Download to read offline























![TPCx-IoT
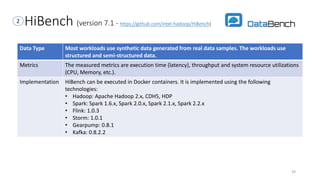
Description The TPC Benchmark IoT (TPCx-IoT) benchmark workload is designed based on Yahoo
Cloud Serving Benchmark (YCSB). It is not comparable to YCSB due to significant changes.
The TPCx-IoT workloads consists of data ingestion and concurrent queries simulating
workloads on typical IoT Gateway systems. The dataset represents data from sensors from
electric power station(s).
Domain TPCx-IoT was developed to provide the industry with an objective measure of the hardware,
operating system, data storage and data management systems for IoT Gateway systems. The
TPCx-IoT benchmark models a continuous system availability of 24 hours a day, 7 days a
week.
Workload The System Under Test (SUT) must run a data management platform that is commercially
available and data must be persisted in a non-volatile durable media with a minimum of
two-way replication. The workload represents data inject into the SUT with analytics
queries in the background. The analytic queries retrieve the readings of a randomly
selected sensor for two 30 second time intervals, TI1 and TI2. The first time interval TI1 is
defined between the timestamp the query was started Ts and the timestamp 5 seconds
prior to TS , i.e. TI1 =[TS -5,TS]. The second time interval is a randomly selected 5 seconds
time interval TI2 within the 1800 seconds time interval prior to the start of the first query, TS
-5. If TS <=1810, prior to the start of the first query, TS -5.
44
1](https://image.slidesharecdn.com/berre-databench-10-12-18-ieee-benchmarking1-190409090740/85/Benchmarking-for-Big-Data-Applications-with-the-DataBench-Framework-Arne-Berre-BPOD-2018-10-12-2018-43-320.jpg)











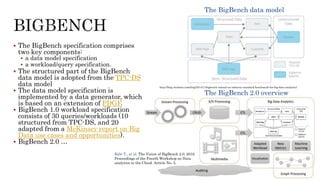




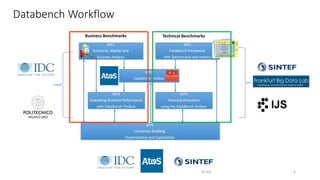
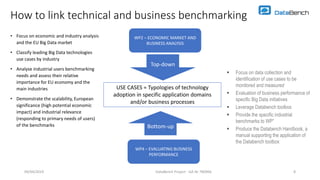
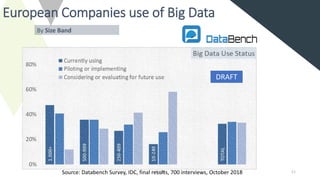
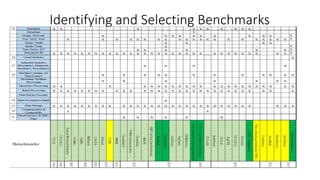
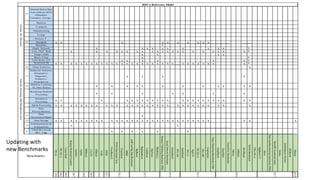
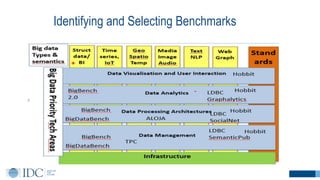
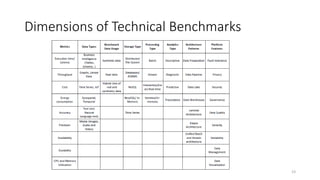
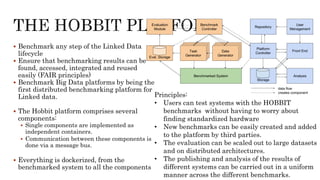
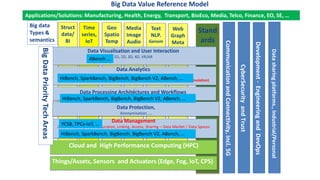
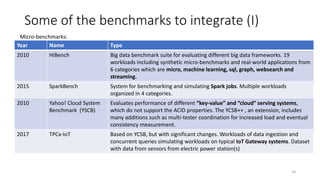
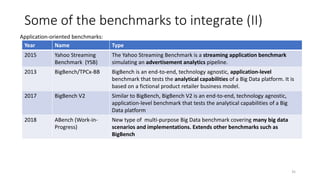
The document discusses benchmarking for big data applications using the DataBench framework. It provides an overview of business and technical benchmarking, describes how DataBench links the two through its workflow and toolbox, and outlines some early results from DataBench's business user survey. It also discusses identifying relevant benchmarks based on the BDVA reference model and introduces some benchmarks that could be integrated into DataBench's toolbox, including HiBench, SparkBench, and YCSB.




































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)








