to measure performance)
-numbodies : (number of bodies (>= 1) to run in simulation)
(for GPU benchmark:2048000, for CPU benchmark:20480)
-numdevice : (where i=(number of CUDA devices > 0) to use for simulation)
-cpu : (run n-body simulation on the CPU)]
-fp64 : (use double precision floating point values for simulation)](https://image.slidesharecdn.com/powerinteg-180529044718/85/Can-we-boost-more-HPC-performance-Integrate-IBM-POWER-servers-with-GPUs-to-OpenStack-Environment-11-320.jpg)






![Copyright © NTT Communications Corporation.
24
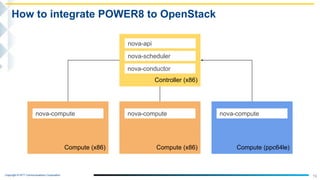
How to integrate POWER8 to OpenStack
● Nova Configuration
○ Compute node
■ Ensure PCI device id
● $ lspci -nn | grep -i nvidia
0002:01:00.0 3D controller [0302]: NVIDIA Corporation Device [10de:15f9] (rev a1)
■ nova.conf
● [default]
pci_passthrough_whitelist={"vendor_id":"10de","product_id":"15f9"}
○ Controller node
■ nova.conf
● [default]
pci_alias= {"vendor_id":"10de", "product_id":"15f9", "name": "P100"}
● [filter_scheduler]
enabled_filters = …,PciPassthroughFilter](https://image.slidesharecdn.com/powerinteg-180529044718/85/Can-we-boost-more-HPC-performance-Integrate-IBM-POWER-servers-with-GPUs-to-OpenStack-Environment-25-320.jpg)


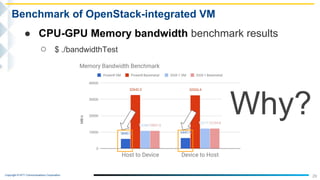
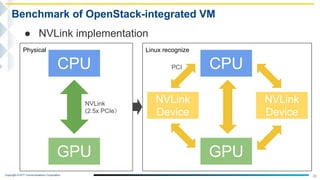
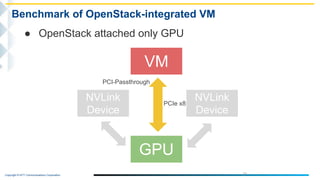
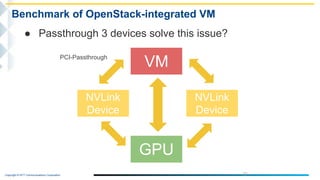



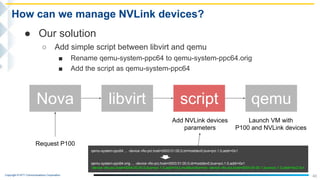






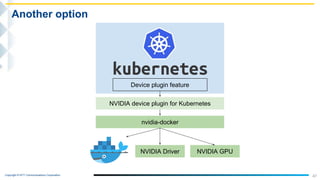

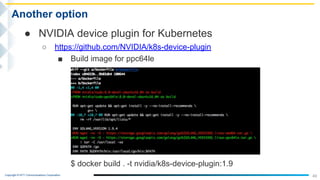


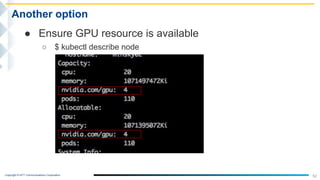
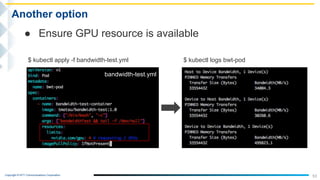
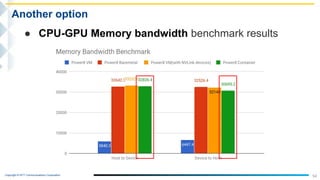



This document outlines the integration of IBM Power servers with GPUs into an OpenStack environment to enhance performance in high-performance computing. It details the motivation, methodology, and benchmark results of using Power8 architecture compared to traditional Intel systems, highlighting significant performance improvements through features like memory interleave. The presentation includes technical specifications and practical steps for implementing this integration in a cloud infrastructure.






















































































