Downloaded 275 times


















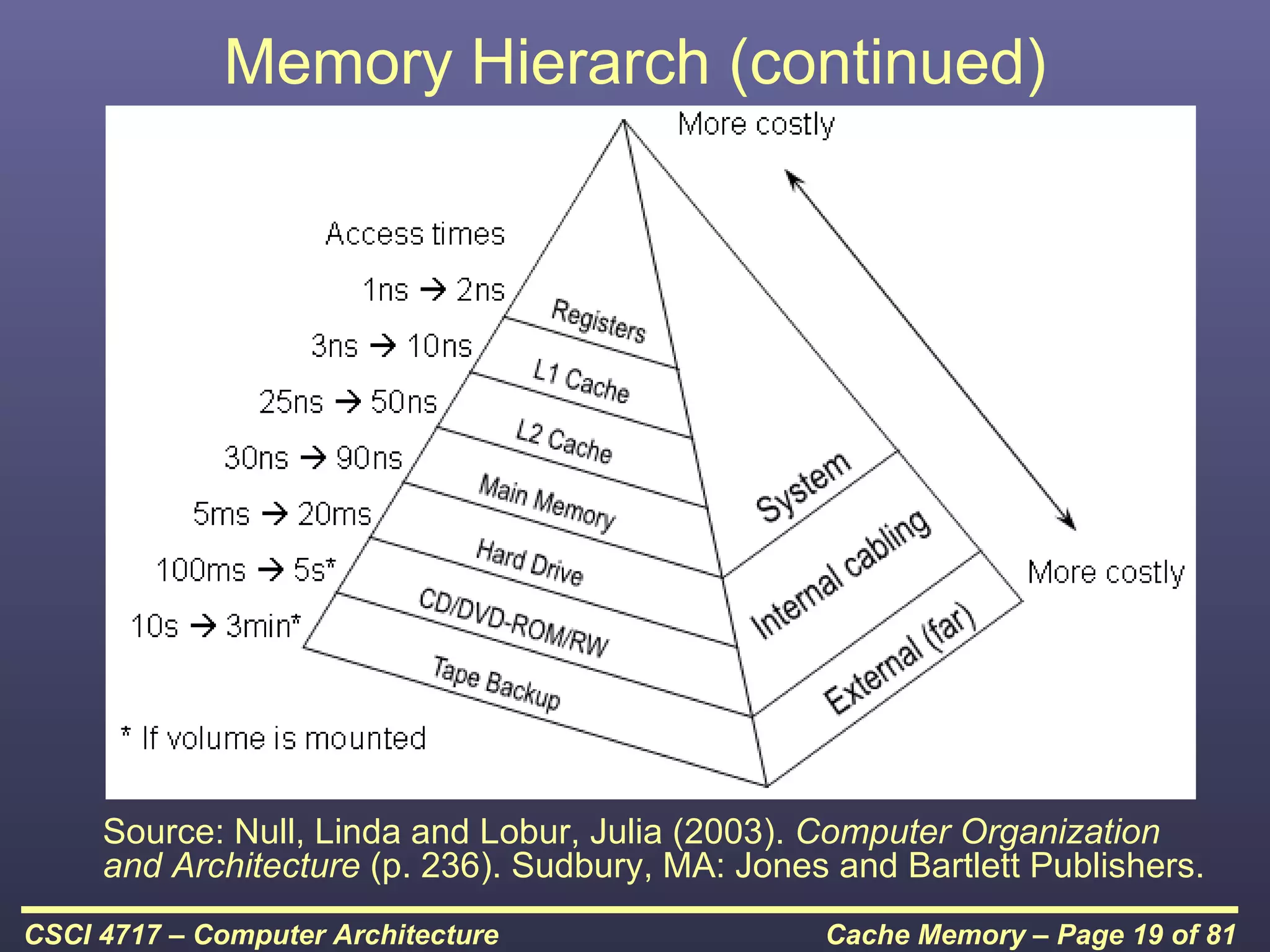





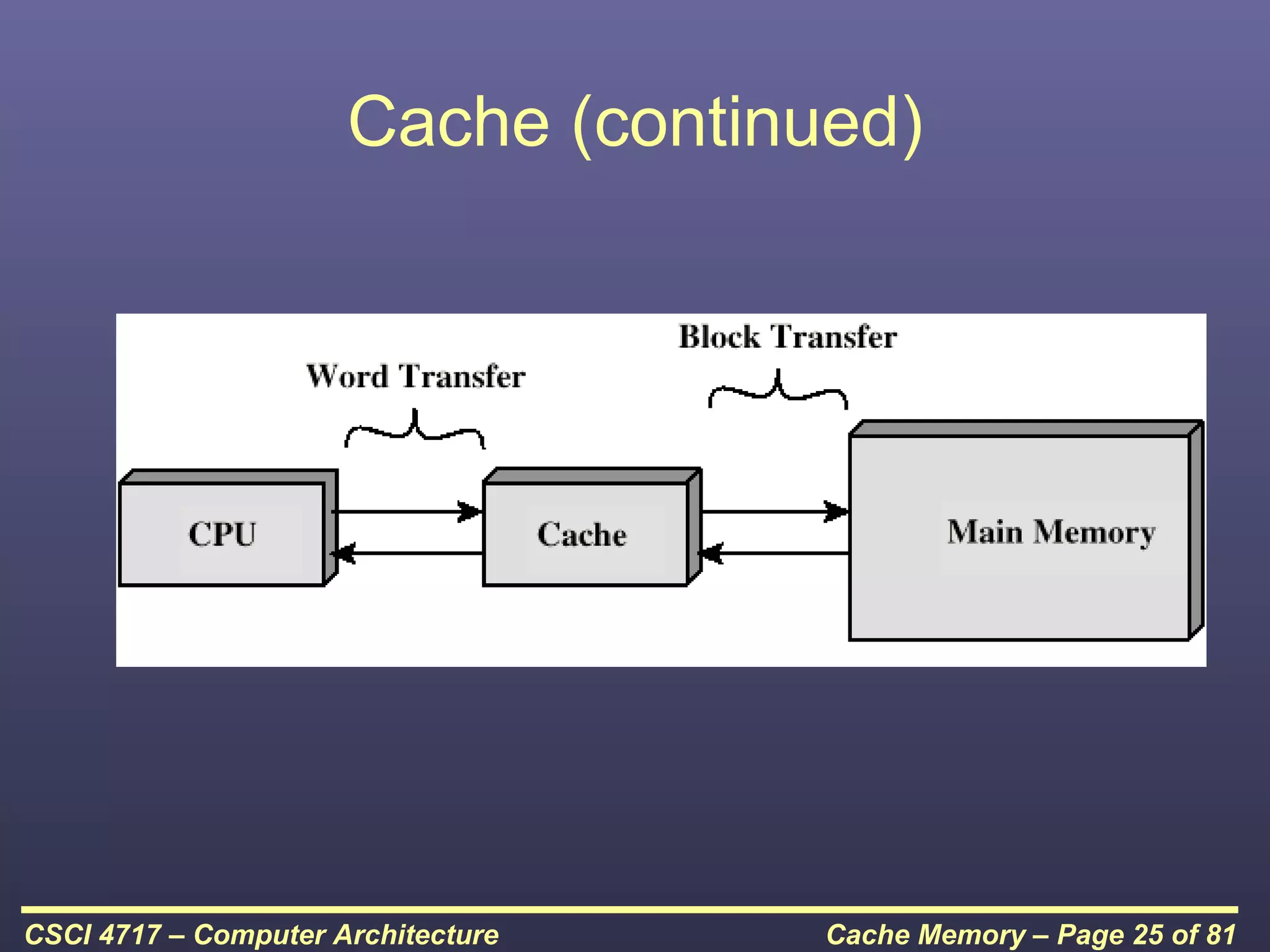




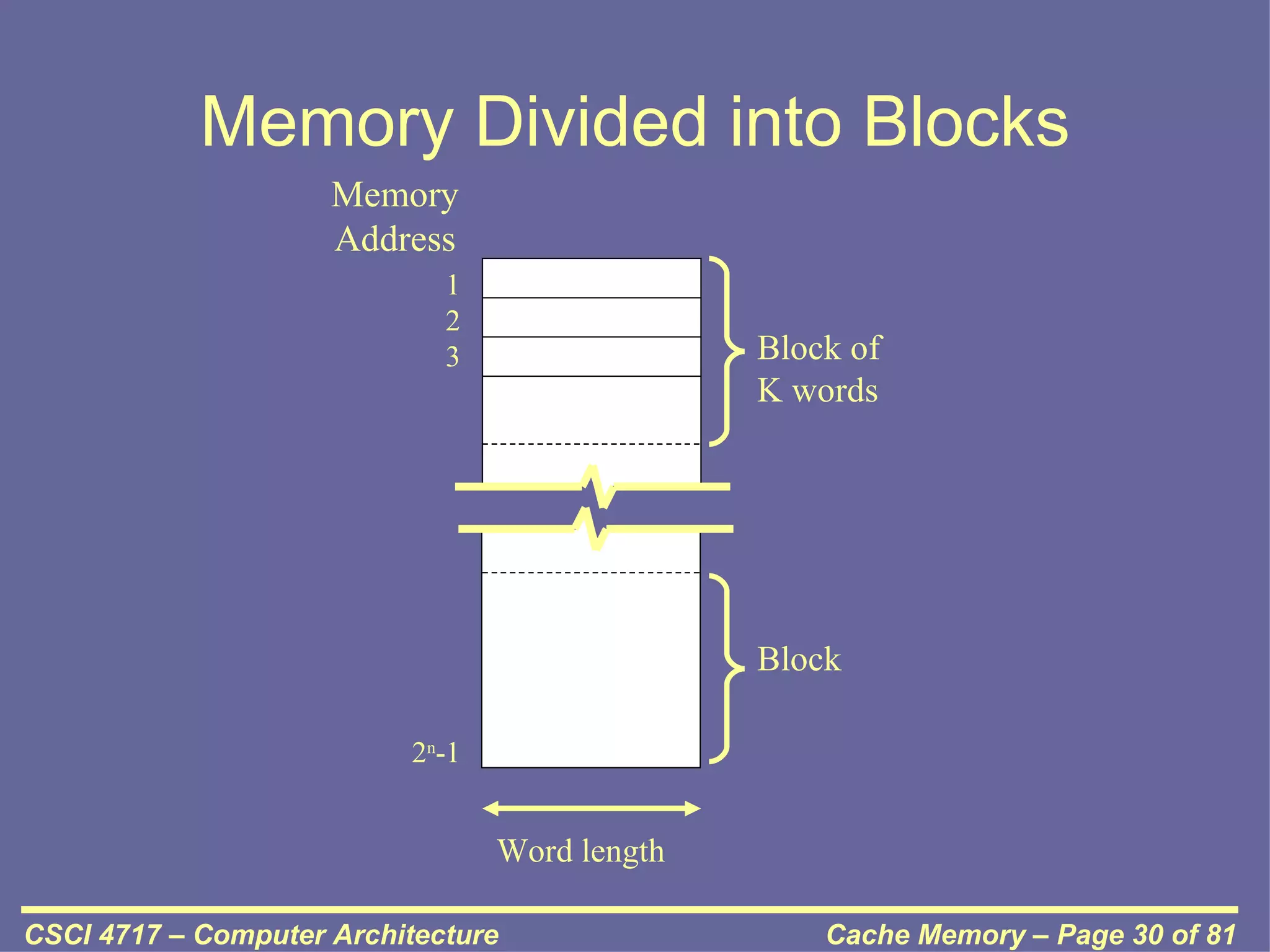


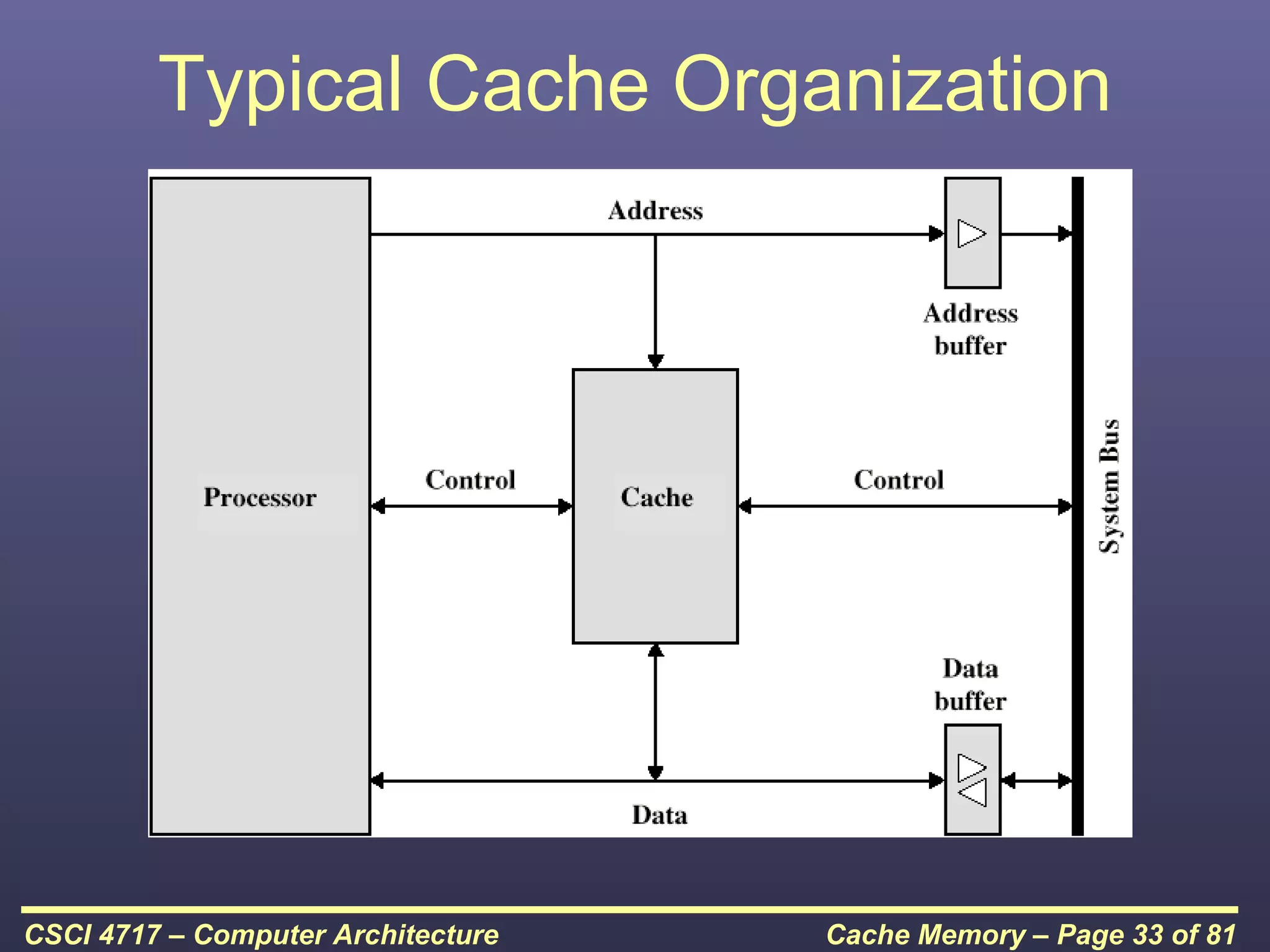







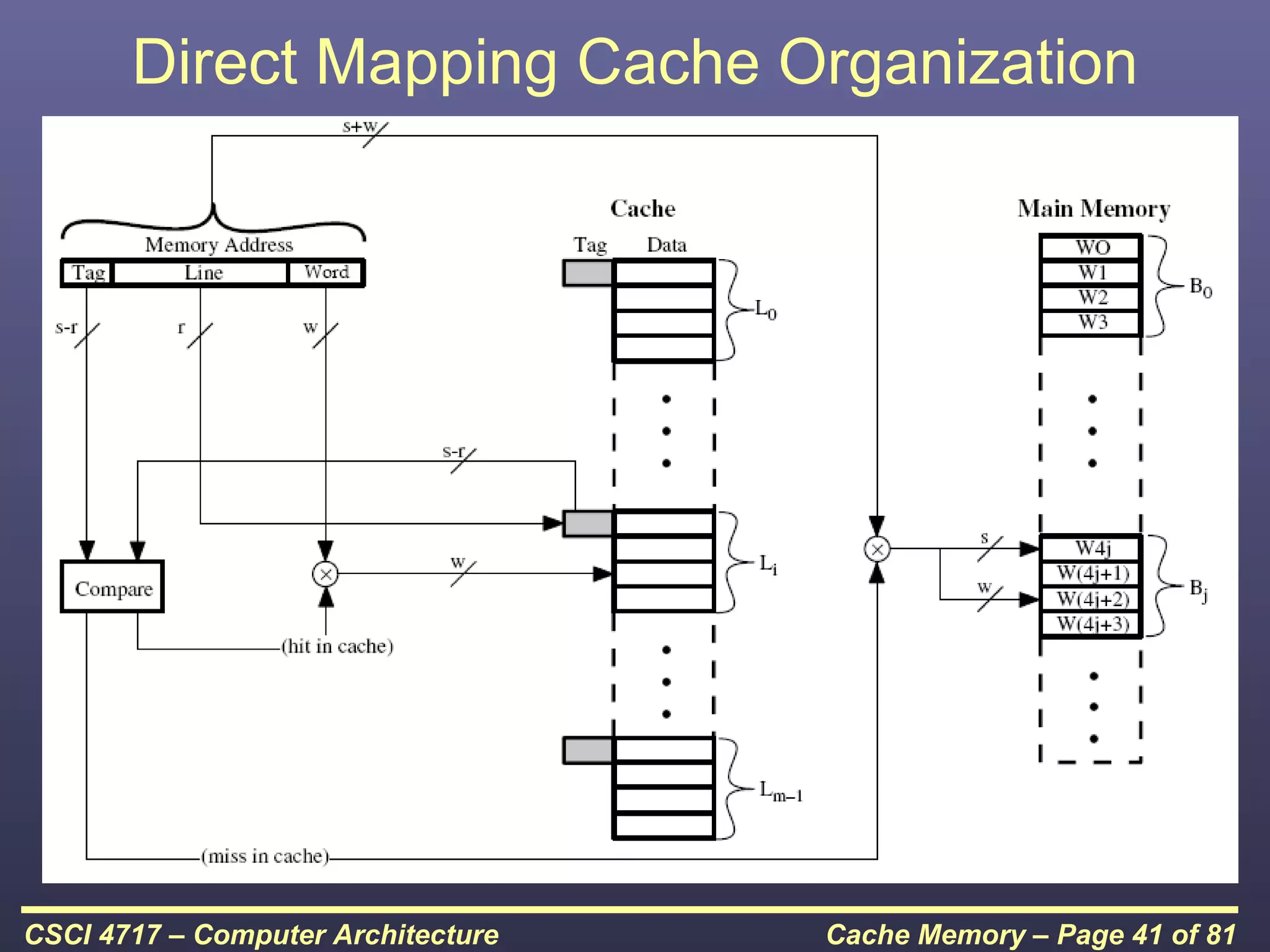
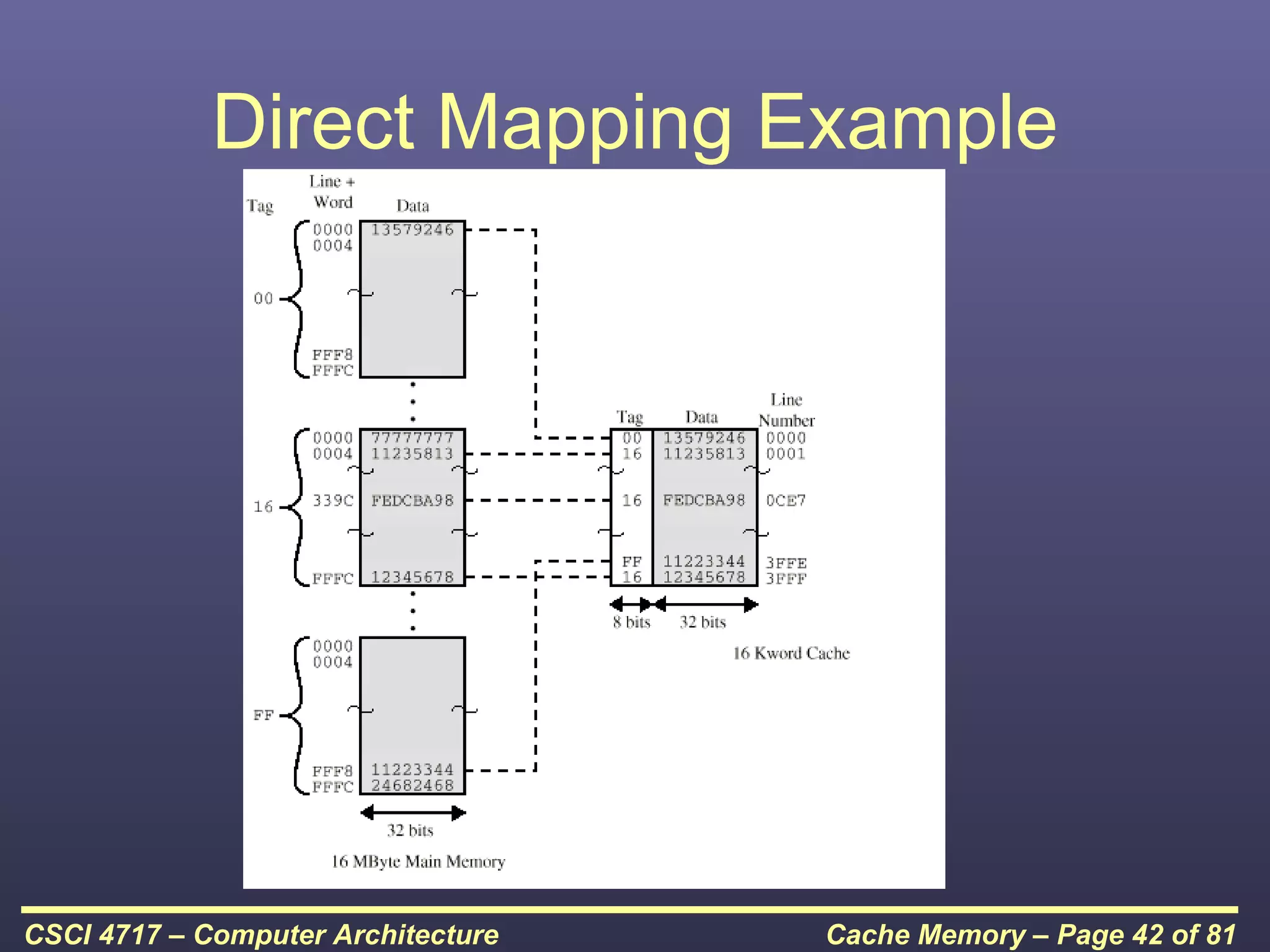






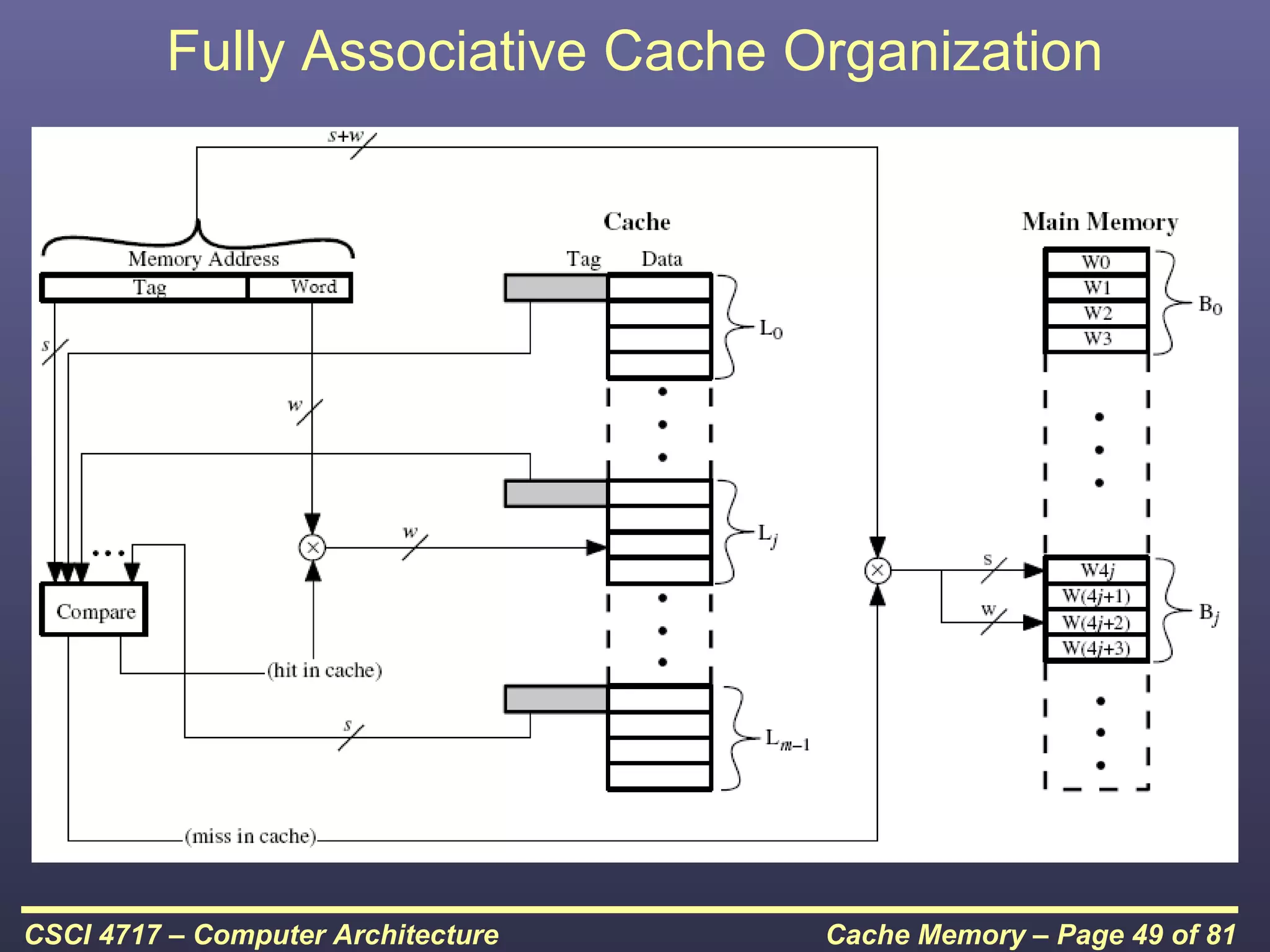
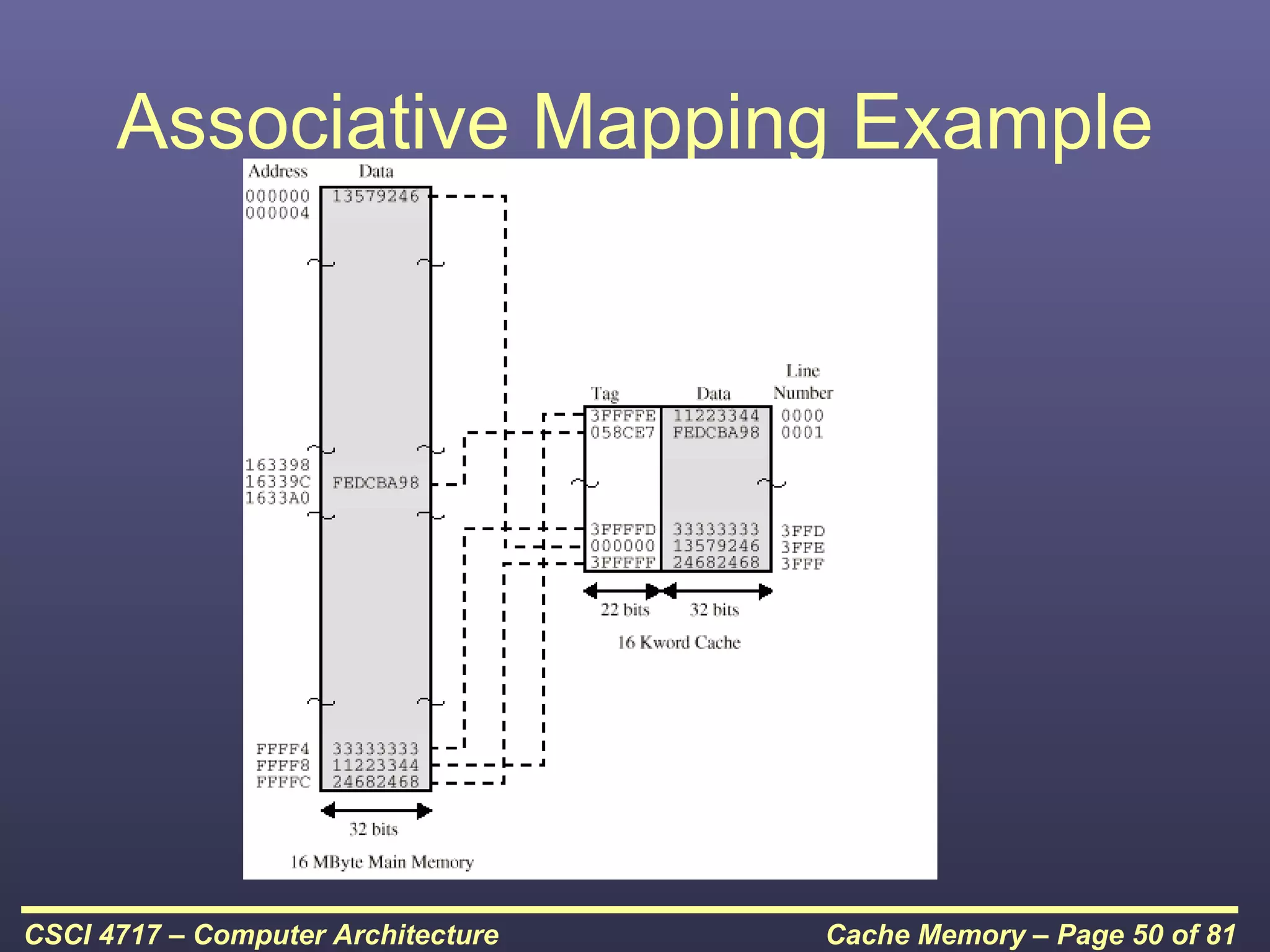




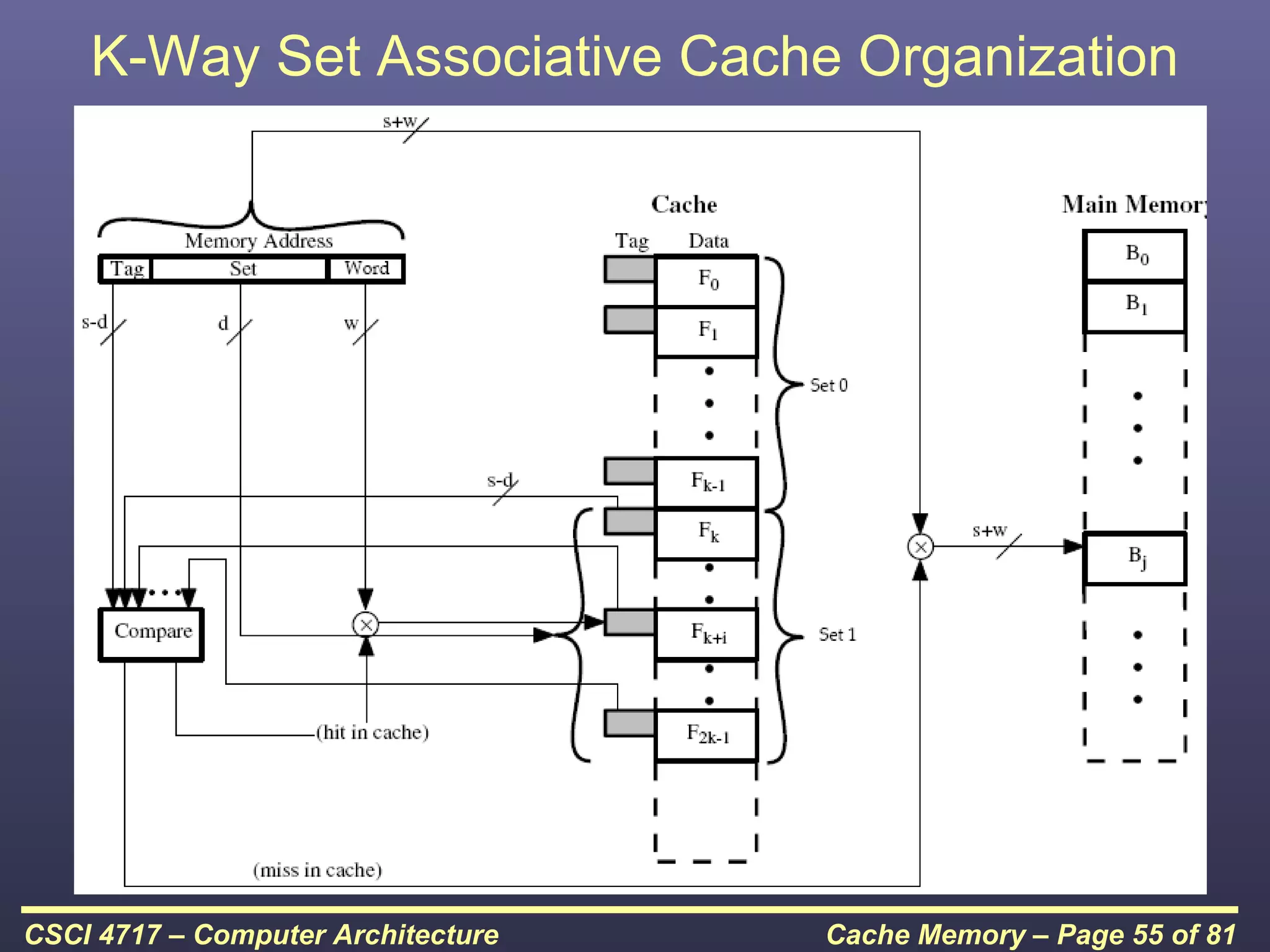


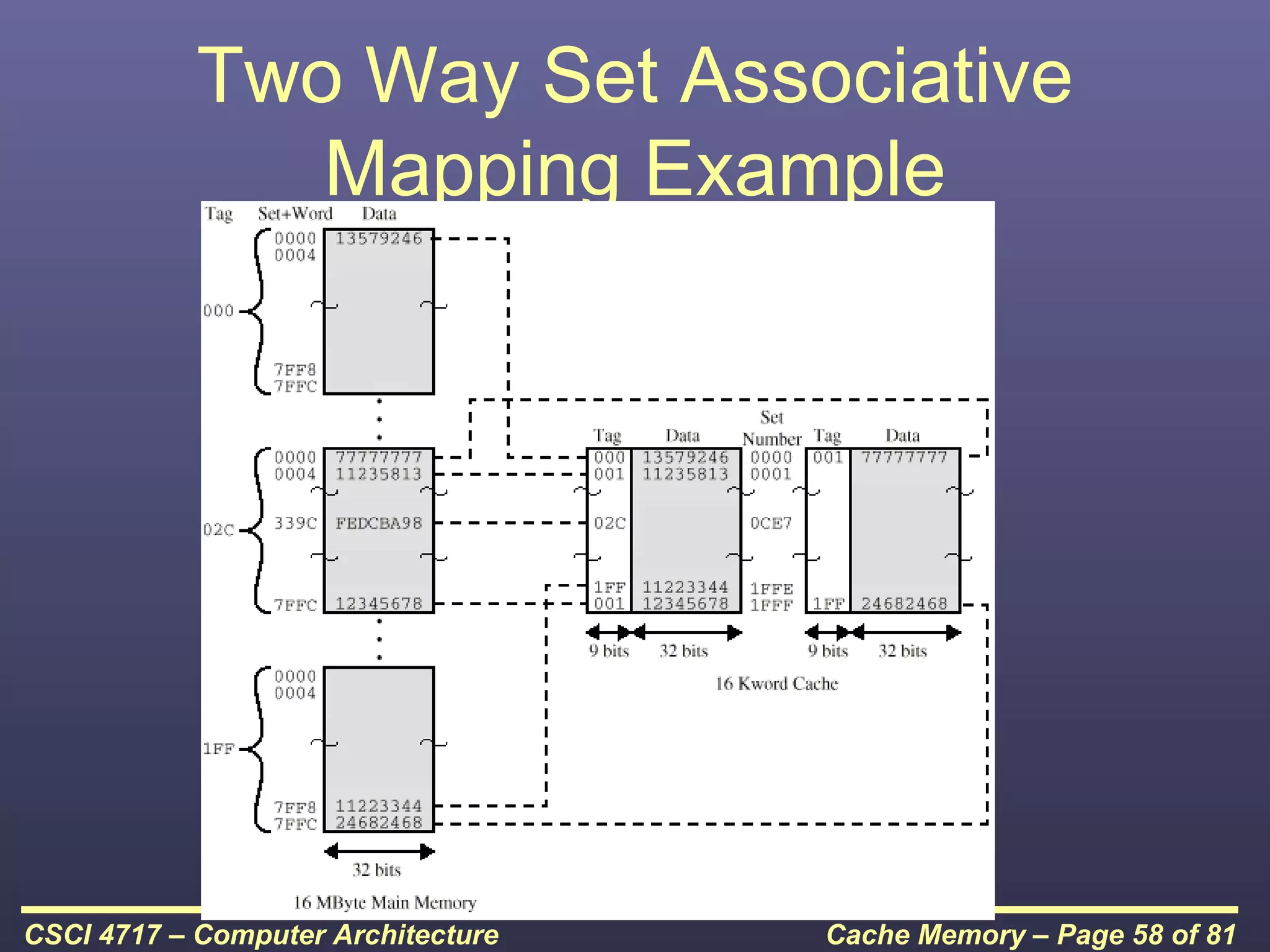















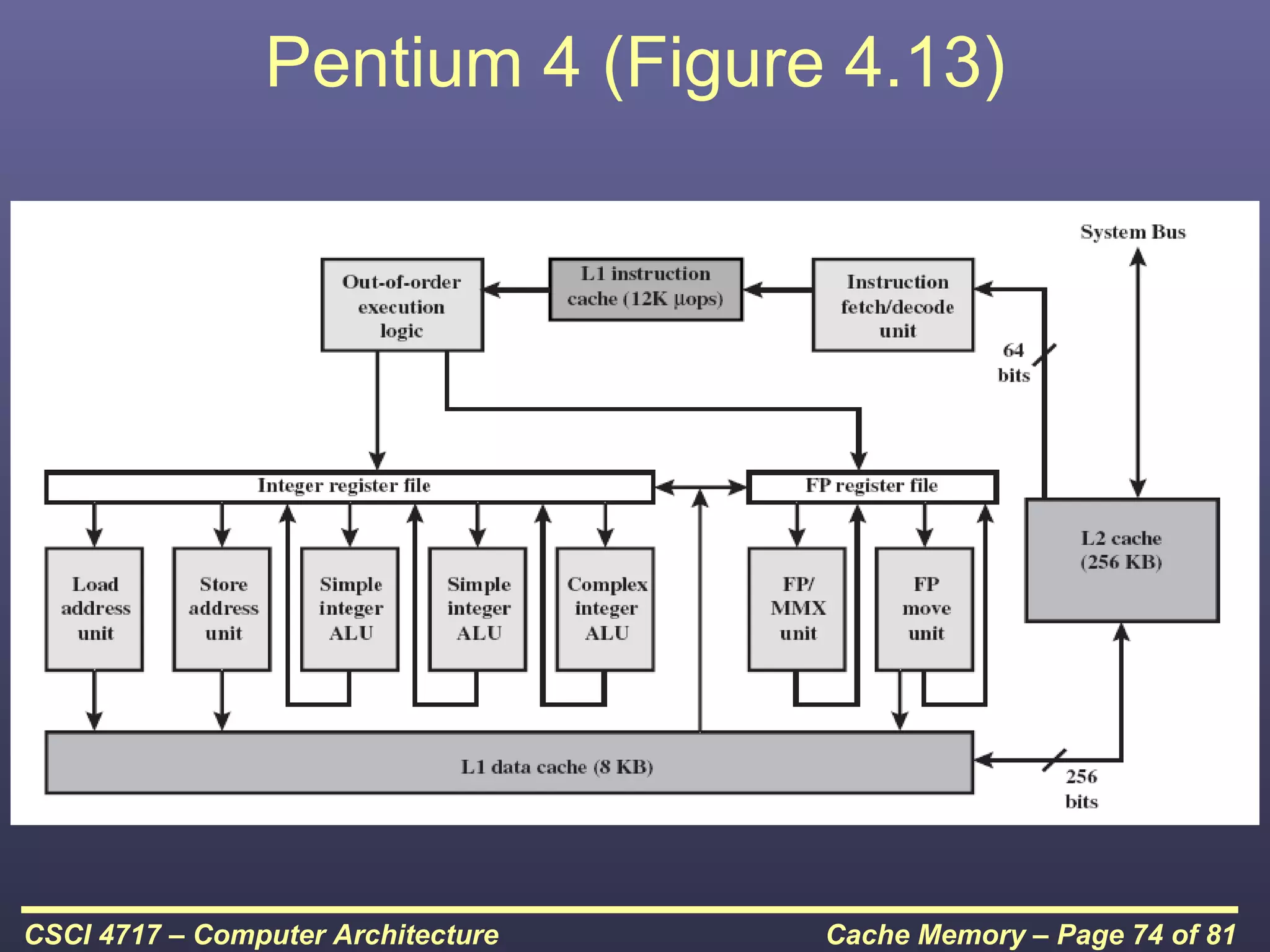





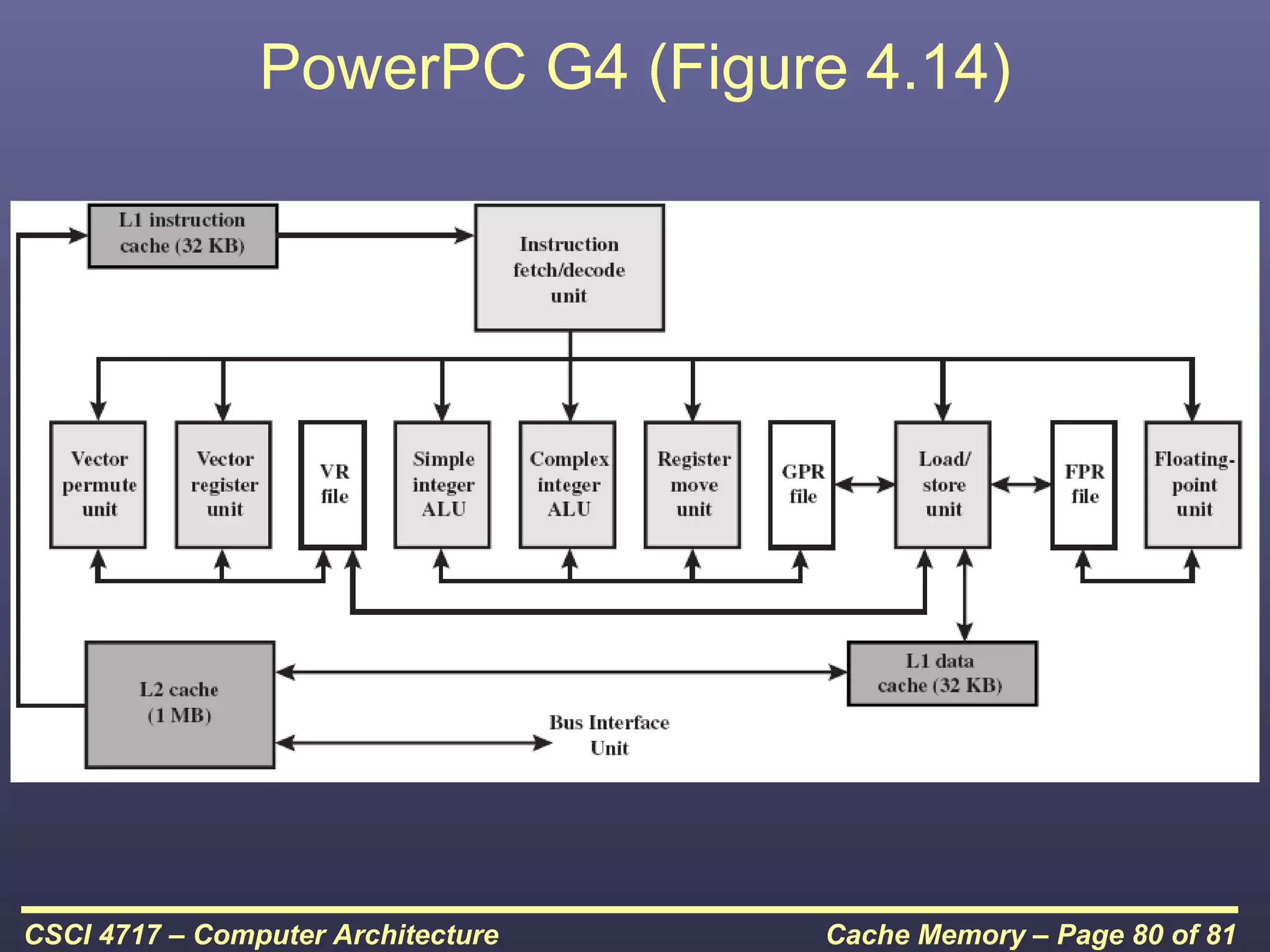
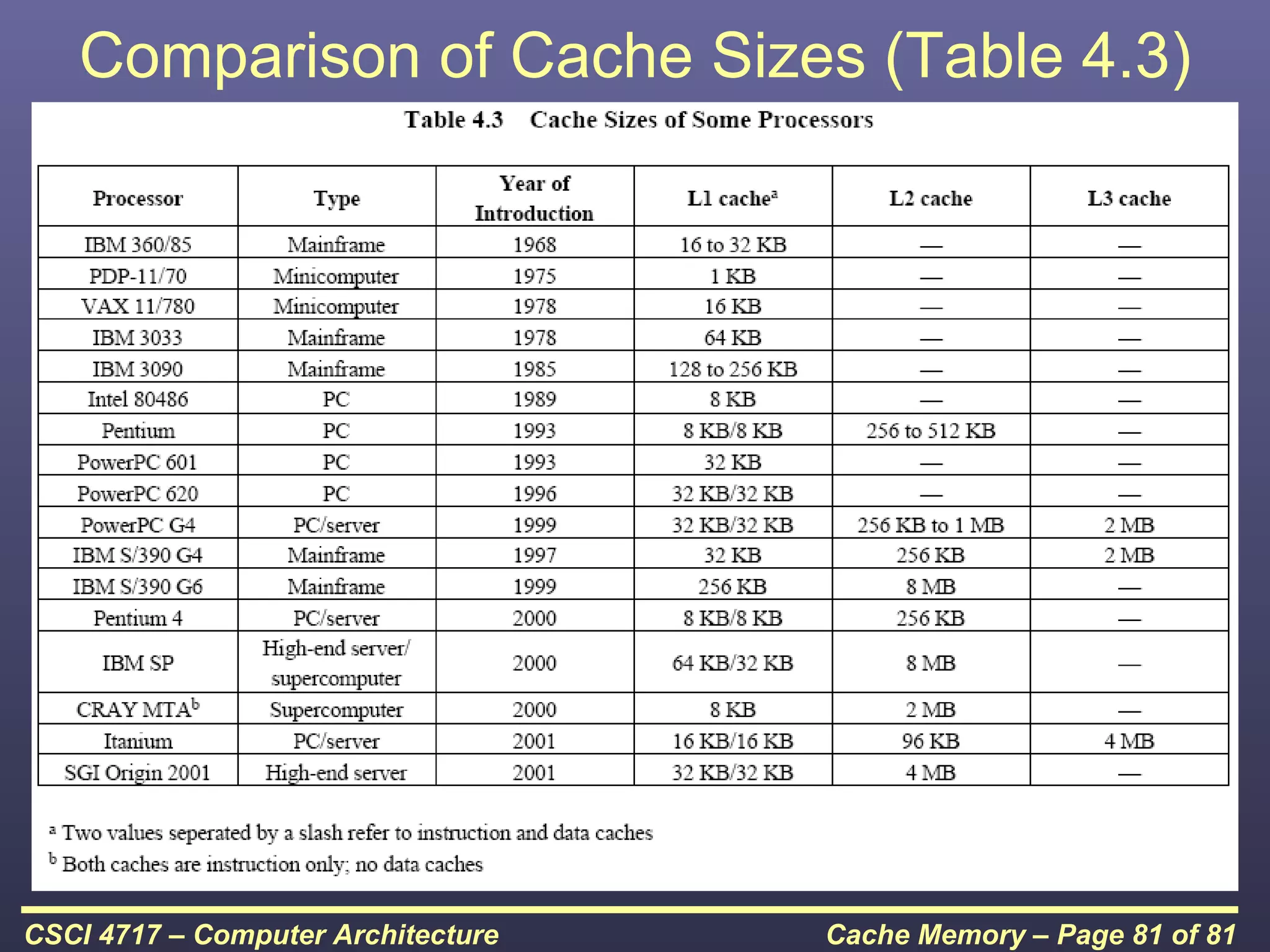

This document discusses cache memory and provides details on its characteristics and operation. It begins by describing the memory hierarchy and how cache fits within it. It then covers the key characteristics of cache memory, including that it is small, fast memory located close to the processor. The document explains how cache works by checking if requested data is present before accessing slower main memory if there is a miss. Overall, the document provides an overview of cache memory fundamentals.























































































