Download as PDF, PPTX







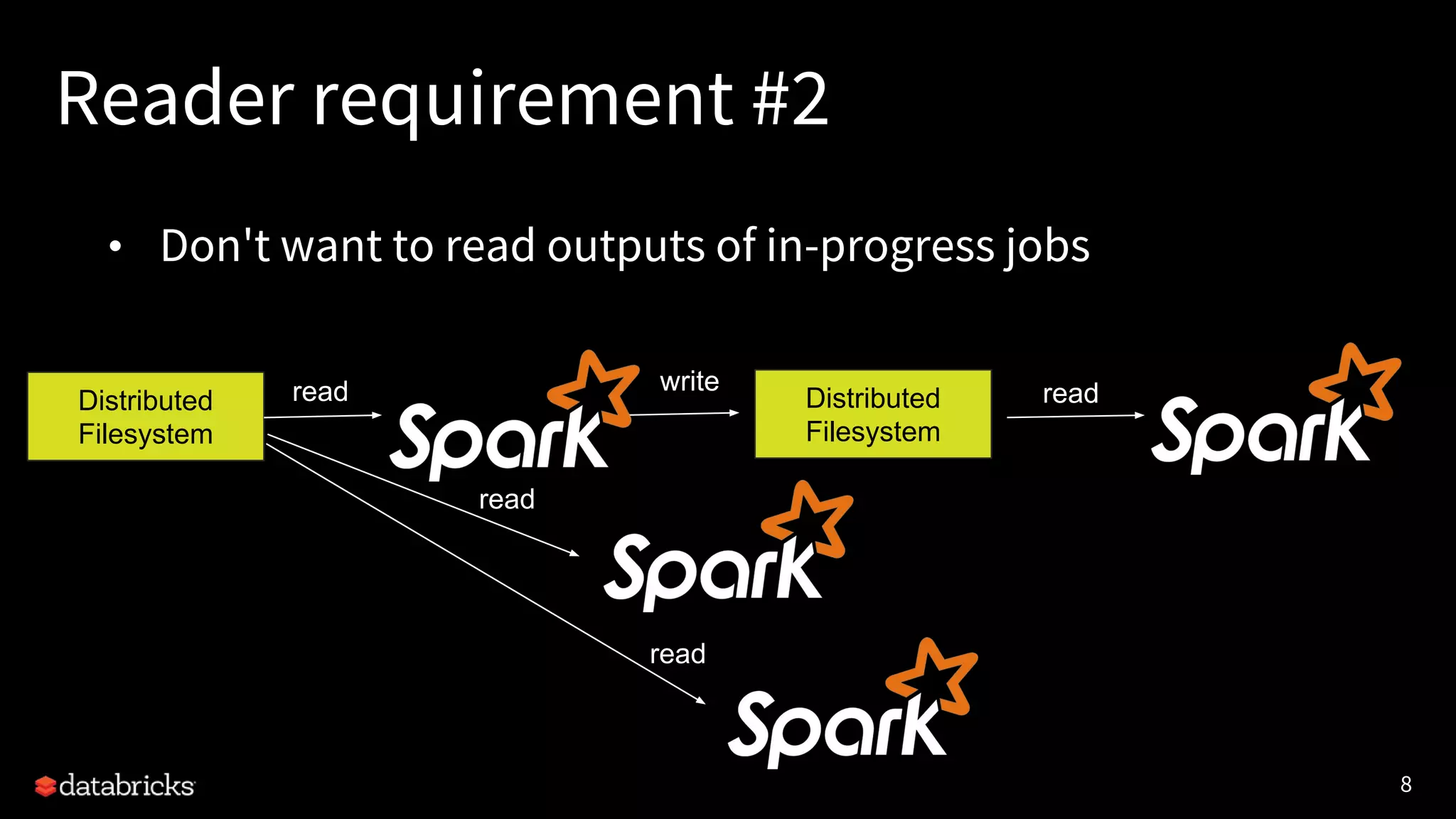

















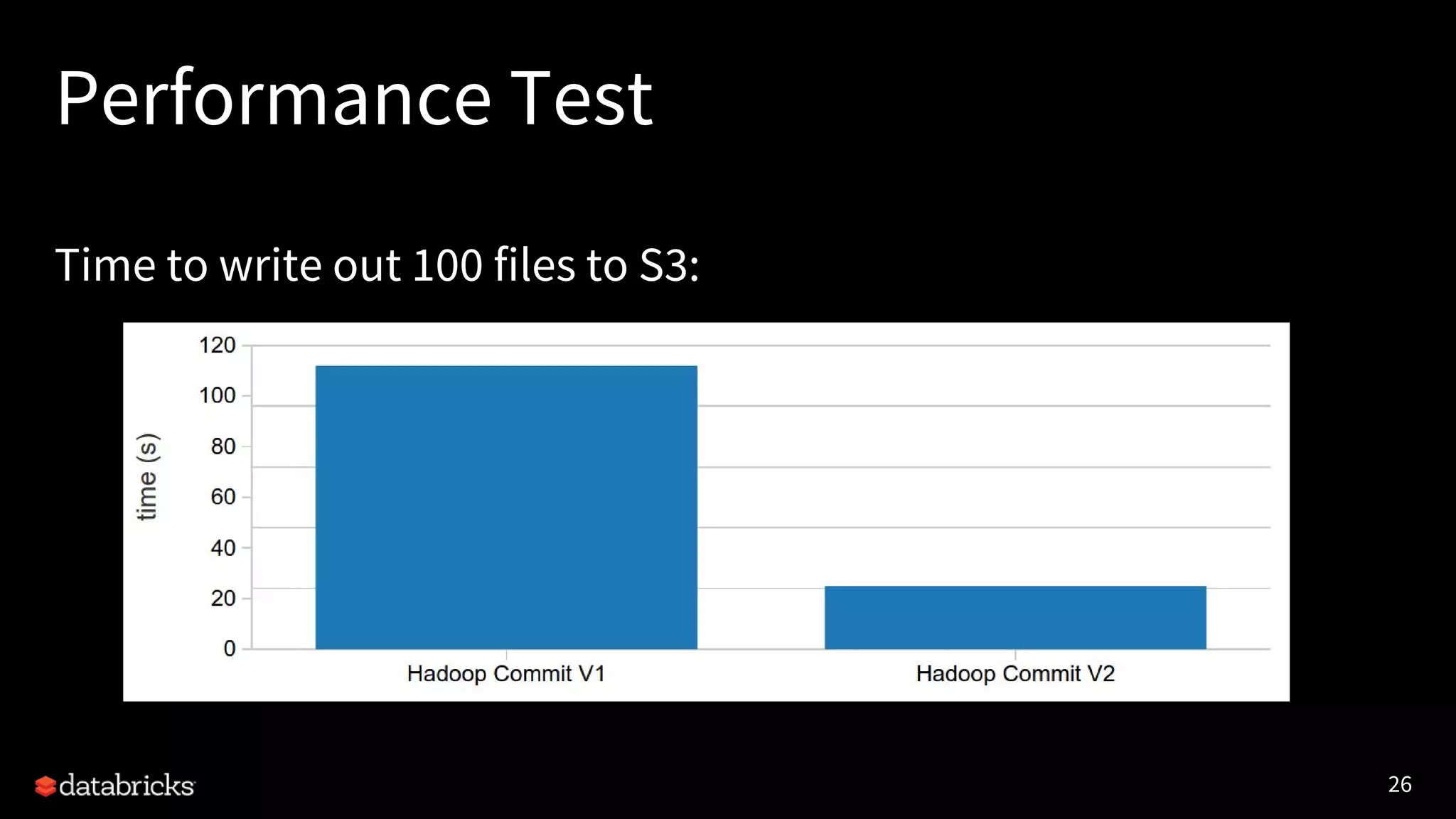

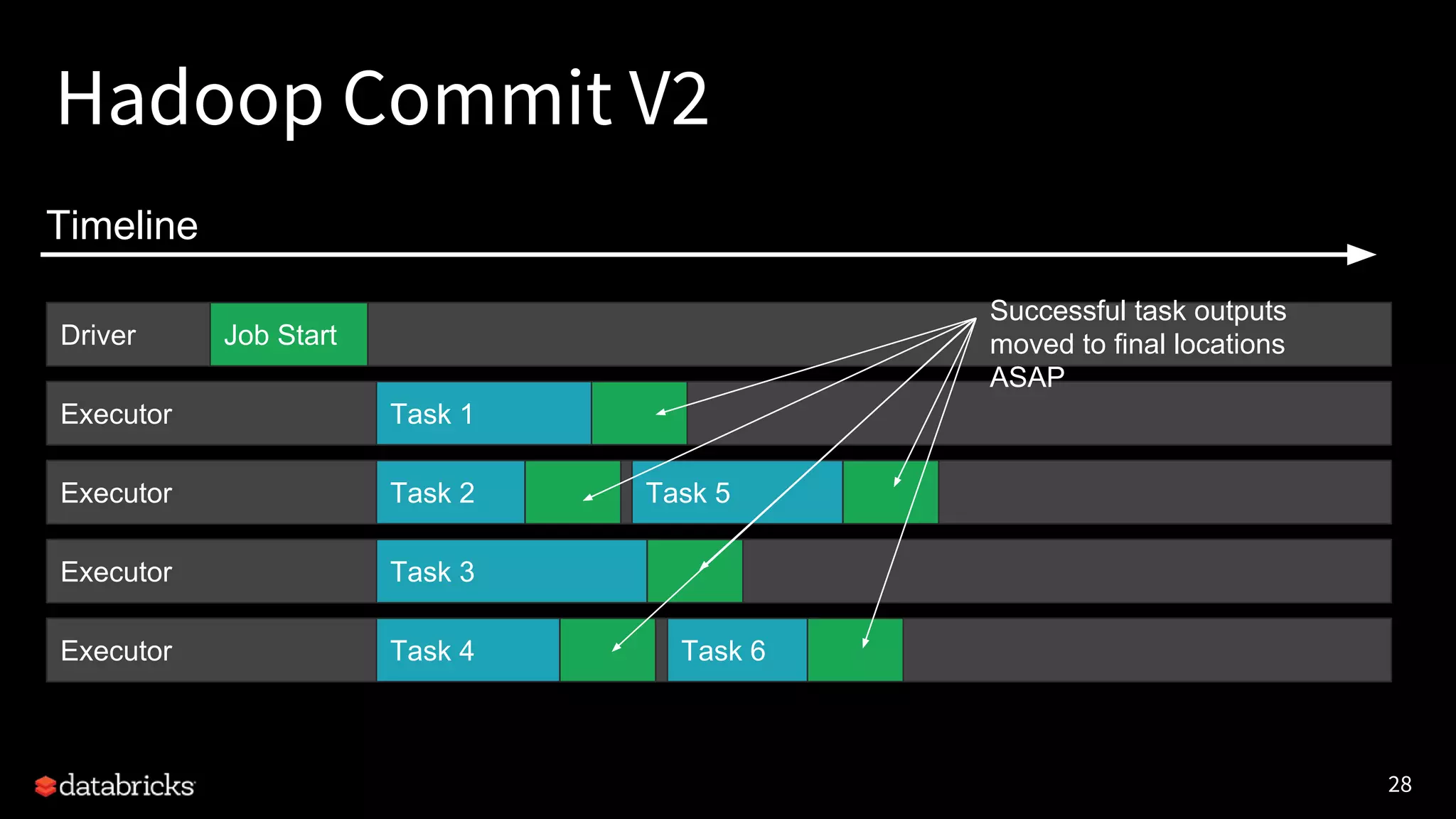



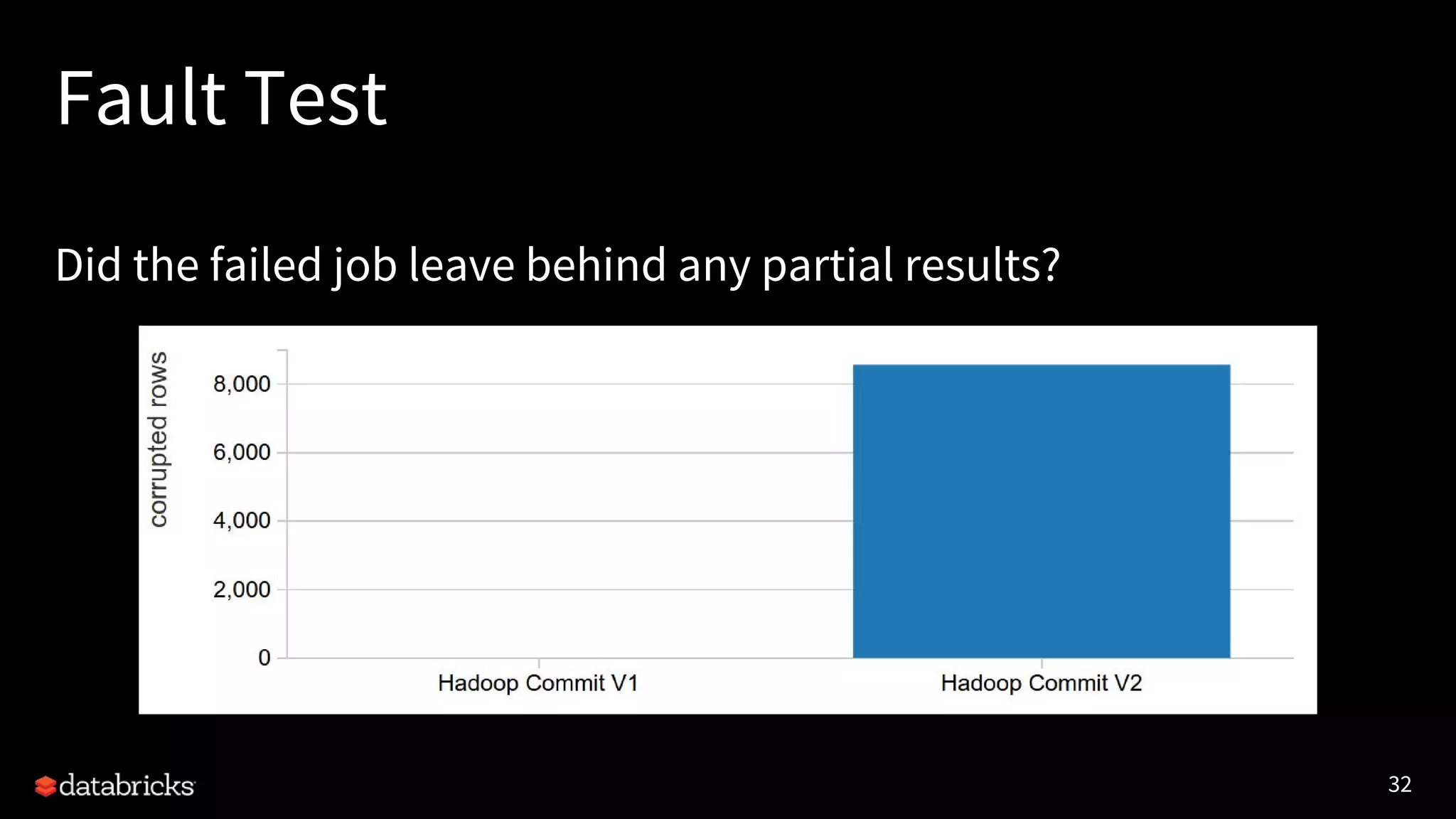











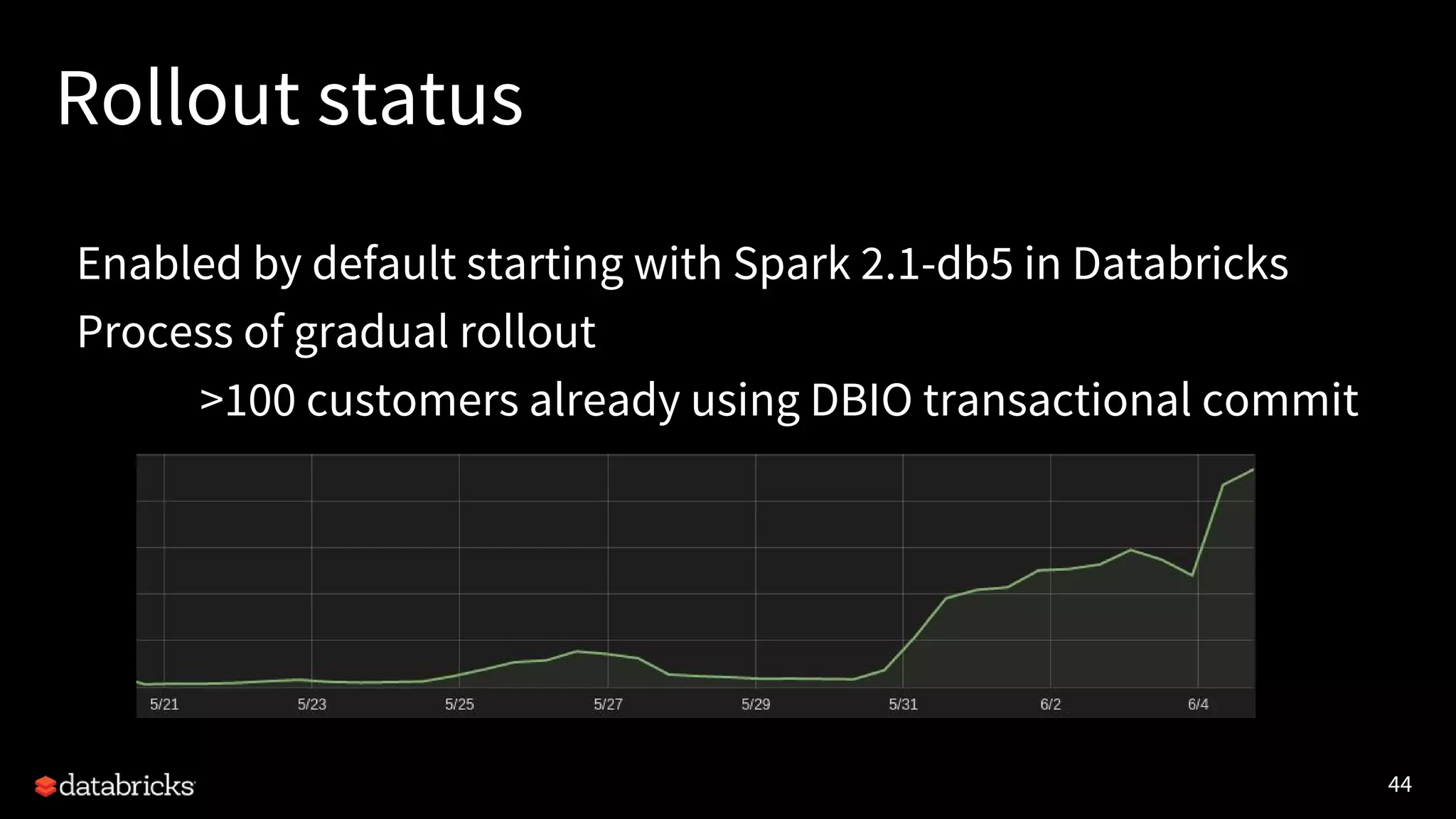



The document discusses the challenges and requirements for writing data to cloud storage using Apache Spark, particularly focusing on transactional writes. It highlights the limitations of traditional Hadoop commit protocols when applied to cloud storage and introduces Databricks' new DBIO transactional commit protocol, which aims to provide strong transactionality without compromising performance. The document concludes that while cloud storage offers advantages over HDFS, it necessitates a redesign of commit protocols to ensure reliable data handling.























































































