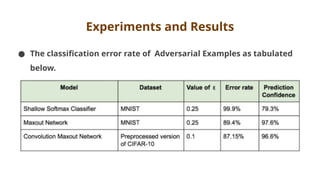
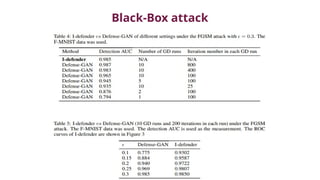
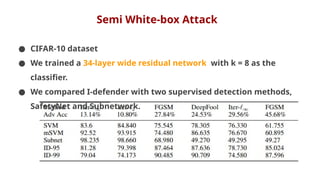
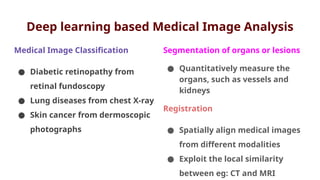
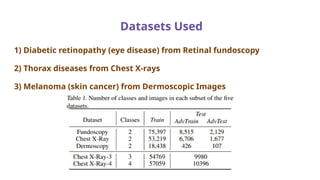
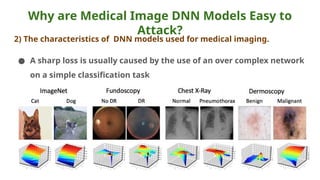
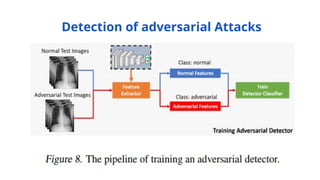
The document discusses various aspects of adversarial examples in machine learning, focusing on their creation, impact on neural networks, and methods for defense, including adversarial training and Gaussian mixture models for detection. It highlights the increased susceptibility of deep learning models, especially in medical image analysis, to adversarial attacks due to complex textures and overparameterization, while also introducing techniques to maintain privacy through differential privacy approaches. The findings indicate that adversarial attacks can be easily generated and detected, raising concerns about the robustness of models used in critical applications like medical diagnostics.












































![DNN Models
● We use ImageNet and ResNet-50 as the base network.
● Top layer is replaced by a new dense layer of 128 neurons, followed by a
dropout layer of rate 0.2, and K neuron dense layer for classification.
● The networks are trained for 300 epochs using stochastic gradient
descent (SGD) optimizer with initial learning rate 10 4
−
, momentum 0.9.
● All images are center-cropped to the size 224×224×3 and normalized to
the range of [ 1, 1].
−
● Simple data augmentations including random rotations, width/height
shift and horizontal flip are used.](https://image.slidesharecdn.com/majorprojectppt1-240906051827-7186d832/85/Fast-Gradient-Sign-Method-FGSM-___-pptx-51-320.jpg)



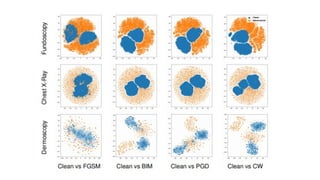
![Detection of Medical Image Attacks
Adversarial detection experiments
on 2-class datasets
● KD
● LID
● Qfeat-quantized deep features
● Dfeat- Deep features
● All detection features are extracted
in mini-batches of size 100
● The detection features are then
normalized to [0,1].
● Logistic regression classifier as the
detector for KD and LID.
● Random forests classifier as the
detector for the deep features.
● SVM classifier for quantized deep](https://image.slidesharecdn.com/majorprojectppt1-240906051827-7186d832/85/Fast-Gradient-Sign-Method-FGSM-___-pptx-56-320.jpg)







![Background
Differential Privacy (DF) :
● Differential privacy (DF) is a concept that reduces the likelihood of
identifying a record within a large database
● DF basically relies on exponential or Laplace mechanism to perturb
data.
● Pr[ℛ(𝐷1) ]
∈ ≤
𝑆 𝑒𝜖
Pr[ℛ(𝐷2) ]
∈ 𝑆 : level of privacy budget
𝜖
● 𝜖 is inversely proportional to privacy protection](https://image.slidesharecdn.com/majorprojectppt1-240906051827-7186d832/85/Fast-Gradient-Sign-Method-FGSM-___-pptx-66-320.jpg)






![Emotion Recognition Dataset
● Emotion dataset has 7 classes (i.e. anger, disgust, fear, happy, sad,
surprise, neutral)
● In the non-private model 83.7% test accuracy was reached.
● We introduce moderate noise into CNN model through our bound
𝜖
E as: E = [0.5 5], 82.8% testing prediction accuracy was observed.
∶
● We increase the noise by setting E = [0.1 1], the accuracy was at
∶
81.5%.
● The results indicate a close accuracy between private and the non-
private model.](https://image.slidesharecdn.com/majorprojectppt1-240906051827-7186d832/85/Fast-Gradient-Sign-Method-FGSM-___-pptx-73-320.jpg)
![MNIST Dataset
● MNIST is a well-known dataset with training accuracy of
99.7% .
● We set our bound E to: E = [0.5 5] for moderate noise,
𝜖 ∶
and our model achieved an accuracy of 98.6%,
● When we introduced much noise as E = [0.1 1], our CNN
∶
model recorded an accuracy of 98.1%.](https://image.slidesharecdn.com/majorprojectppt1-240906051827-7186d832/85/Fast-Gradient-Sign-Method-FGSM-___-pptx-74-320.jpg)















![[SOTIF US Conference] Introduction to Safe ML](https://cdn.slidesharecdn.com/ss_thumbnails/20190930crdcccsafemlv1-190930165846-thumbnail.jpg?width=640&height=640&fit=bounds)
































