Downloaded 13 times





















![REFERENCES
1. Ian Goodfellow and Nicolas Papernot. Is attacking machine learning easier than defending it?
http://www.cleverhans.io/security/privacy/ml/2017/02/15/why-attacking-machine-learning-is-
easier-than-defending-it.html
2. Alexey Kurakin, Ian J. Goodfellow, Samy Bengio. Adversarial Examples in the physical world.
[Online] 2017. https://arxiv.org/pdf/1607.02533.pdf.
3. Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z. Berkay Celik,
Ananthram Swami. Practical Black-Box Attacks against Machine Learning. [Online] 2017.
https://arxiv.org/pdf/1602.02697.pdf.
4. Ian J. Goodfellow, Jonathon Shlens, Christian Szegedy. Explaining and harnessing adversarial
examples. [Online] 2015. https://arxiv.org/pdf/1412.6572.pdf.
5. Anish Athalye, Nicholas Carlini, David Wagner. Obfuscated Gradients Give a False Sense of
Security: Circumventing Defenses to Adversarial Examples. [Online] 2018.
https://arxiv.org/pdf/1802.00420v4.pdf.
6. Nicolas Papernot. Gradient Masking in Machine Learning.
https://seclab.stanford.edu/AdvML2017/slides/17-09-aro-aml.pdf](https://image.slidesharecdn.com/neuralnetworksprojectpresentation-190530081611/75/Black-Box-attacks-against-Neural-Networks-technical-project-presentation-25-2048.jpg)


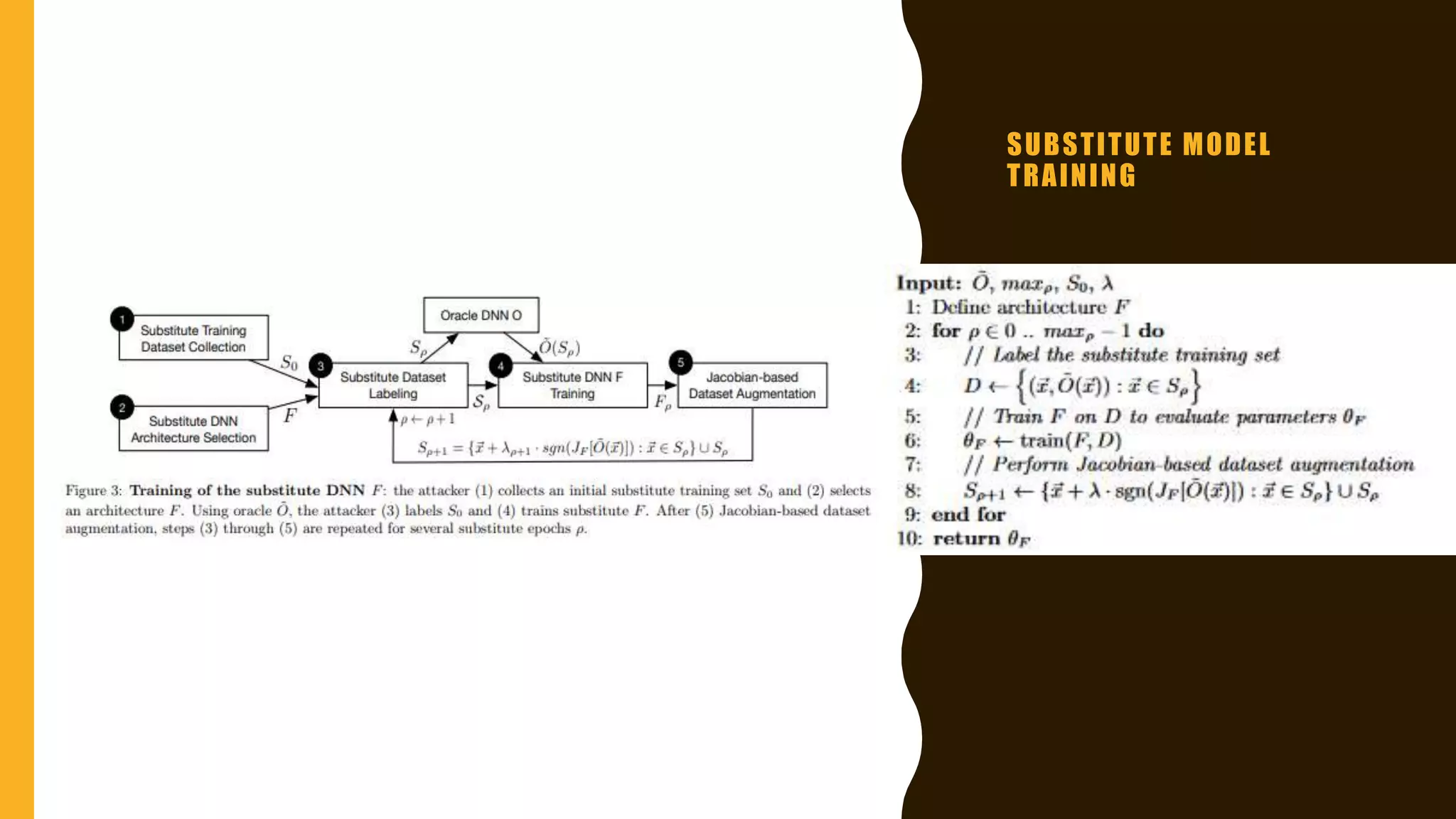
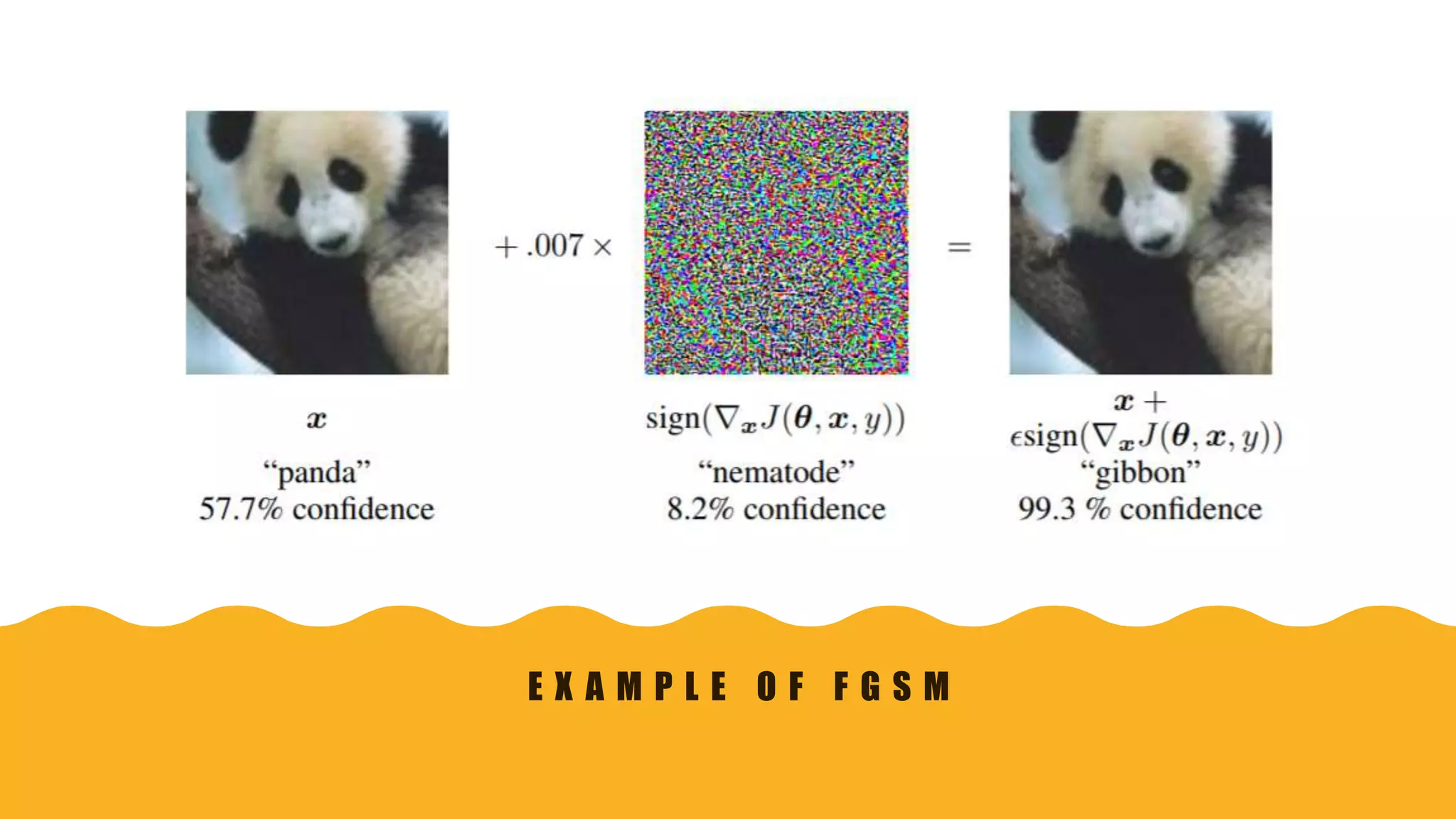
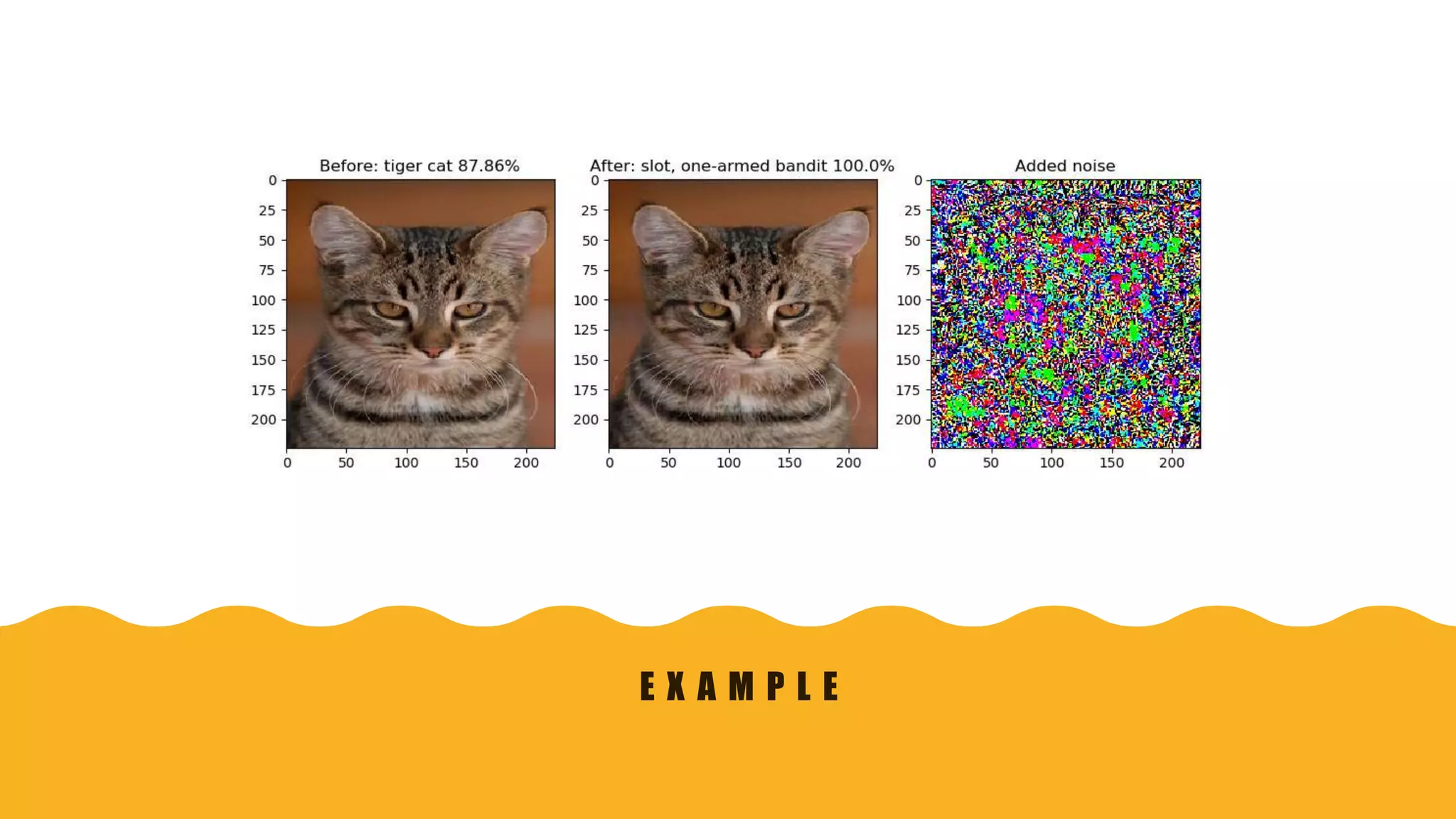
This document presents practical strategies for executing black-box attacks against deep neural networks (DNNs), where the attacker can only observe the output of the classifier without knowledge of its internal architecture. The process involves training a substitute model using synthetic datasets generated from the DNN's outputs, which then allows for the crafting of adversarial samples aimed at causing misclassifications. The document also discusses various attack methodologies, such as the Fast Gradient Sign Method and the Jacobian-based Saliency Map Attack, and addresses potential defense strategies.























![[Pgday.Seoul 2017] 8. PostgreSQL 10 새기능 소개 - 김상기](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-seoul-2017-pg10-new-features-171106041845-thumbnail.jpg?width=640&height=640&fit=bounds)


























































