Download to read offline





![class Foo0(models.Model):
_name = 'foo'
...
class Bar0(models.AbstractModel):
_name = 'bar'
...
class Foo1(models.Model):
_name = 'foo'
_inherit = ['bar', 'foo']
...
class bar(Bar0, Base):
_name = 'bar'
class foo(Foo1, bar, Foo0, Base):
_name = 'foo'
Model definitions Model classes](https://image.slidesharecdn.com/anin-depthjourneyintoodoosorm-201102092141/85/An-in-Depth-Journey-into-Odoo-s-ORM-6-320.jpg)











![Fields to compute (stored)
def __get__(self, record, owner):
if record.id in tocompute.get(self, ()):
self.compute_value(record.browse(tocompute[self]))
try:
return record.env.cache.get(record, self)
except CacheMiss:
if self.store:
record._in_cache_without(self)._fetch(self)
elif self.compute:
self.compute_value(record._in_cache_without(self))
else:
...
return record.env.cache.get(record, self)](https://image.slidesharecdn.com/anin-depthjourneyintoodoosorm-201102092141/85/An-in-Depth-Journey-into-Odoo-s-ORM-18-320.jpg)
![Fields to compute (non-stored)
def __get__(self, record, owner):
if record.id in tocompute.get(self, ()):
self.compute_value(record.browse(tocompute[self]))
try:
return record.env.cache.get(record, self)
except CacheMiss:
if self.store:
record._in_cache_without(self)._fetch(self)
elif self.compute:
self.compute_value(record._in_cache_without(self))
else:
...
return record.env.cache.get(record, self)](https://image.slidesharecdn.com/anin-depthjourneyintoodoosorm-201102092141/85/An-in-Depth-Journey-into-Odoo-s-ORM-19-320.jpg)


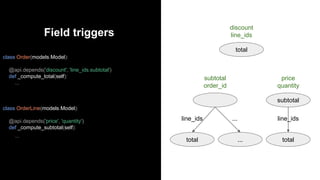
![Fields triggers
def modified(self, fnames):
tree = merge(
field_triggers[self._fields[fname]]
for fname in fnames
)
self._modified_triggers(tree)
def _modified_triggers(self, tree):
if self:
for field in tree.root:
mark_to_compute_or_invalidate(field, self)
for field, subtree in tree.children:
records = inverse(field, self)
records._modified_triggers(subtree)](https://image.slidesharecdn.com/anin-depthjourneyintoodoosorm-201102092141/85/An-in-Depth-Journey-into-Odoo-s-ORM-23-320.jpg)



The document describes various data structures and processes used in an ORM (object-relational mapper) system. The key points are: 1. The registry maps model names to model classes and holds metadata. It returns model class instances from browse() which reflect model definitions. 2. The record cache stores field values for quick access and is prefetched and invalidated based on changes. 3. Fields to write collects updates and flushes multiple records with the same updates in a single SQL query to minimize writes. 4. Fields to compute delays computations by tracking which records need recomputation and coordinating with the cache and writes. 5. Field triggers determine what to recompute or invalidate in the























































































