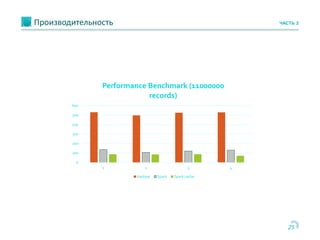
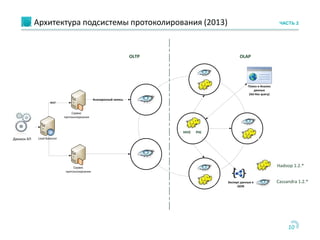
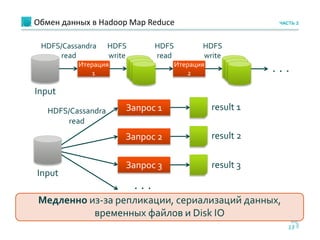
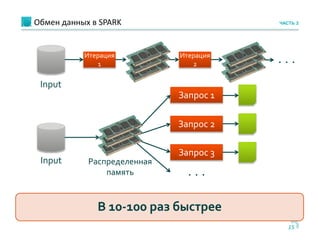
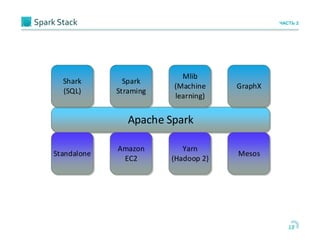
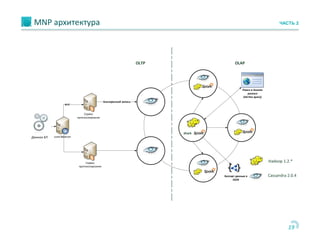
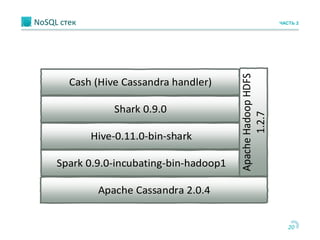
Документ обсуждает использование Apache Cassandra и Apache Spark для быстрой аналитики данных в реальном времени, особенно в контексте проектов, таких как портирование мобильных номеров. Он описывает архитектуру систем, задачи и бизнес-процессы, а также технологии, позволяющие эффективно обрабатывать большие объемы данных. Основное внимание уделяется преимуществам решения Cassandra по сравнению с Hadoop, включая масштабируемость и производительность.












![23
Пример ЧАСТЬ 2
shark> CREATE EXTERNAL TABLE mnp.audit(processId int, pname string, pcategory string, penddate date, pinstance
string, pevent string)
STORED BY 'org.apache.hadoop.hive.cassandra.cql.CqlStorageHandler'
WITH SERDEPROPERTIES ("cql.primarykey" = “processid", "comment"="check", "read_repair_chance" = "0.2",
"dclocal_read_repair_chance" = "0.14", "gc_grace_seconds" = "989898", "bloom_filter_fp_chance" = "0.2",
"compaction" = "{'class' : 'LeveledCompactionStrategy'}", "replicate_on_write" = "false", "caching" = "all");
shark> select count(*) from audit;
185.022: [Full GC 106345K->24340K(1013632K), 0.2817830 secs]
189.722: [Full GC 228461K->30033K(1013632K), 0.3228080 secs]
OK
4870000
Time taken: 37.106 seconds
shark> select pcategory, count(*) from audit group by pcategory;
185.022: [Full GC 106345K->24340K(2013632K), 0.3017930 secs]
189.722: [Full GC 228461K->30033K(1993632K), 0.4558780 secs]
OK
portin 1000300
Portout 2001000
Pgov 1710003
Time taken: 136.199 seconds](https://image.slidesharecdn.com/moscowcassandrameetup-atc2-140520012628-phpapp01/85/3rd-Moscow-cassandra-meetup-Fast-In-memory-Analytics-Over-Cassandra-Data-22-320.jpg)
![24
Пример (Таблица cache) ЧАСТЬ 2
shark> CREATE TABLE mnp.audit_cache TBLPROPERTIES ("shark.cache" = "true") AS SELECT * FROM mnp.audit;
shark> select pcategory, count(*) from audit-cache group by pcategory_cache;
135.022: [Full GC 106345K->24340K(2013632K), 0.2118930 secs]
129.722: [Full GC 228461K->30033K(1993632K), 0.3368880 secs]
OK
portin 1000300
Portout 2001000
Pgov 1710003
Time taken: 46.019 seconds](https://image.slidesharecdn.com/moscowcassandrameetup-atc2-140520012628-phpapp01/85/3rd-Moscow-cassandra-meetup-Fast-In-memory-Analytics-Over-Cassandra-Data-23-320.jpg)