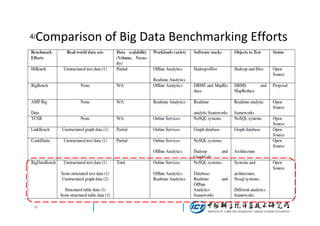
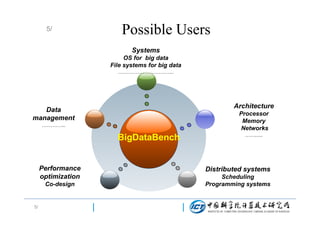
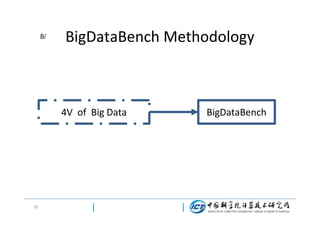
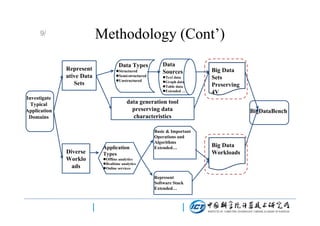
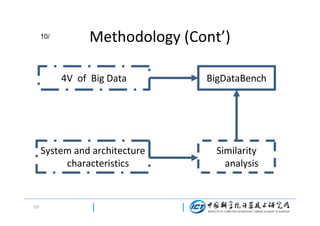
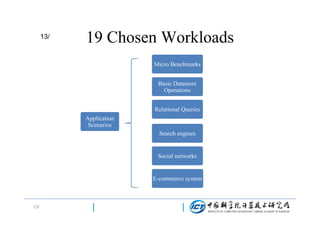
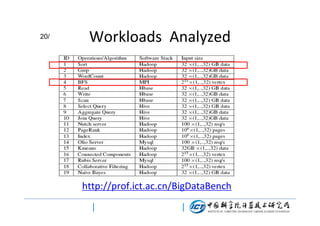
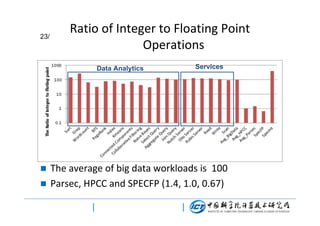
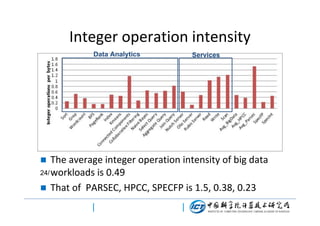
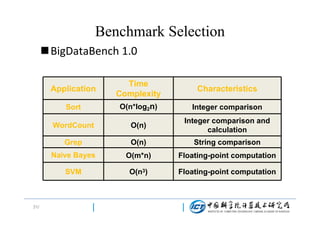
This document discusses BigDataBench, an open source project for big data benchmarking. BigDataBench includes six real-world data sets and 19 workloads that cover common big data applications and preserve the four V's of big data. The workloads were chosen to represent typical application domains like search engines, social networks, and e-commerce. BigDataBench aims to provide a standardized benchmark for evaluating big data systems, architectures, and software stacks. It has been used in several case studies for workload characterization and evaluating the performance and energy efficiency of different hardware platforms for big data workloads.













![Experimental Platforms
Hadoop Cluster
Information
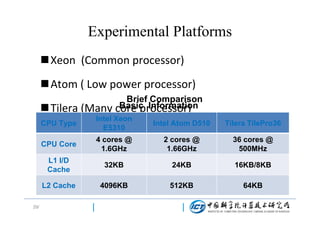
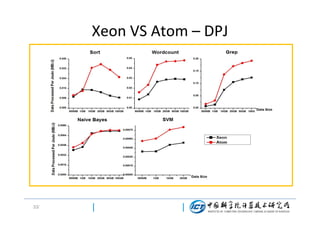
Xeon VS Atom
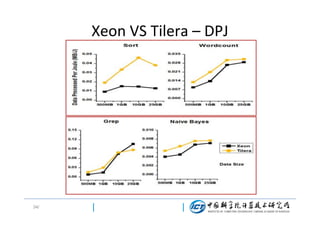
Xeon VS Tilera
[ 1 Xeon master+7
Comprison
[1 Xeon master+7 Xeon
Xeon slaves ] VS [ 1
(the same logical
slaves] VS [ 1 Xeon
Atom master +7 Atom
core number)
master +1 Tilera slave]
slaves]
Hadoop setting
30/
Following the guidance on Hadoop official
website](https://image.slidesharecdn.com/bigdatabenchbenchmarkingbigdatasystems-131216041820-phpapp01/85/Big-databench-benchmarking-big-data-systems-30-320.jpg)











































































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








