Download as PDF, PPTX
















![Reference
[1] Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning,
https://papers.nips.cc/paper/5421-deep-learning-for-real-time-atari-game-play-using-offline-monte-carlo-tr
ee-search-planning
[2] Monte Carlo Tree Search and AlphaGo, Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar,
http://www.yisongyue.com/courses/cs159/lectures/MCTS.pdf
[3] tobe: 如何学习蒙特卡罗树搜索(MCTS), https://zhuanlan.zhihu.com/p/30458774](https://image.slidesharecdn.com/deeplearningforreal-timeatarigameplayusingofflinemonte-carlotreesearchplanning-180801054710/85/Deep-Learning-for-Real-Time-Atari-Game-Play-Using-Offline-Monte-Carlo-Tree-Search-Planning-23-320.jpg)

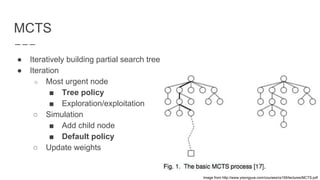
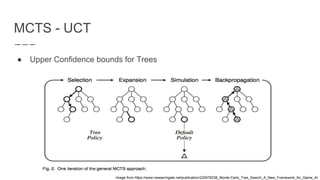
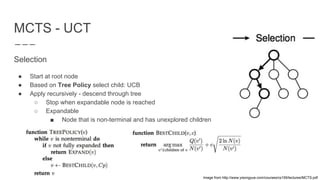
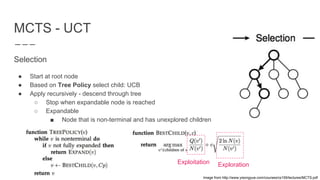
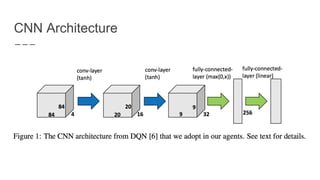
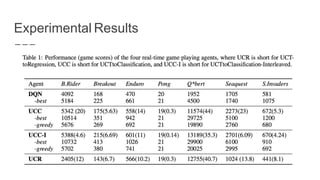
The document discusses a method combining deep learning and reinforcement learning for real-time Atari game play using offline Monte Carlo Tree Search (MCTS) planning. It explores how MCTS can generate training data for a deep-learning classifier to achieve state-of-the-art gaming performance. Three experimental approaches are outlined, including using MCTS data for both regression and classification in training a convolutional neural network.

























































